关系抽取之远程监督算法:别再跟我提知识图谱(上篇)
来自:叫我NLPer
一 :今日吐槽
2018年12月,我在天河区的不求有功但求无过大厦九楼,向窗外伸出右手,仿佛远处的小蛮腰就在我掌心。
秋雨潇歇,朔风猎猎,而我心无半点凉意。
"
自然语言处理和知识图谱作为认知智能的关键技术,双剑合璧,正成为智能金融领域的新浪潮!
"
作为一个追泡沫的人,我平静的表情下,内心已经暗潮涌动。
"
人工智能的世界很精彩,我想去看看!
"
2019年7月,我坐在浦东新区的给梦想可能广场十九楼,如愿开始构建知识图谱。
独当一面,出道即巅峰。
一个月后,不用任何模型,无需任何代码,我就把知识图谱构建好了,交给了匡老师。
什么BiLSTM+CRF实体识别,什么PCNN关系抽取,统统不需要!
Handwork is all you need!
二:内容预告
信息抽取是自然语言处理中非常重要的一块内容,包括实体抽取(命名实体识别,Named Entity Recognition)、关系抽取(Relation Extraction)和事件抽取(Event Extraction)。
信息抽取(Information Extraction)从海量非结构化文本中抽取结构化的有用信息,是知识图谱、信息检索乃至问答系统的一项基本技术。
其中,关系抽取属于自然语言理解(NLU)的范畴,也是构建和扩展知识图谱的一种方法。
本文梳理远程监督关系抽取算法的发展脉络,首先介绍远程监督+传统机器学习做关系抽取的基本假设和一般思路,再介绍后续的优化思路:
从人工构造特征到用神经网络自动学习特征,降低人工抽取特征带来的误差
从远程监督的强假设到多实例学习的弱假设,缓解句子的错误标注问题
从多实例学习到句子级别的注意力机制,缓解多实例学习遗漏大量信息的问题
本文关注以下内容:
关系抽取简介
远程监督关系抽取算法的滥觞
多实例学习和分段最大池化
句子级别的注意力机制
三:关系抽取简介
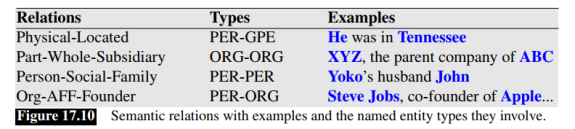
关系抽取理解起来也比较简单,比如下面图片中的第一句话:
He was in Tennessee
首先做命名实体识别,识别出He(PER)和Tennessee(GPE)两个实体,然后找出两个实体之间的关系:Physical-Located,最后把抽取出来的关系表示为三元组的形式:(HePER, Physical-Located, TennesseeGPE),或者Physical-Located(HePER, TennesseeGPE)。
可见关系抽取包含命名实体识别在内,在技术实现上更复杂。
关系抽取从流程上,可以分为流水线式抽取(Pipline)和联合抽取(Joint Extraction)两种。
流水线式抽取就是把关系抽取的任务分为两个步骤:首先做实体识别,再抽取出两个实体的关系;而联合抽取的方式就是一步到位,同时做好了实体和关系的抽取。
流水线式抽取会导致误差在各流程中传递和累加,而联合抽取的方式则实现难度更大。
关系抽取从实现的算法来看,主要分为四种:
手写规则(Hand-Written Patterns)
监督学习算法(Supervised Machine Learning)
半监督学习算法(Semi-Supervised Learning,比如Bootstrapping和Distant Supervision)
无监督算法(Unsupervised learning)
本文的主人公是远程监督算法(Distant Supervision),这是一种半监督学习算法。其他的方法大致了解一下,有助于理解,为什么相对而言,远程监督做关系抽取是一种比较可行的方法。
(一)例子
有种关系叫做上下位关系,比如hyponym(France; European countries),意思是法国是欧洲国家。从下面两个句子中都可以抽取出这种关系:
European countries, especially France, England, and Spain...
European countries, such as France, England, and Spain...
两个实体之间的especially和such as可以看做这种关系的特征。
观察更多表达这种关系的句子,我们就可以构造如下的规则模板,来抽取构成上下位关系的实体,从而发现新的三元组。

(二)优点和缺点
优点是抽取的三元组查准率(Precision)高,尤其适合做特定领域的关系抽取;缺点是查全率(Recall)很低,也就是说查得准,但是查不全,而且针对每一种关系都需要手写大量的规则。
如果你恨谁,就让他去手写规则模板吧!
