EMNLP 2020 | 微软亚洲研究院精选论文解读

编者按:EMNLP 是自然语言处理领域的顶级会议之一,2020年的 EMNLP 会议将于11月16日至20日召开。微软亚洲研究院精选了5篇录取的论文为大家进行介绍。
多样、可控且关键短语感知:一个新闻多标题生成的语料库与方法
Diverse, Controllable, and Keyphrase-Aware: A Corpus and Method for News Multi-Headline Generation
论文链接:https://arxiv.org/abs/2004.03875
新闻标题生成是文本摘要领域的一个子任务。文本摘要往往包含多个上下文相关的句子来涵盖文档的主要思想,而新闻标题则要用一个简短的句子来吸引用户阅读新闻。由于一篇新闻文章通常可以有多种合理的新闻标题,并且包含多个不同用户感兴趣的关键短语或主题。因此,同一篇新闻可以围绕不同用户感兴趣的不同关键短语,生成多个新闻标题并根据用户的兴趣推荐具有不同新闻标题的新闻。同时,新闻多标题的生成也可以为新闻编辑提供辅助信息。
传统的新闻标题方法往往将新闻标题生成过程看作为是一对一的映射,即通过序列到序列模型,将输入的新闻文章映射到输出的新闻标题。由于一篇新闻有多种合理的标题,所以在训练阶段让模型生成单个的 ground-truth 会缺乏进一步的指导信息。而且在测试阶段,单个的 ground-truth 也难以进行合理的自动评价。为了缓解这个问题,本文额外引入了关键短语输入作为指导信息,将一对一的映射转换为二对一的映射。文章提出了一个关键短语敏感的新闻多标题生成方法,该方法包含两个模块,关键短语生成模型和关键短语敏感的新闻标题生成模型。整体结构如图1所示。
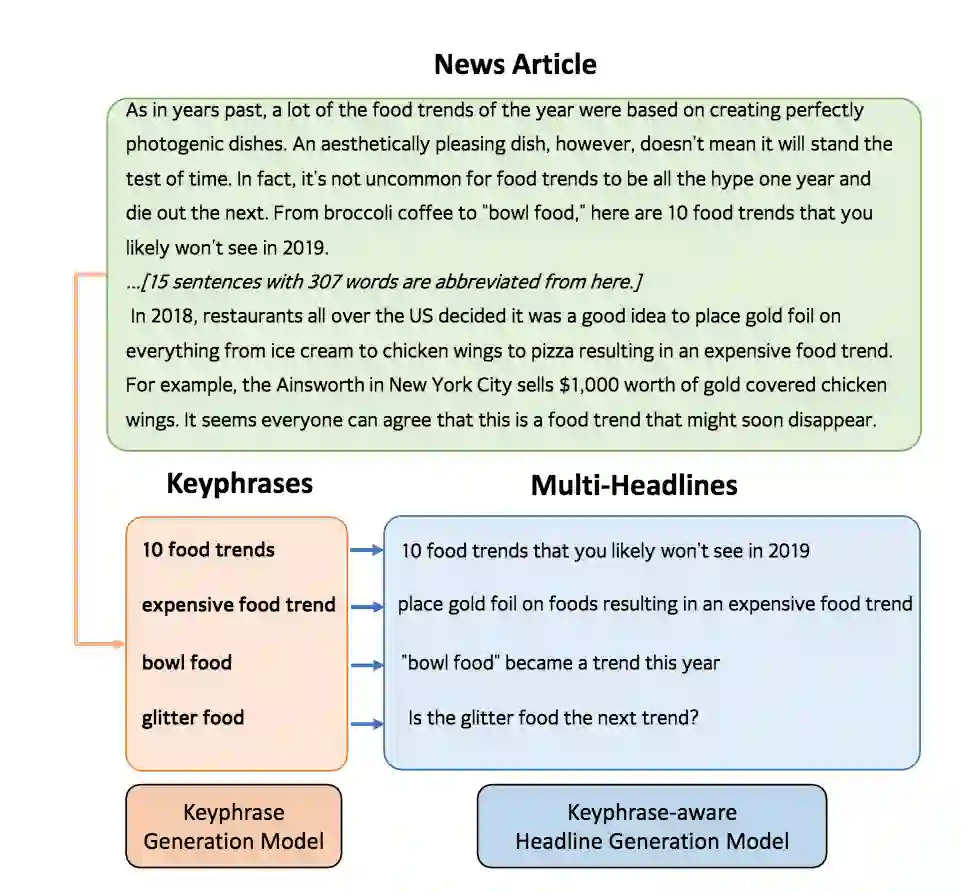
图1:关键短语敏感的新闻多标题生成
