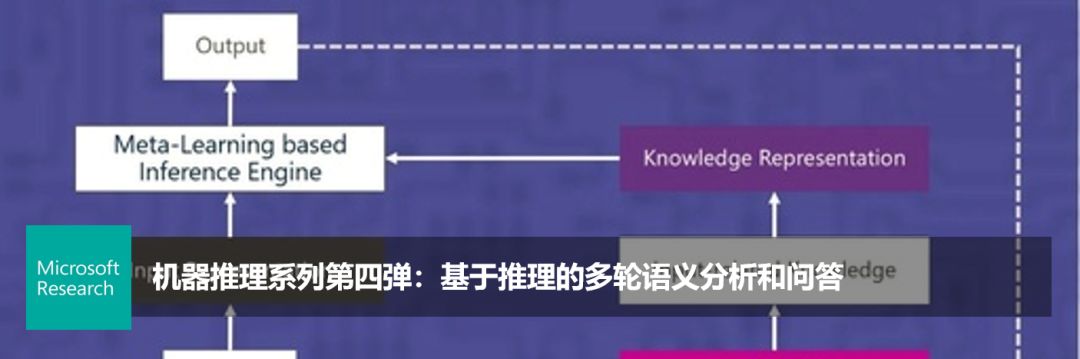
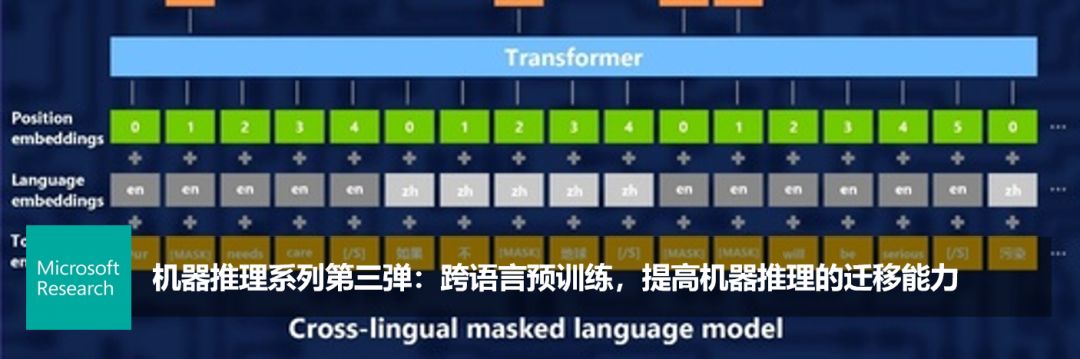
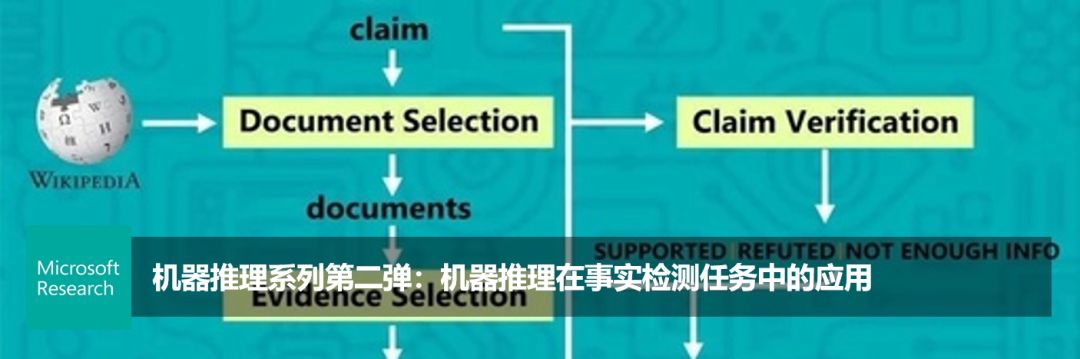
机器推理系列第五弹:文本+视觉,跨模态预训练新进展

编者按:机器推理要求利用已有的知识和推断技术对未见过的输入信息作出判断,在自然语言处理领域中非常重要。此前我们介绍了机器推理系列的概览,机器推理在常识问答、事实检测、跨语言预训练、多轮语义分析和问答任务中的应用,本文作为该系列的第五篇,将介绍微软亚洲研究院在跨模态预训练领域的研究进展。
近年来,自然语言处理(NLP)和计算机视觉(CV)两大领域不断碰撞和融合,衍生出很多跨模态研究课题(例如图片检索和图片问答等)。但由于这两个领域中的基础模型大都针对纯 NLP 或 CV 任务单独设计和训练(例如 NLP 中针对语言模型设计的 BERT 和 CV 中针对图片分类设计的 ResNet),这些模型无法很好地刻画语言和视觉内容之间的关联。从下游任务对应的标注数据中学习这类关联是解决方案之一,但由于标注开销大,该方案依然缺点明显。
针对上述问题,我们提出跨模态预训练模型 Unicoder-VL。借助通用领域跨模态预训练,该模型能够学习到语言和视觉间的内在关联,并用于生成语言和视觉的联合向量表示。实验证明,这种考虑了跨模态信息的联合向量表示能够很好地迁移到下游任务中,并取得很好的效果。接下来,本文首先简要介绍 Unicoder-VL 的模型,然后通过其在图片检索和图片推理问答中的应用,说明该模型对跨模态推理任务的作用。

Unicoder-VL 采用多层 Transformer 结构作为模型基础,基于自注意力机制学习语言与语言信息间的协同表示。我们设计了四种跨模态预训练任务,包括:1)基于文本的掩码语言模型;2)基于图像区域的掩码类别预测;3)图像文本匹配;4)图像特征生成。图1给出该模型示意图。