监督学习的方法也就是给训练语料中的实体和关系打上标签,构造训练集和测试集,再用传统机器学习的算法(LR,SVM和随机森林等)或神经网络训练分类器。
(一)机器学习和深度学习方法
对于传统的机器学习方法,最重要的步骤是构造特征。可以使用的特征有:
(1)词特征:实体1与实体2之间的词、前后的词,词向量可以用Bag-of-Words结合Bi-gram等。
(2)实体标签特征:实体的标签。
(3)依存句法特征:分析句子的依存句法结构,构造特征。这个不懂怎么弄。

人工构造特征非常麻烦,而且某些特征比如依存句法,依赖于NLP工具库,比如HanLP,工具带来的误差不可避免会影响特征的准确性。
用端到端的深度学习方法就没这么费劲了。
比如使用CNN或Bi-LSTM作为句子编码器,把一个句子分词后的词嵌入(Word Embedding)作为输入,用CNN或LSTM做特征的抽取器,最后经过softmax层得到N种关系的概率。
这样省略了特征构造这一步,自然不会在特征构造这里引入误差。
(二)监督学习的优缺点
监督学习的优点是,如果标注好的训练语料足够大,那么分类器的效果是比较好的,可问题是标注的成本太大了。
鉴于监督学习的成本太大,用半监督学习做关系抽取是一个很值得研究的方向。
半监督学习的算法主要有两种:Bootstrapping和Distant Supervision。
Bootstrapping不需要标注好实体和关系的句子作为训练集,不用训练分类器。
Distant Supervision可以看做是Bootstrapping和Supervise Learning的结合,需要训练分类器。
这里介绍Bootstrapping的思想,Distant Supervision作为主人公,在后面的部分详细介绍。
(一)例子
Bootstrapping算法的输入是拥有某种关系的少量实体对,作为种子,输出是更多拥有这种关系的实体对。
敲黑板!不是找到更多的关系,而是发现拥有某种关系的更多新实体对。
举个栗子,“创始人”是一种关系,如果我们已经有了一个小型知识图谱,里面有3个表达这种关系的实体对:(严定贵,嘉银金科),(马云,阿里巴巴),(雷军,小米)。
第一步:在一个大型的语料集中去找包含某一实体对(3个中的任意1个)的句子,全部挑出来。
比如:严定贵于2011年创立了嘉银金科;严定贵是嘉银金科的创始人;在严定贵董事长的带领下,嘉银金科赴美上市成功。
第二步:归纳实体对的前后或中间的词语,构造特征模板。比如:A 创立了 B;A 是 B 的创始人;在A 的带领下,B。
第三步:用特征模板去语料集中寻找更多的实体对,然后给所有找到的实体对打分排序,高于阈值的实体对就加入到知识图谱中,扩展现有的实体对。
第四步:回到第一步,进行迭代,得到更多模板,发现更多拥有该关系的实体对。

细心的小伙伴会发现,不是所有包含“严定贵”和“嘉银金科”的句子都表达了“创始人”这种关系啊,比如:“在严定贵董事长的带领下,嘉银金科赴美上市成功”——这句话就不是表达“创始人”这个关系的。
某个实体对之间可能有很多种关系,哪能一口咬定就是知识图谱中已有的这种关系呢?
这不是会得到错误的模板,然后在不断的迭代中放大错误吗?
没错,这个问题叫做语义漂移(Semantic Draft),一般有两种解决办法:
一是人工校验,在每一轮迭代中观察挑出来的句子,把不包含这种关系的句子剔除掉。
二是Bootstrapping算法本身有给新发现的模板和实体对打分,然后设定阈值,筛选出高质量的模板和实体对。具体的公式可以看《Speech and Language Processing》(第3版)第17章。
(二)Bootstrapping的优缺点
Bootstrapping的缺点,一是上面提到的语义漂移问题,二是查准率会不断降低而且查全率太低,因为这是一种迭代算法,每次迭代准确率都不可避免会降低,80%---->60%---->40%---->20%...。所以最后发现的新实体对,还需要人工校验。
半监督的办法效果已经差强人意,无监督的效果就难以保证了,这里不在介绍。
四:远程监督关系抽取的滥觞