研究员们基于必应新闻(Bing News)搜索引擎,利用用户查询、引擎返回的新闻标题和文章以及用户基于查询点击新闻的次数,去挖掘新闻中用户感兴趣的关键短语,并构造了 KeyAware News 数据集。该数据集包含18万对齐的<用户感兴趣的关键短语,新闻标题,新闻文章>三元组数据。
对于关键短语敏感的新闻标题生成模型,基于 BERT 作为编码器,Transformer 作为解码器并带有 copy 机制的新闻标题生成 BASE 模型,研究员们进一步探索了几种在解码器处引入关键短语信息的模型结构,如图2所示。
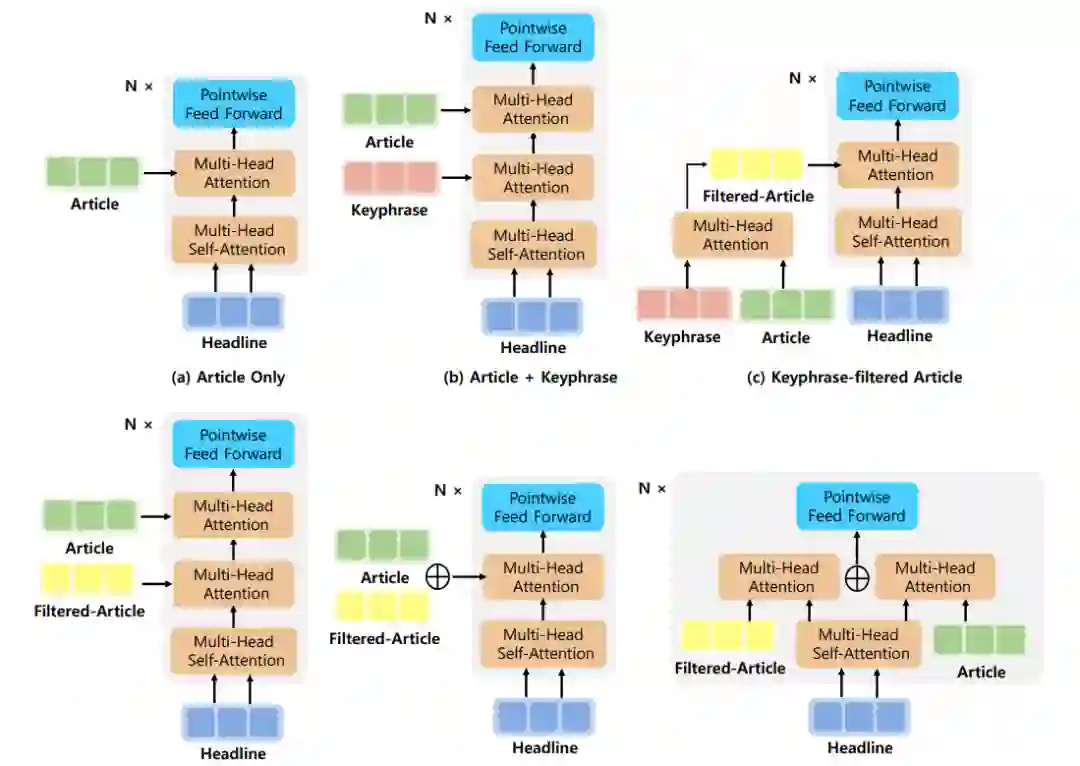
图2:关键短语敏感的新闻标题生成模型解码器及其变体
对于新闻文章的关键短语生成,研究员们尝试了 TF-IDF、Seq2seq 和 POS Tagging 等方法。他们通过实验对比了关键短语生成的效果(表1),以及和多种基准方法与模型变体在生成标题的质量和多样性上进行了人工评价和自动评价(表2)。并且通过一个基于检索的实验(表3),将生成的新闻标题作为新闻的搜索键值,通过对应的用户查询去检索新闻,来进一步测试生成新闻的质量和多样性。大量的实验结果证明了本文提出方法的有效性。
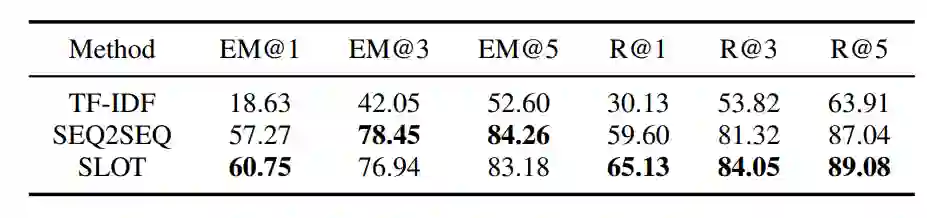
表1:关键短语生成方法结果对比
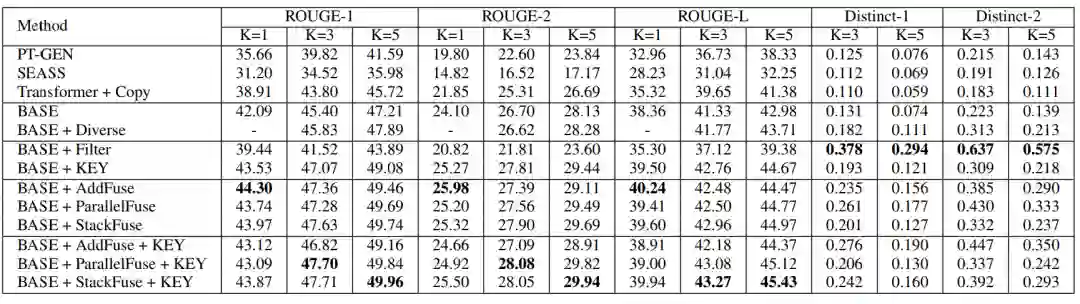
表2:多标题生成结果对比
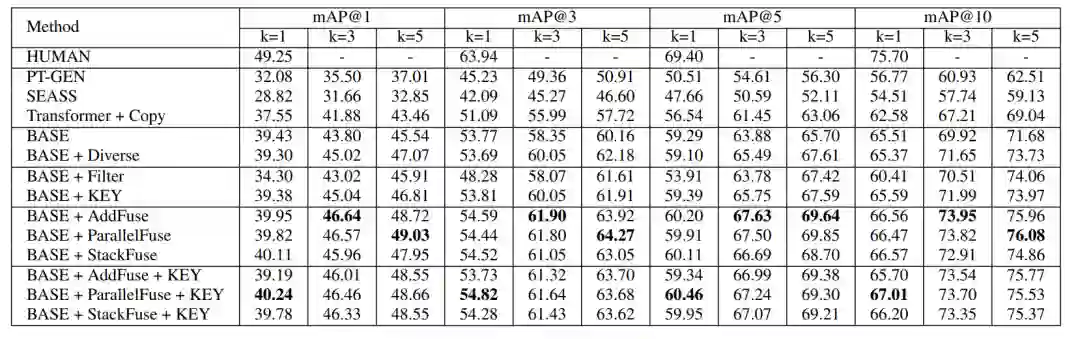
表3:新闻检索实验结果对比
用语义分割的思路解决不完整话语重写任务:一种全新的观点
Incomplete Utterance Rewriting as Semantic Segmentation
论文链接:https://arxiv.org/abs/2009.13166
代码链接:https://github.com/microsoft/ContextualSP