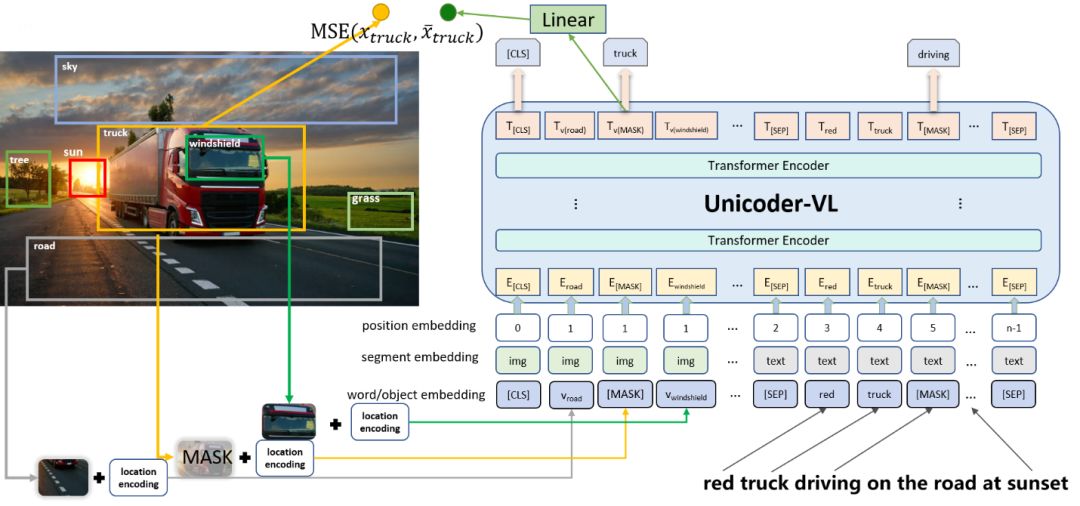
图1: Unicoder-VL 模型示意图
1)基于文本的掩码语言模型。该任务将预训练数据中的 token 以15%概率随机遮挡(mask)。为保证预训练与微调的一致性(微调时不做遮挡),每次选中的遮挡词以80%概率真正遮挡(替换成特殊符号 [MASK]),以10%概率随机替换为其他词,以10%概率保持不变。
2)基于图像区域的掩码类别预测。该任务首先使用 Faster R-CNN 提取图片中每个区域的特征,包括视觉特征(池化后的 ROI 特征)和空间特征(表示其空间位置信息的坐标值)。然后,将视觉特征和空间特征分别输入到全连接层并映射到和语言 token 维度相同的向量空间中,并与该区域对应的文本类别标签向量相加,得到每个图像区域对应的输入向量表示。和文本掩码类似,该任务对图像区域做遮挡操作,以15%概率选中遮挡区域,并在每次遮挡时以80%概率将特征随机替换为全0向量,以10%概率随机替换成其他区域对应的特征向量,以10%概率保持不变。
3)图像文本匹配。该任务基于图片-文本对随机采样负样例图片或文本,并让模型判别两者是否匹配。Unicoder-VL 保留了 BERT 中的特殊符号 [CLS]。该符号在最后一层的输出向量经过 MLP 层映射后,直接用于预测输入图文之间的匹配关系。这一任务用于学习图片与文本之间的全局信息对应关系。
4)图像特征生成。该任务为每个遮挡的图片区域生成一个特征向量。通过拟合该向量和图片区域对应的原始图像特征向量,使得模型能够更好地根据图文上下文信息进行图像信息补全。