第一篇要介绍的论文是《Distant supervision for relation extraction without labeled data》,斯坦福大学出品,把远程监督的方法用于关系抽取。研究关系抽取的远程监督算法,不得不提这篇论文。
这篇论文首先回顾了关系抽取的监督学习、无监督学习和Bootstrapping算法的优缺点,进而结合监督学习和Bootstrapping的优点,提出了用远程监督做关系抽取的算法。
远程监督算法有一个非常重要的假设:
对于一个已有的知识图谱(论文用的Freebase)中的一个三元组(由一对实体和一个关系构成),假设外部文档库(论文用的Wikipedia)中任何包含这对实体的句子,在一定程度上都反映了这种关系。
基于这个假设,远程监督算法可以基于一个标注好的小型知识图谱,给外部文档库中的句子标注关系标签,相当于做了样本的自动标注,因此是一种半监督的算法。
具体来说,在训练阶段,用命名实体识别工具,把训练语料库中句子的实体识别出来。
如果多个句子包含了两个特定实体,而且这两个实体是Freebase中的实体对(对应有一种关系),那么基于远程监督的假设,认为这些句子都表达了这种关系。
于是可以从这几个句子中提取文本特征,拼接成一个向量,作为这种关系的一个样本的特征向量,用于训练分类器。
论文中把Freebase的数据进行了处理,筛选出了94万个实体、102种关系和180万实体对。下面是实体对数量最多的23种关系。
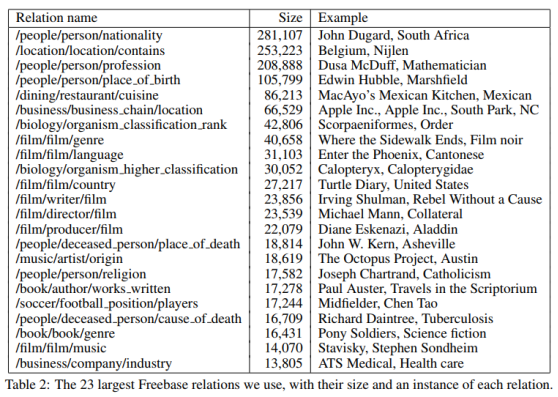
关系种类相当于分类的类别,那么有102类;每种关系对应的所有实体对就是样本;从Wikipedia中所有包含某实体对的句子中抽取特征,拼接成这个样本的特征向量。
最后训练LR多分类器,用One-vs-Rest,而不是softmax,也就是训练102个LR二分类器——把某种关系视为正类,把其他所有的关系视为负类。
因为远程监督算法可以使用大量无标签的数据,Freebase中的每一对实体在文档库中可能出现在多个句子中。
从多个句子中抽出特征进行拼接,作为某个样本(实体对)的特征向量,有两个好处:
一是单独的某个句子可能仅仅包含了这个实体对,并没有表达Freebase中的关系,那么综合多个句子的信息,就可以消除噪音数据的影响。
二是可以从海量无标签的数据中获取更丰富的信息,提高分类器的准确率。
但是问题也来了,这个假设一听就不靠谱!
哪能说一个实体对在Freebase中,然后只要句子中出现了这个实体对,就假定关系为Freebase中的这种关系呢?
一个实体对之间的关系可能有很多啊,比如马云和阿里巴巴的关系,就有“董事长”、“工作”等关系,哪能断定就是“创始人”的关系呢?
这确实是个大问题,在本篇论文中也没有提出解决办法。
论文中使用了三种特征:词法特征(Lexical features)、句法特征(Syntactic features)和实体标签特征(Named entity tag features)。
(一)词法特征
词法特征描述的是实体对中间或两端的特定词汇相关的信息。比如有:
两个实体中间的词语和词性
实体1左边的k个词语和词性,k取{0,1,2}
实体2右边的k个词语和词性,k取{0,1,2}
然后把这些特征表示成向量再拼接起来。比如用词袋模型,把词语和词性都表示为向量。
(二)句法特征
论文中的句法特征就是对句子进行依存句法分析(分析词汇间的依存关系,如并列、从属、递进等),得到一条依存句法路径,再把依存句法路径中的各成分作为向量,拼接起来。
如下为一个句子的依存句法路径,我不太懂,不多说。
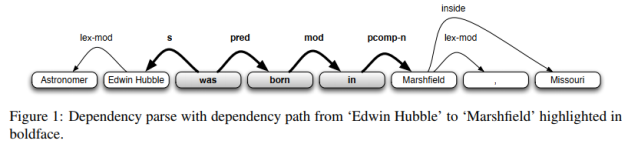
(三)命名实体标签特征
论文中做命名实体识别用的是斯坦福的NER工具包。把两个实体的标签也作为特征,拼接起来。
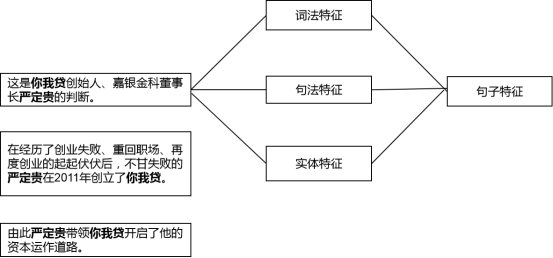
总结一下,论文中使用的特征不是单个特征,而是多种特征拼接起来的。