近些年单轮对话的理解已经取得了较大的进展,但多轮对话仍是学术界的一个难题。多轮对话的一大挑战就在于用户会抛出语义不完整的问题,如省略实体或者通过代词指代到对话历史中的实体。这样的挑战推动了上下文理解方向的研究工作,包括早期端到端的上下文建模方法,和近期研究者们所关注的不完整话语重写(Incomplete Utterance Rewriting)。
不完整话语重写旨在将对话中语义不完整的句子重写为一个语义完整的、可脱离上下文理解的句子,以恢复所有指代和省略的信息。由于该任务的输出严重依赖于输入,已有工作绝大部分都是在复制网络的基础上进行改进。而微软亚洲研究院的研究员们另辟蹊径地将该任务视为一个面向对话编辑的任务,并据此提出了一个全新的、使用语义分割思路来解决不完整话语重写的模型。
在本篇论文中,研究员们提出了一个使用语义分割思路来预测编辑过程的模型 RUN (Rewriting U-shaped Network)。与传统基于复制网络的生成模型不同,RUN 将不完整话语重写视为面向对话编辑的任务: 对话中的语句片段可以插入到某个位置,或替换某个片段。图3中展示了 A 和 B 之间的一个对话,其中最后一句“为什么总是这样”是一个语义不完整的语句,其重写后的语句是“北京为什么总是阴天”。这个示例中的重写可以通过两个简单的编辑操作来刻画,分别是把“北京”插入到“为”前,和用“阴天”替换“这样”。实际上,由于该任务本身的性质,绝大多数重写句都只需要用到原对话中的词,这在一定程度上说明了面向对话编辑的合理性和普适性。

图3:面向对话编辑的一个示例
那么,这个编辑任务与语义分割又有何联系呢?因为编辑动作涉及到的是分别来自对话历史(c)和不完整话语(x)的两个片段,所以很自然地可以将其想象成图4中的词级别的编辑矩阵,其中黄色代表插入操作,绿色代表替换操作,灰色则代表无操作。这样词级别的编辑矩阵与语义分割中的像素级掩码 (pixel-level mask,图5右上侧)是十分相似的。
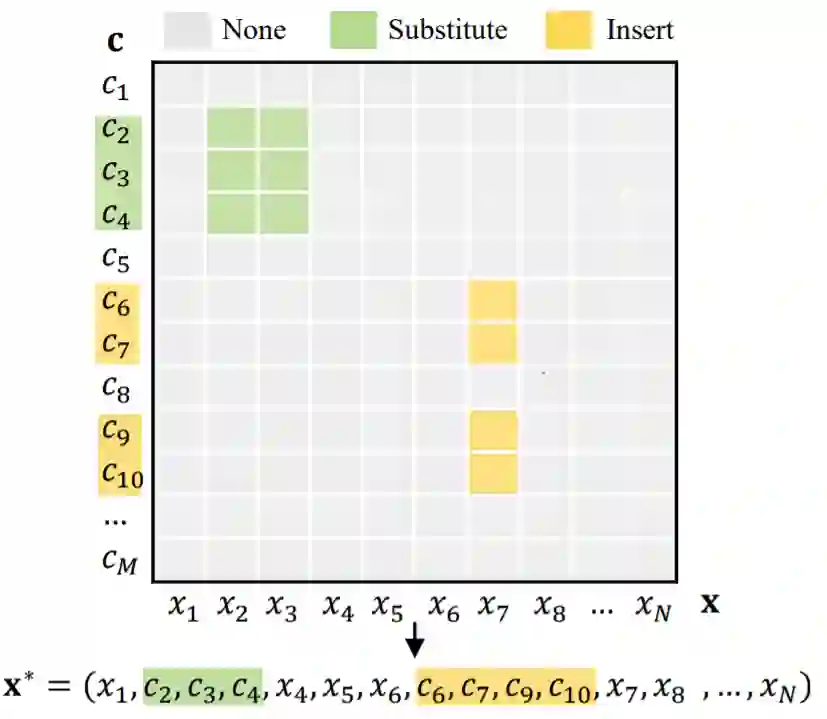
图4:编辑操作可以视为二维平面上词对词的编辑矩阵