Unicoder-VL 在经过预训练后,可以直接在下游任务上进行微调(fine-tune)。本文主要在图片检索和图片推理问答这两个任务上进行验证。
1)图像文本检索。我们选取 MSCOCO 数据集和 Flickr30k 数据集,并分别从图片检索文本和文本检索图片这两个角度评估 Unicoder-VL 在图片检索上的能力。由于预训练数据与这两个图文检索数据集之间的差异,需要在这两个数据集上进行一定程度的微调。所用到的数据构造则与预训练任务3)保持一致:即随机采样负例图片(或文本),让模型判别两者是否匹配。
实验结果如图2所示:zero-shot 表示 Unicoder-VL 在经过预训练但未经过微调的情况下,在测试集的性能表现;w/o pre-training 表示 Unicoder-VL 在未经预训练的情况下,直接用于下游任务训练的表现。前者证明经过预训练的 Unicoder-VL 具有很好的泛化迁移能力,后者证明 Transformer 结构即使没有经过预训练,同样在跨模态任务上有很强的建模能力。与 state-of-the-art 结果的比较说明跨模态预训练可以极大提高图片检索的能力。
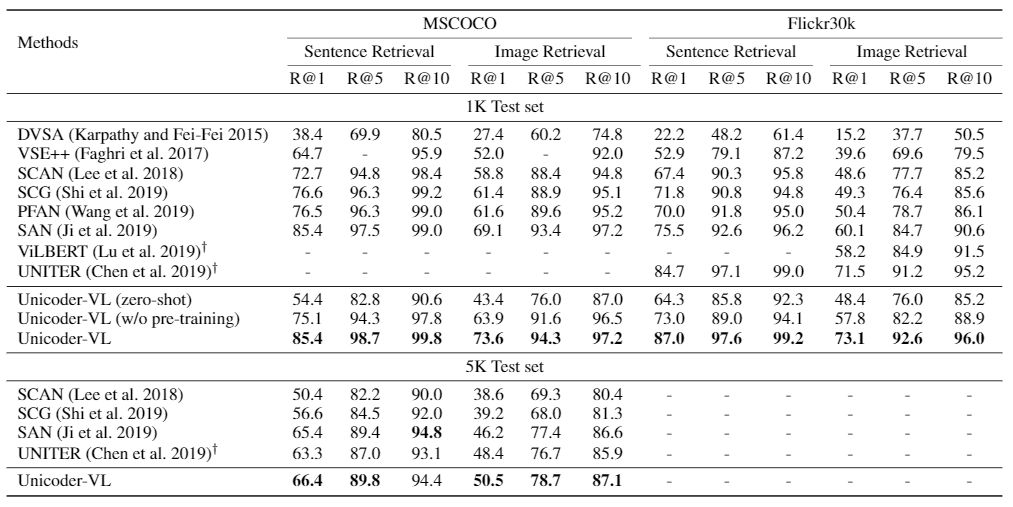
图2: Unicoder-VL 在 MSCOCO 和 Flickr30k 测试集的图片检索结果 (截止到2019.12.10)
2)图片推理问答(GQA)。图片推理问答任务 GQA 是由斯坦福大学提出的跨模态推理问答数据集。该任务在训练数据集中不但提供图片、自然语言问题和问题对应的答案,还提供图片对应的场景图(scene graph)以及每个自然语言问题对应的基于场景图的语义表示。由于该数据集中很大比例的问题都是复杂问题(即涉及到多跳转或多约束条件的自然语言理解),因此需要模型具备很强的推理能力,才能在该任务上个取得排名靠前的结果。