有多个句子包含某实体对,可以从每个句子中抽取出词法特征、句法特征和实体特征,拼接起来,得到一个句子的特征向量,最后把多个句子的特征向量再拼接起来,得到某实体对(一个样本)的特征向量。
不过作者为了比较词法特征和句法特征的有效性,把特征向量分为了3种情况:只使用词法特征,只使用句法特征,词法特征与句法特征拼接。

(一)数据集说明
知识图谱或者说标注数据为Freebase,非结构化文本库则是Wikipedia中的文章。
论文中把Freebase的三元组进行了筛选,筛选出了94万个实体、102种关系和相应的180万实体对。用留出法进行自动模型评估时,一半的实体对用于训练,一半的实体对用于模型评估。
同样对Wikipedia中的文章进行筛选,得到了180万篇文章,平均每篇文章包含约14.3个句子。从中选择80万条句子作为训练集,40万条作为测试集。
(二)构造负样本
由于对于每种关系,都要训练一个LR二分类器,所以需要构造负样本。这里的负样本不是其他101种关系的训练样本,而是这样的句子:从训练集中的句子中抽取实体对,如果实体对不在Freebase中,那么就随机挑选这样的句子就作为负样本。
(三)训练过程
LR分类器以实体对的特征向量为输入,输出关系名和概率值。每种关系训练一个二分类器,一共训练102个分类器。
训练好分类器后,对测试集中的所有实体对的关系进行预测,并得到概率值。然后对所有实体对按概率值进行降序排列,从中挑选出概率最高的N个实体对(概率值大于0.5),作为发现的新实体对。
(四)测试方法和结论
测试的指标采用查准率,方法采用了留出法(自动评估)和人工评估两种方法。
留出法的做法是,把Freebase中的180万实体对的一半作为测试集(另一半用于训练)。新发现的N个实体对中,如果有n个实体对在Freebase的测试集中,那么查准率为n/N。
人工评估则采用多数投票的方法。
模型评估的结果表明,远程监督是一种较好的关系抽取算法。
在文本特征的比较上,词法特征和句法特征拼接而成的特征向量,优于单独使用其中一种特征的情况。
此外,句法特征在远程监督中比词法特征更有效,尤其对于依存句法结构比较短而实体对之间的词语非常多的句子。
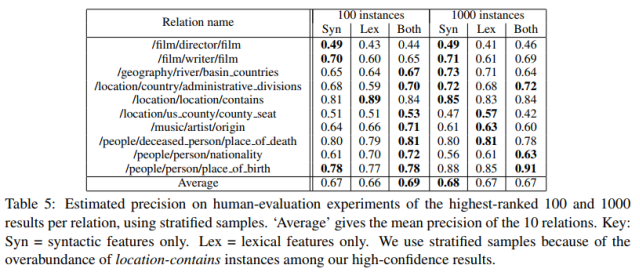
这篇论文把远程监督的思想引入了关系抽取中,充分利用未标注的非结构化文本,从词法、句法和实体三方面构造特征,最后用留出法和人工校验两种方法进行模型评估,是一种非常完整规范的关系抽取范式。
不足之处有两点:
第一个是前面所提到的问题,那就是远程监督所基于的假设是一个非常强的假设。哪能说一个实体对在Freebase中存在一种关系,那么只要外部语料库中的句子中出现了这个实体对,就假定关系为Freebase中的关系呢?还可能是其他关系啊?
Bootstrapping中也有这个问题,称为语义漂移问题,但Bootstrapping本身通过给新发现的规则模板和实体对打分,在一定程度上缓解了这个问题。
而这篇论文并没有提到这个问题,更没有涉及到解决办法。我猜这是因为Freebase中的实体对和关系主要就是从Wikipedia中抽取出来的,而且关系属于比较典型的关系。
这点就成了后续远程监督关系抽取算法的一个改进方向,后面的研究人员提出了利用多实例学习和句子级别的注意力机制来解决这个问题。
第二个是论文中用到了三种特征,一顿操作猛如虎,但实际上构造这些特征非常繁琐,而且词性标注和依存句法分析依赖于NLP工具库,因此工具库在标注和解析中所产生的误差,自然会影响到文本特征的准确性。
这点也是后续研究的一个改进方向,后面的研究人员用神经网络作为特征提取器,代替人工提取的特征,并用词嵌入作为文本特征。
参考资料:
1、《Speech and Language Processing》(Third Edition draft)第17章
2、《cs224u: Relation extraction with distant supervision》
3、《Distant supervision for relation extraction without labeled data》