受这样的类比启发,如图5所示,研究员们首先通过类似于注意力机制的方式构造了词与词之间的特征图矩阵。将该矩阵作为一个经典语义分割模型 U-Net (Ronneberger et al. 2015) 的输入,可以得到词级别的编辑矩阵。拿到编辑矩阵后,在原对话上执行编辑操作即可得到最终的重写句。
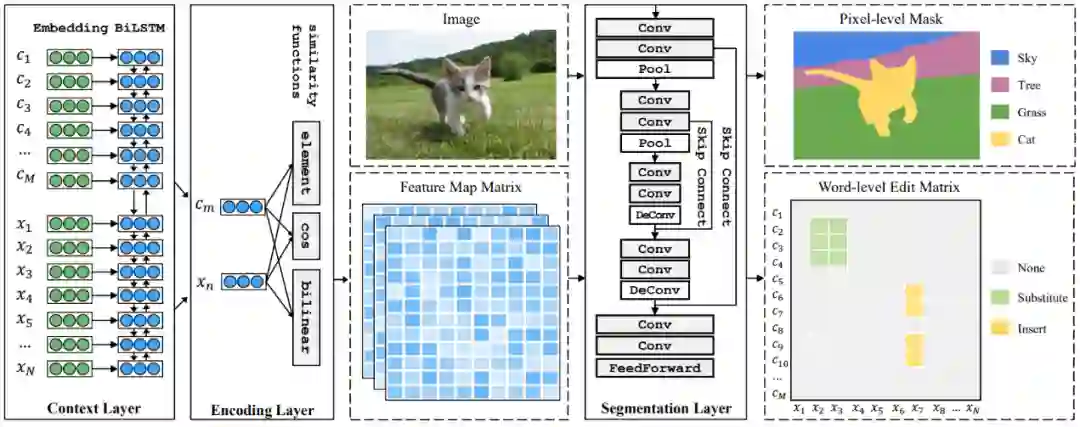
图5:RUN 模型得到词级别编辑矩阵的过程
在四个公开数据集上,微软亚洲研究院研究员们的模型都取得了相似或更好的性能。表4和表5分别显示了 Multi 和 Rewrite 数据集上的实验结果。如图所示,RUN 在几乎所有指标上都达到了最先进的性能,显著超过了各种基于 LSTM 和 Transformer 的复制网络变种 (如 L-Ptr-Gen 和 T-Ptr-λ)。此外,RUN 和 BERT 结合时显示出了非常优越的性能,大幅度超过同样利用 BERT 的 SOTA 模型。同时,RUN 的推理速度也大幅超过传统模型,达到了将近4倍的加速比。目前,本篇论文相应的代码已经开源(https://github.com/microsoft/ContextualSP)。
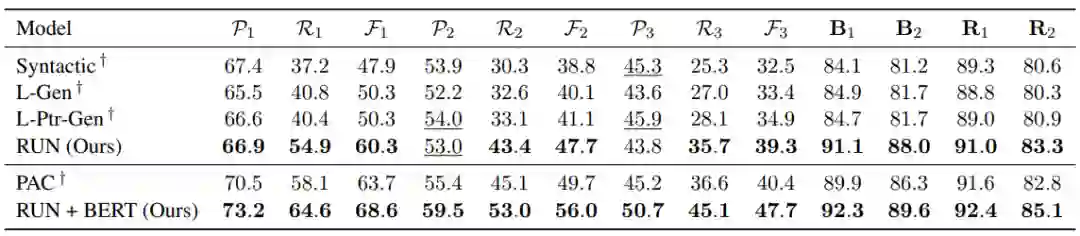
表4:RUN 和 RUN+BERT 在数据集 Multi (Pan et al. 2019) 上的实验结果
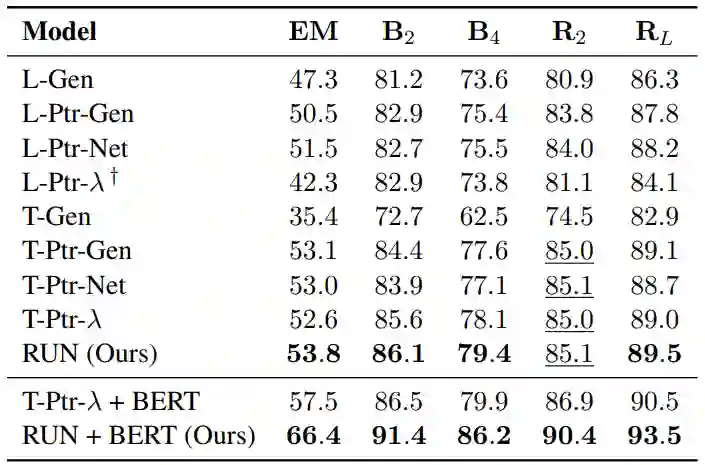
表5:RUN 和 RUN+BERT 在数据集 Rewrite (Su et al. 2019)上的实验结果
基于常识知识图谱的多跳推理文本生成
Language Generation with Multi-Hop Reasoning on Commonsense Knowledge Graph
论文链接:https://arxiv.org/pdf/2009.11692v1.pdf