针对该任务,我们设计了一个基于 Unicoder-VL 的视觉问答推理模型(DREAM+Unicoder-VL)。该模型首先使用 Unicoder-VL 将输入自然语言问题和图片转化为对应的向量表示。然后,基于语义分析技术,将自然语言问题转化为对应的树结构语义表示,基于物体识别技术,从图片中抽取物体候选,并使用常识知识库对每个物体候选进行常识知识三元组扩展。接下来,对问题对应的语义表示和常识知识三元组集合进行向量编码,并结合 Unicoder-VL 输出的向量表示进行跨模态注意力计算。最后,基于融合后的跨模态混合信息进行答案排序。图3 给出该方法在 GQA 任务排行榜上的结果(截止到2020-01-10)。
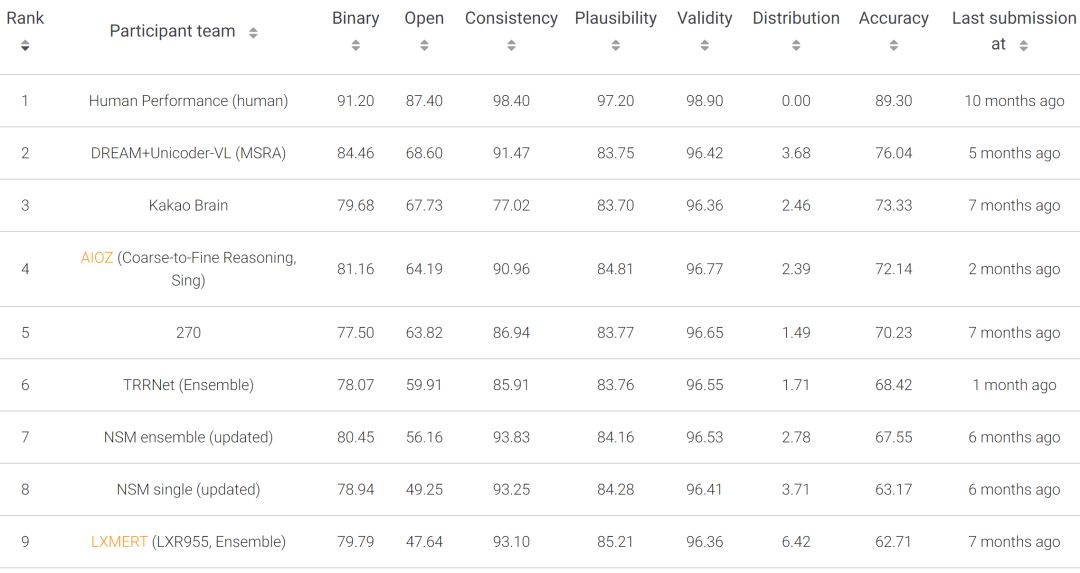
图3: Unicoder-VL 在图片推理问答 GQA 任务上的结果
除了为推理任务而专门设计的问题理解和图片理解外,实验证明使用 Unicoder-VL 比使用 BERT + ResNet 能够获得显著的性能提升。这充分说明跨模态预训练模型对跨模态任务的重要性和有效性。
本文介绍了微软亚洲研究院在跨模态预训练上的一个工作:Unicoder-VL,验证了跨模态预训练在图片检索和视觉推理问答任务上均能取得很好的效果。当然,这依然是机器推理研究中最初始的一步。在未来,我们将基于目前已有的预训练模型、知识图谱、规则以及海量开放领域数据,针对推理任务,尤其是小样本任务,进行更多的探索和尝试。
了解更多技术细节,请点击阅读原文查看论文:
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
链接:https://arxiv.org/pdf/1908.06066.pdf
本文作者:李根、段楠、周明
你也许还想看: