DeepMind为明年的AAAI,准备了一份各种DQN的混血
夏乙 编译整理
量子位 出品 | 公众号 QbitAI
🌈DeepMind公开了一篇最近投递到AAAI 2018的新论文,这篇论文的主角,依然是这家公司四年前就开始研究的DQN,配角,依然是雅达利(Atari)游戏。
DQN,全名Deep Q-Network(深度Q网络),是DeepMind在2013年NIPS Deep Learning Workshop发表论文提出的算法,让计算机有了靠视觉来玩雅达利游戏的新技能。
2015年,DeepMind完善了DQN,让这种算法在雅达利游戏上获得了更好的成绩,登上了Nature封面。

当然,这个算法之后也没有被闲置,DeepMind接连提出了DQN的各种优化版,虽然没有GAN变体那么多,但也足够让人眼花缭乱了。
哪种扩展性能更好?还有什么可以改进的地方?
DeepMind刚刚在arXiv上公开了最近投给AAAI 2018的论文,从DQN的诸多扩展中选择了6种,和原味DQN放在一起做比较了一下性能,还提出了一个新的变体:Rainbow。
DeepMind在论文中详细介绍了被选中的这6种扩展,共同点是他们自己都提出过相应的DQN变体。接下来,我们看一下论文中对它们分别做的简要介绍:
Double DQN通过解耦选择和引导动作的评估,解决了Q-learning估计偏差过高的问题;
优先体验重播(Prioritized DDQN)通过对能学到更多的过渡进行更多重播,提高了数据效率;
决斗网络架构(Dueling DDQN)通过分别呈现状态值和行为优势,来帮助在不同行为之间泛化;
A3C中所用的多步引导目标学习,可以改变方差折衷,将新观察到的奖励传播到早先访问的状态;
Distributional Q-learning(Distributional DQN)学习了折扣返回的类别分布,而不是估计平均值;
Noisy DQN使用随机网络层进行探索。
要详细了解这六种扩展,可以参考文末列出的论文地址,各取所需。
新变体Rainbow并没有在之前各种扩展的基础上,提出新的改动,而是将前面提到的6种变体整合到一起,成为一个单独的agent。
六种变体的混血Rainbow的性能和各位长辈相比如何呢?
DeepMind在arcade环境中,用57款雅达利2600游戏包括对原始DQN、DDQN、Prioritized DDQN、Dueling DDQN、A3C、Distributional DQN、Noisy DQN,以及Rainbow在内的所有agent进行了测试。
结果显示,Rainbow无论是在数据效能方面,还是在最终结果上,都明显优于各位长辈。
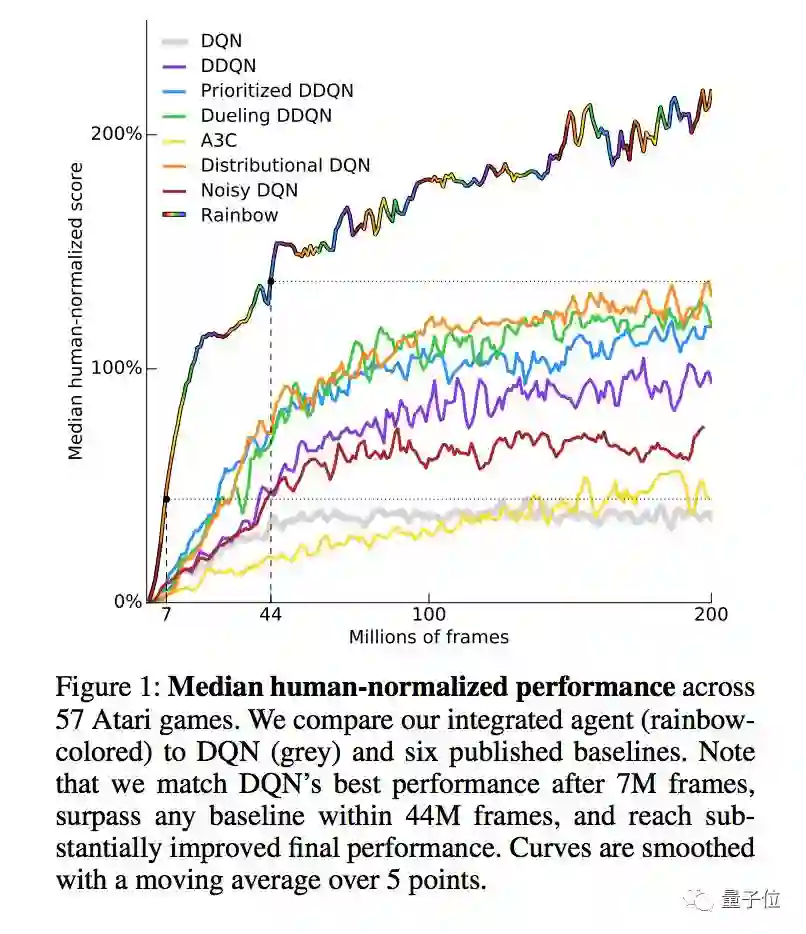
△ Rainbow与其他DQN变体的性能比较
上图中彩虹色的是混血Rainbow,灰色的是原味DQN。横轴表示训练用的帧数,纵轴表示算法在雅达利游戏上的“人类标准中位得分”,也就是agent的得分与中等水平的人类相比,是百分之多少。
用700万帧数据训练的Rainbow,性能就与原始DQN的最佳性能相当;经过44万帧的训练,Rainbow性能就超越了此前所有的DQN变体。
Rainbow的最佳性能与其他变体相比,也有显著的提升。在agent的最终测试中,训练结束后,Rainbow在以随机数开始游戏的模式下,中位得分为223%,在人类开始游戏的模式下,得分为153%。
除了和长辈比较之外,DeepMind还尝试了从Rainbow中分别去掉各种算法组件,看会对性能有怎样的影响。
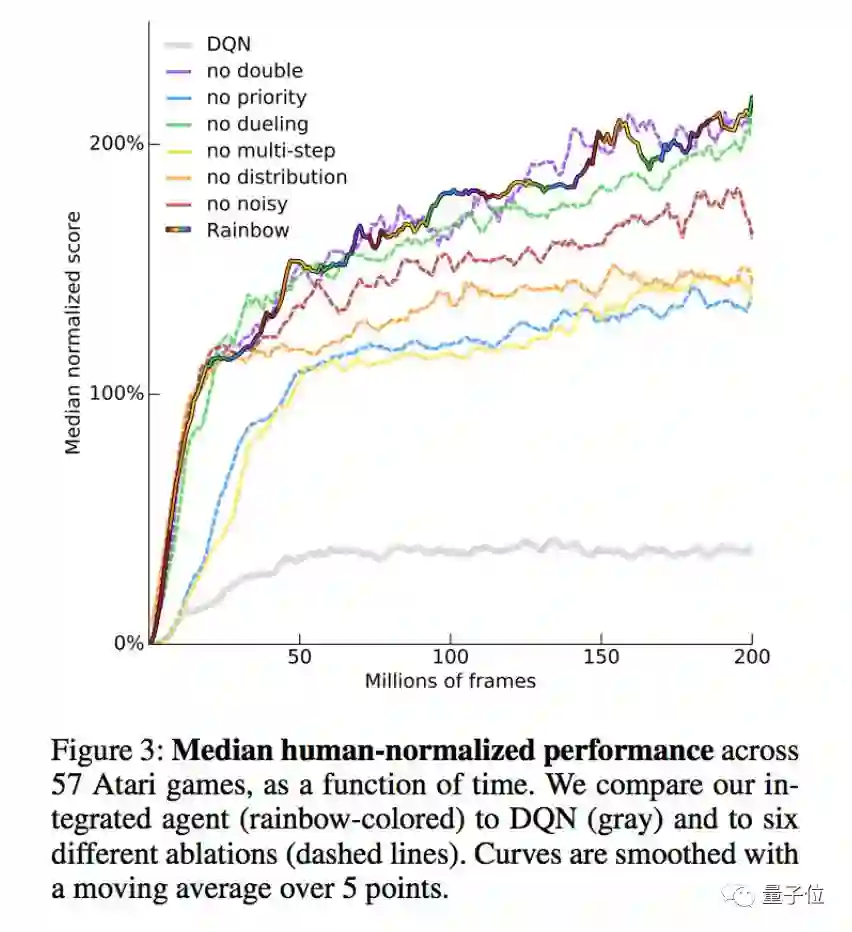
△ Rainbow和缺失各种组件之后的性能比较
总的来说,去掉决斗网络或者Double Q-learning对Rainbow的性能没有多大影响。不过,将各个游戏分开来分析,我们可以看出,不同的游戏对于组件的需求不太一样。
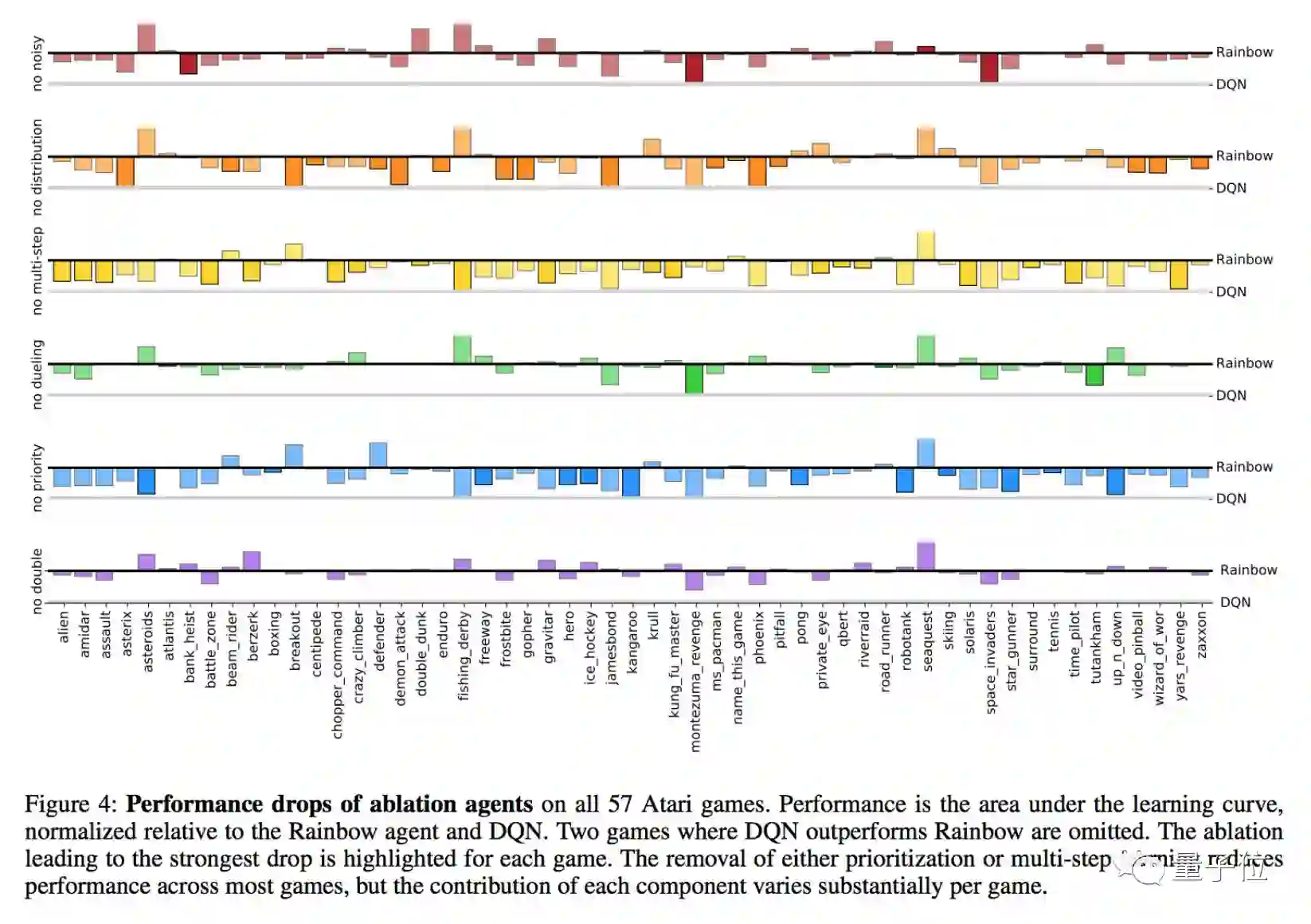
△ 缺失各种组件在不同游戏上对agent性能的影响
另外,DeepMind还记录了这些agent究竟有多少种游戏能超过中等水平人类。
△ Rainbow及其他DQN变体得分超过普通人类20%、50%、100%、200%、500%(从左到右)的游戏数目
上图第一行,是Rainbow与各种DQN变体的比较,第二行,是从Rainbow中分别去掉各种组件对agent性能的影响。
附:各种DQN论文
刚刚提交给AAAI 2018的Rainbow论文
Rainbow: Combining Improvements in Deep Reinforcement Learning
Matteo Hessel, Joseph Modayil, Hado van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, David Silver
https://arxiv.org/abs/1710.02298
2013年DQN首次提出
Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller
https://arxiv.org/abs/1312.5602
2015年的Nature论文
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg & Demis Hassabis
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
Double DQN
Deep Reinforcement Learning with Double Q-learning
Hado van Hasselt, Arthur Guez, David Silver
https://arxiv.org/abs/1509.06461
Prioritized DDQN
Prioritized Experience Replay
Tom Schaul, John Quan, Ioannis Antonoglou, David Silver
https://arxiv.org/abs/1511.05952
Dueling DDQN
Dueling Network Architectures for Deep Reinforcement Learning
Ziyu Wang, Tom Schaul, Matteo Hessel, Hado van Hasselt, Marc Lanctot, Nando de Freitas
https://arxiv.org/abs/1511.06581
A3C
Asynchronous Methods for Deep Reinforcement Learning
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, Koray Kavukcuoglu
https://arxiv.org/abs/1602.01783
Distributional DQN
A Distributional Perspective on Reinforcement Learning
Marc G. Bellemare, Will Dabney, Rémi Munos
https://arxiv.org/abs/1707.06887
Noisy DQN
Noisy Networks for Exploration
Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, Shane Legg
https://arxiv.org/abs/1706.10295
— 完 —
加入社群
量子位AI社群9群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot3入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot3,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态