人类语言通常涉及各种常识知识。例如,当人类在讲故事或者对日常生活中的场景进行解释时,常常会联系相关的背景常识知识进行推理。目前将语言模型在大规模语料上预训练,然后在下游任务上微调的范式在许多文本生成任务上都取得了显著的效果。尽管语言模型通过在大量语料上预训练隐式地学习到了一定的知识,然而这种获取知识的方式没有显式利用知识库和知识图谱,因此较为低效。
在语言生成领域,目前已有的增强预训练模型常识知识的方法是将预训练模型在常识知识库中的知识三元组上进行进一步的后训练。本篇论文研究提出了利用更丰富的常识知识图谱信息,在文本生成时显式地在知识图谱中的关系路径上进行多跳推理,并利用图谱中的相关实体用于文本生成。微软亚洲研究院的研究员们在故事生成、解释生成、溯因常识推理等任务上进行了实验,自动文本生成评测指标和人工指标均表明所提出的模型能够更好地在生成中利用常识知识。
本研究关注一类条件文本生成任务,即给定输入源文本X,目标是生成一段目标文本 Y。研究员们额外增加了一个知识图谱 G=(V,E) 的输入为模型在生成时提供常识知识的信息。图6为模型框架图。
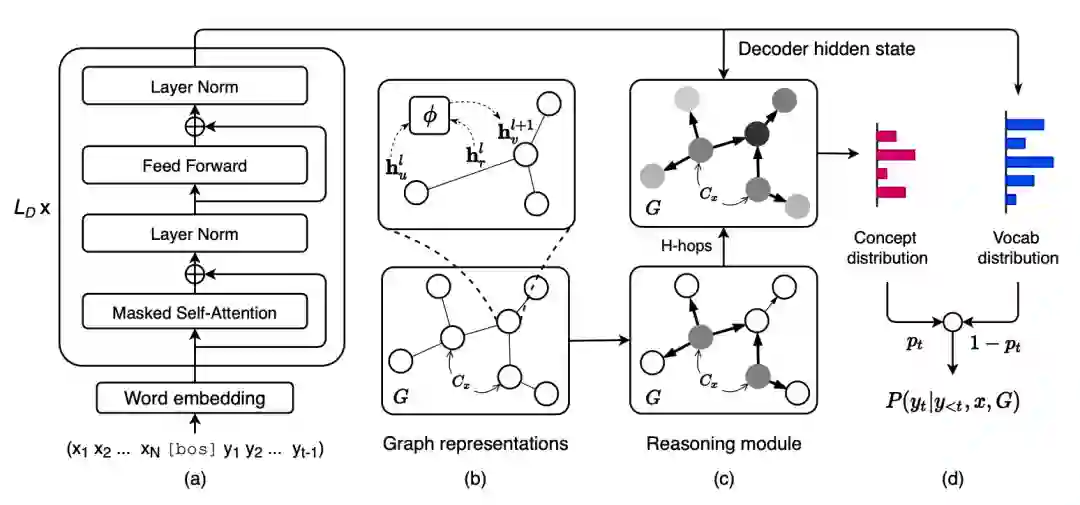
图6:模型框架图
模型分为四个部分:(a)使用预训练的语言模型对上下文进行建模,根据输入和当前生成的目标文本前缀计算当前步骤的解码器隐状态。(b)使用图卷积神经网络对输入的知识图谱进行编码得到图结构感知的实体向量表示和关系向量表示。(c)多跳推理模块结合实体表示、关系表示和当前的解码器隐状态,在知识图谱上进行多跳推理,并在图上计算归一化的实体概率分布。(d)利用解码器隐状态计算词表上的概率分布和拷贝概率,根据图谱上实体分布选择拷贝相关的实体用于当前词的生成。自动指标和人工评测均表明所提出的模型比现有基线模型取得了一定的提升。
告诉我如何再次提问:基于在连续空间可控式改写的问句数据增广
Tell Me How to Ask Again: Question Data Augmentation with Controllable Rewriting in Continuous Space
