论文浅尝 | CAKE:一个用于多视图知识图谱补全的可扩展性常识感知框架

笔记整理:陈子强,天津大学硕士
链接:https://aclanthology.org/2022.acl-long.36.pdf
动机
以往的知识图谱补全仅仅依靠事实级别数据来预测实体之间缺失的关系,这样忽略了有价值的常识性知识。以往的知识图谱嵌入面临无效的负采样和事实层面链接预测不准确的问题。
贡献
亮点主要包括:
•我们提出了一个具有自动常识生成机制的可扩展的KGC框架,以从事实三元组和实体概念中提取有价值的常识。•作者设计了一个常识感知的负采样策略用于生成有效和高质量的三元组。同时,提出了一个多视图链接预测机制来提高KGC的准确性。•在四个基准数据集上进行的广泛实验说明了整个框架和每个模块的有效性和可扩展性。
模型
如下图所示,CAKE框架由三个部分组成:自动常识生成模块(ACG)、常识感知负采样(CANS)模块和多视图链接预测模块(MVLP)。首先,通过ACG模块从事实三元组中抽取常识。然后,CANS模块利用生成的常识生成高质量的负三元组。之后,将正样本和负样本送入KGE模型中学习实体和关系的嵌入。最后MVLP模块进行链接预测和答案实体预测。
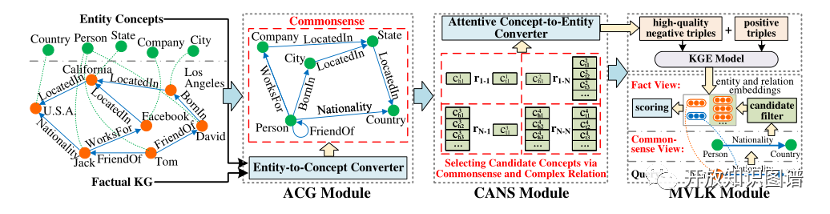
•AGC
只要存在一些与KG中实体相关的概念,AGC都可以从KG中自动生成常识。具体来说这是一个实体到概念的转换器,用概念来替换每个事实三元组中的实体。同时,常识中的关系包含了实例中的关系。事实三元组(David, Nationality, U.S.A.)可以转化为概念级三元组(Person, Nationality, Country)
•CANS
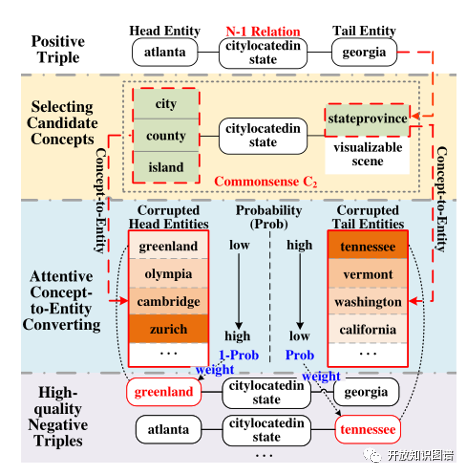
满足常识的负三元组比正三元组更具有挑战性,可以产生更有效的训练信号。作者利用TransH中定义的1-1、1-N、N-1和N-N来进行负采样。1意味着当给定关系和另一个实体时,实体是唯一的,相反,N表示在这种情况下可能有多个实体(非唯一实体)。作者提出了两种负采样策略。(1)唯一性采样。例如N-1关系中的尾实体,此时替换尾实体来进行负采样。如果替换的尾实体和原先的正确实体属于一个概念类型。那么这样负采样三元组可以被视为高质量的三元组。(2)非唯一性采样。例如N-1关系中的头实体,如果此时替换的头实体,由于头部实体的非唯一性,与正确实体属于同一概念的实体更有可能成为假阴性。因此,在训练中,这些负面的三联体的假阴性权重应该尽可能的低。
如下图所示:首先,负采样时头实体和尾实体需要根据常识来确定概念类型。然后,通过注意力概念到实体转换,将概念进行细化到实体来生成高质量的负采样三元组。
其中,头实体和尾实体的采样遵循以下分布:
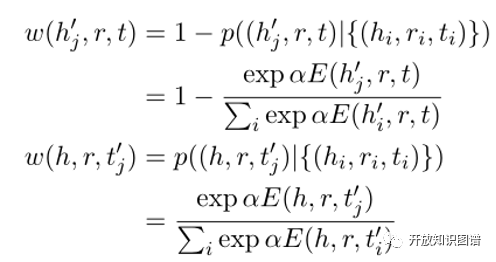
•KGE
通过CANS得到的负样本,训练KGE来学习实体和关系的表示。使用的损失函数如下:
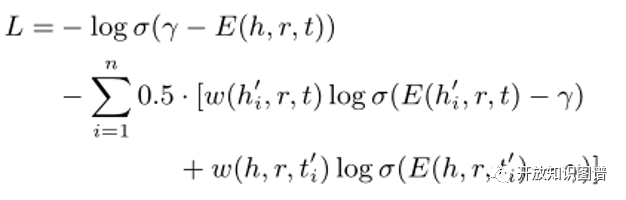
其中γ表示间距,σ表示激活函数。通过这个损失函数,拉大正三元组和负三元组之间的距离。
•MVLP
常识可以为链接的预测提供一个明确的范围,MVLP进行链接预测是一个由粗到细的过程。首先在常识视角下挑选出候选实体。在第二阶段,将候选的实体用KGE计算得分进行排序,从而选出排名较高的实体。
实验
在四个数据集上进行了实验,分别是:FB15K,FB15K237,NELL995和DBpedia-242。选择三个先进的KGE模型作为baseline分别是:TransE、RotatE和HAKE。所有模型的负采样大小被设定为16。学习率从0.0001到0.01中选择。Margin在{9, 12, 18, 24, 30}中进行调整。采样温度在{0.5, 1.0}中调整。实体和关系嵌入是随机初始化的。所有的实验都在Pytorch和GeForce GTX 2080Ti GPU上进行。评估指标采用的是MR、MRR和Hits@N
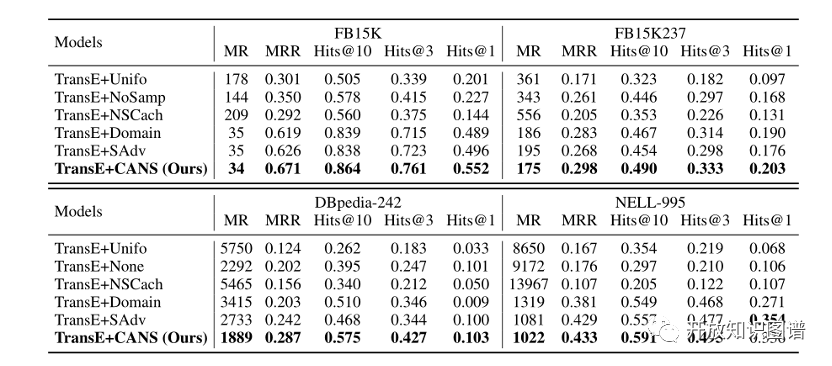
实验结果如下图所示,可以看到,CANS和MVLP模块都有效地提高了每个数据集上的基本模型的性能。此外,整个CAKE框架进一步促进了比每个单独模块更多的性能提升,并持续和显著地超过了所有的基线。与三个基线模型的性能平均值相比,我们的CAKE模型在FB15K、FB15K237、DBpedia242和NELL-995上的MRR提高了7.2%、11.5%、16.2%和16.7%。这些结果证明了将常识与原始KGE模型相结合的优越性和有效性。
总结
文章提出了一个新颖的、可扩展的常识感知的知识嵌入框架,它可以从带有实体概念的KGs中自动生成常识,用于KGC任务。利用生成的常识来产生有效的、高质量的负面三要素。另一方面,设计了一个从粗到细的多视图链接预测技术,从常识的角度过滤候选实体,从事实的角度输出预测结果。在四个数据集上的实验表明,与最先进的基线相比,作者提出的框架和每个模块的有效性和可扩展性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