论文链接:https://arxiv.org/abs/2010.01475
数据增广是一种常用的提升模型泛化能力的方法。相比旋转、剪裁等图像数据常用的数据增广方法,合成新的高质量且多样化的离散文本相对来说更加困难。近年来,一些文本数据增广方法被提出,这些方法大体可分为两类,一类是通过替换、删减、增添等操作对文本局部进行修改以生成新的数据。另一类是利用模型生成新的数据,如利用翻译模型的回译、利用 Mask Language Model 合成新的数据、利用 GAN、VAE 等生成模型生成新的数据。然而,对于机器阅读理解、问句生成、问答自然语言推理等涉及段落、答案和问句的任务,使用传统的文本数据增广方法单独对问句或段落进行增广可能会生成不相关的问句-段落数据对,对模型的性能提升帮助不大。
针对机器阅读理解、问句生成、问答自然语言推理等任务的问句数据增广,本篇论文将该类问句数据增广任务看作是一个带限制的问句改写任务,即要让改写后的问句与原始文档和答案是相关的,并且希望生成与原始问句接近的不可回答(unanswerable)问句和可回答(answerable)问句。受连续空间修改的可控式改写方法的启发,研究员们提出了基于可控式改写的问句增广方法(Controllable Rewriting based Question Data Augmentation, CRQDA)。
与在离散空间修改问句的方法不同,该方法在连续的词向量空间,以机器阅读理解模型作为指导对问句进行改写。相比有监督的方法,该方法不需要成对的问句语料,就可以将可回答问句改写为相似的不可回答问句。
如图7所示,CRQDA 包含两个核心模块:1)基于 Transformer 的自编码器,该模型将离散的问句文本映射到连续空间并重构问句。2)预先训练好的抽取式机器阅读理解模型。该模型与自编码器的编码器部分共享词向量部分的参数,以确保二者的问句词向量位于同一个连续空间。利用机器阅读理解模型的输出与目标标签(想要可回答问句或不可回答问句)的误差回传得到的梯度信息,作为问句在词向量这一连续空间中进行修改的指导(改写过程如图8所示,具体改写算法如图9所示)。
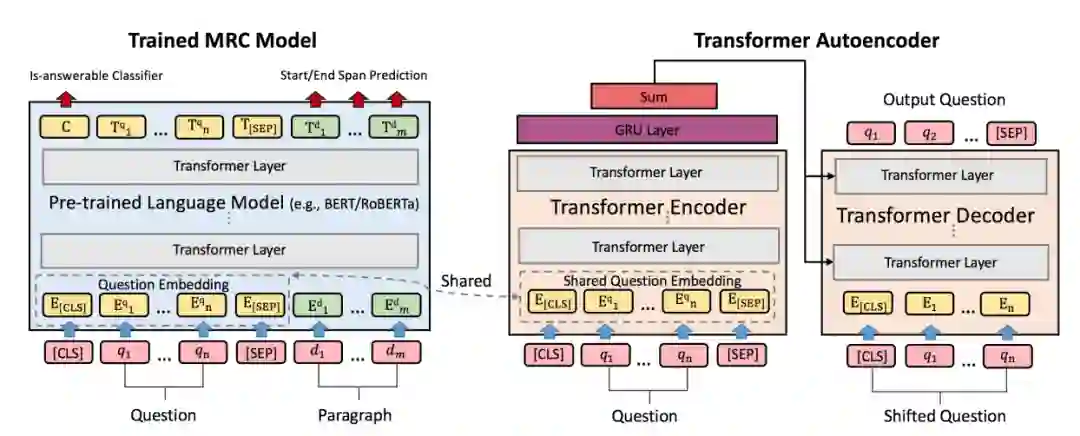
图7:CRQDA 模型结构
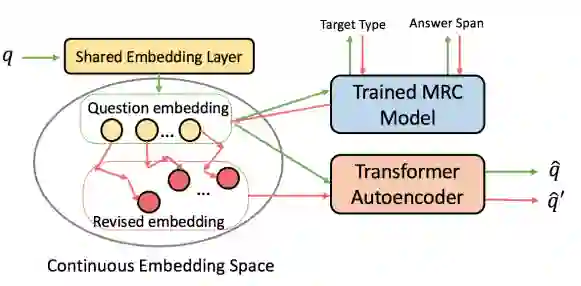
图8:CRQDA 问句改写过程

图9:CRQDA 问句修改算法
实验在 SQuAD 2.0 数据集上与多种问句增广方法和文本增广方法进行了比较(见表6)。
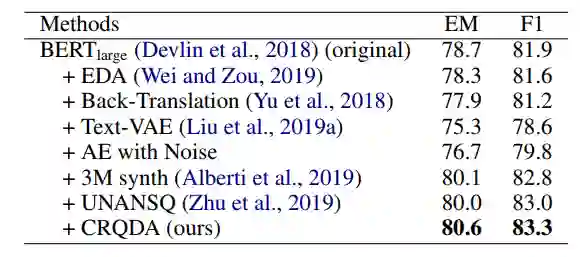
表6:SQuAD 2.0 数据增广方法对比
此外,实验也进一步探索了使用增广数据对不同机器阅读理解模型性能的提升(表7)、使用不同数据对自编码器进行训练对 CRQDA 性能的影响(表8)以及使用不同设定生成增广数据对模型性能的影响(表9)。
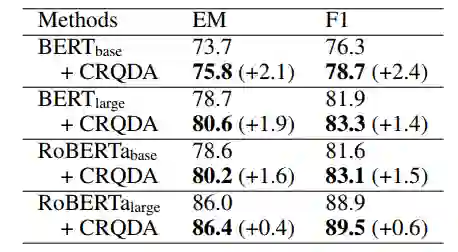
表7:CRQDA 对不同机器阅读理解模型的性能提升
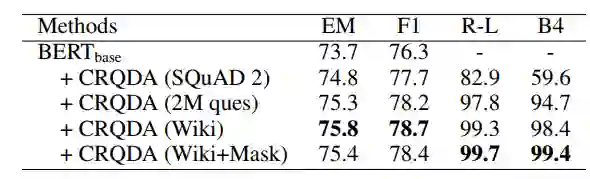
表8:不同训练数据对 CRQDA 的性能影响
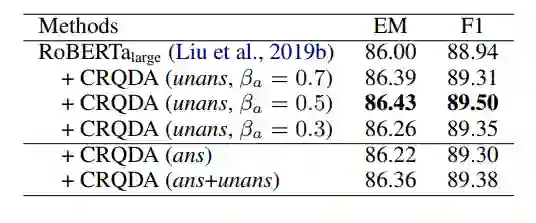
表9:CRQDA 不同增广数据对性能的影响
进一步地,研究员们也将方法应用于问句生成任务(表10)和问答自然语言推理任务(表11)。大量实验验证了提出方法的有效性。
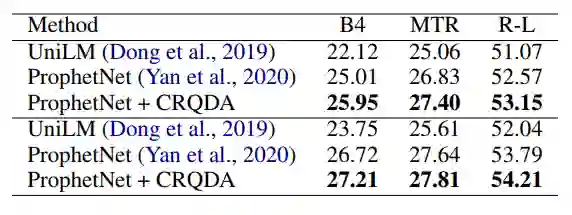
表10:CRQDA 对 SQuAD1.1 问句生成任务的性能提升

表11:CRQDA 对 QNLI 问答自然语言推理任务的性能提升
利用分层Transformer模型的注意力机制进行非监督性抽取式摘要
Unsupervised Extractive Summarization by Pre-training Hierarchical Transformers
论文链接:https://arxiv.org/abs/2010.08242
抽取式文本摘要的主要目的是从一篇长文章中选择几个可以概括文章主要内容的句子,将它们作为该文章的摘要。在没有监督信息的情况下,该问题通常被表示成对一篇文章中的句子的排序问题,在以前的工作中,常常是通过模型学习文章中句子的向量表征,利用这些句子表征和一些人为拟定的规则构造一个以句子为结点的图,但这些规则有时候会导致选取结果在一定程度上很依赖句子在文章中的位置。
本文利用 Transformer 中的注意力机制对句子进行排序。为了学习句子层面的注意力系数,研究采用了分层的结构。
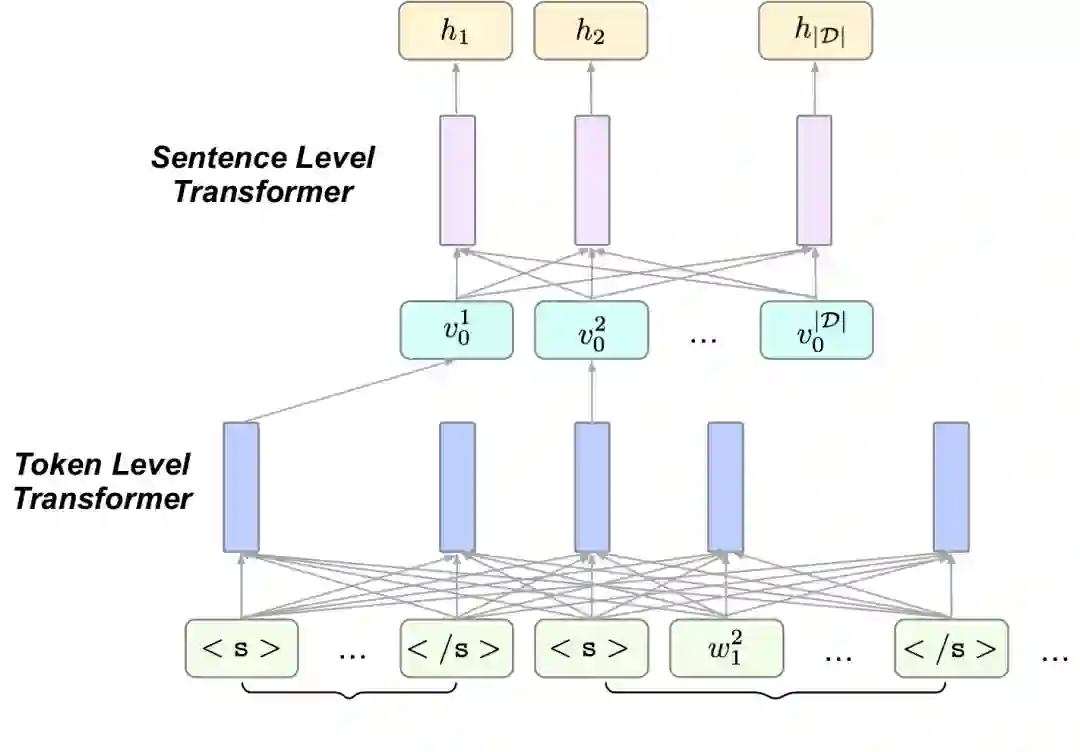
图10:编码器的分层结构
研究员们采用了两种预训练方法来训练该模型,Masked Sentences Prediction (MSP) 将文章中的某些句子掩盖住,然后利用上下文恢复出被掩盖的句子。
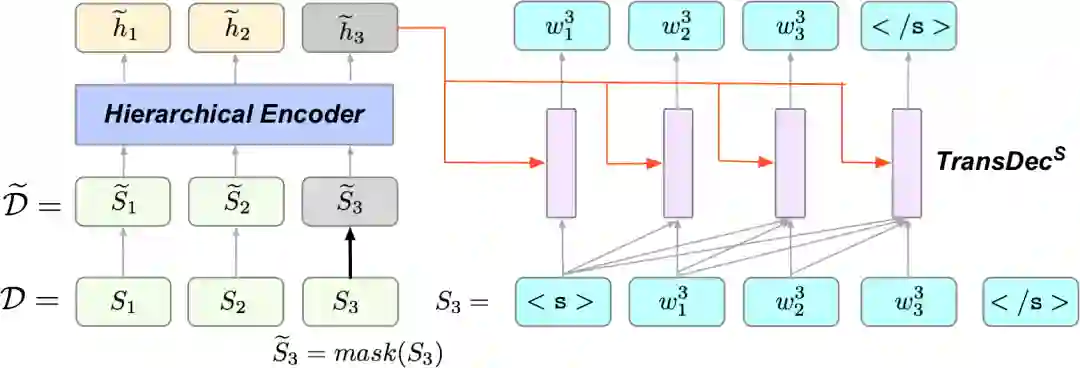
图11:MSP 示意图
另一方面,为了减弱模型对于句子位置的依赖,研究员们提出了另一种预训练方式 Sentence Shuffling (SS)。SS先将文章中的句子打乱,然后依次找出原文中的句子打乱后所在的位置。
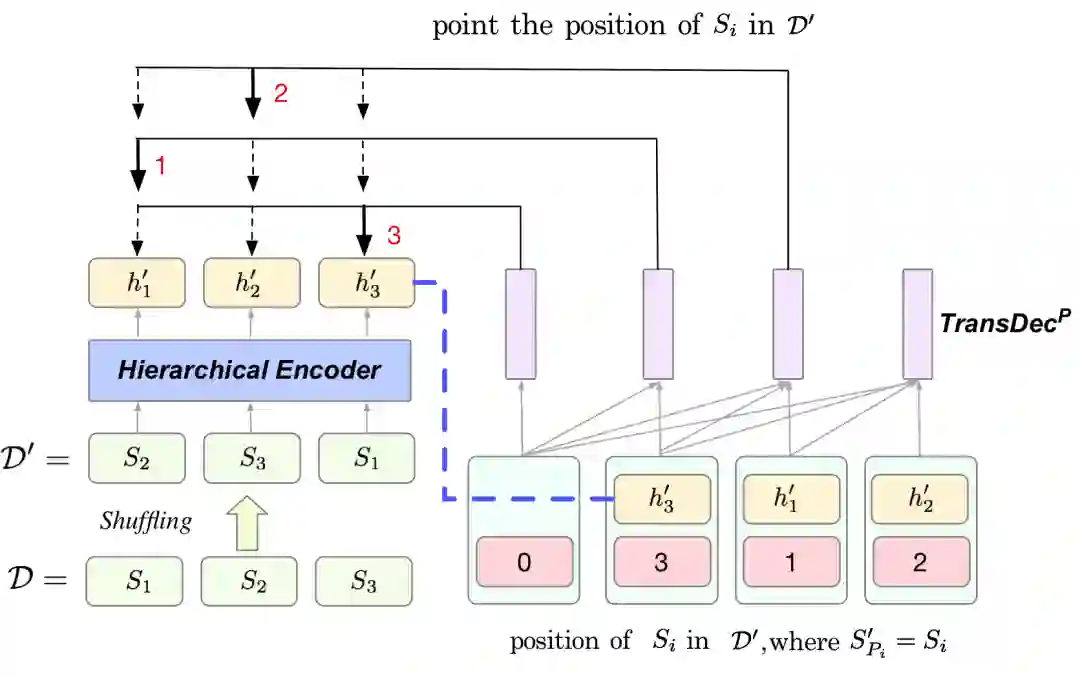
图12:SS 示意图,经过打乱后原文中的第1句话到了第3个位置,模型的第1个预测结果应该是3,同理,第2个预测结果应该是1。
经过以上两种预训练,在对句子排序时,研究员们将文章中的句子逐个掩盖,然后利用其他句子恢复被掩盖的句子(过程像 MSP 一样)。之后利用恢复情况对当前被掩盖的句子评分,同时用注意力系数评价其他句子在恢复当前句子的贡献。最后,通过最终评分对句子进行排序,得分最高的三个句子被选作摘要。
该方法在 CNN/DM 数据集和 NYT 数据集上都取得了非常不错的效果。并且经过验证,这个方法可以更少地依赖于句子的位置。
你也许还想看: