怎样扩充大数据?你需要了解的第一个联邦学习开源框架FATE
机器之心原创
作者:思源
随着机器学习模型应用到生活生产中,如何获得更多的数据训练更好的模型成为了关键,而有助于解决该问题的联邦学习也就受到越来越多的关注。在本文中,我们将一同了解联邦学习,概览第一个联邦学习开源框架 FATE。
近日,微众银行将联邦学习开源框架 FATE(Federated AI Technology Enabler)贡献给 Linux 基金会,并希望通过多方维护令该项目更加强大。同时,中国人工智能开源软件发展联盟(AIOSS)发布了我国第一个关于联邦学习规范标准,这些都表明联邦学习从理论到实践都在快速提升。
FATE 开源地址:https://github.com/WeBankFinTech/FATE
为了解第一个联邦学习开源框架 FATE,机器之心采访了微众银行 AI 部门的副总经理陈天健,他介绍了联邦学习的开源现状以及技术过程。与此同时,7 月 19 日市北•GMIS 2019 大会上,微众银行首席人工智能官杨强教授也将针对联邦学习这一主题发表主旨演讲,为我们介绍更多关于联邦学习的内容。
为什么联邦学习如此重要
早在 2018 年,杨强教授就向机器之心介绍过联邦迁移学习,他表示面对欧盟的「数据隐私保护条例(GDPR)」,我们应该思考如何把 GDPR 囊括在机器学习框架之内,而不是绕着它走。联邦学习就是一种很好的方法,它希望在不共享数据的前提下,利用双方的数据实现模型优化。
假设两家公司想要建立一个用户画像模型,其中部分用户是重合的。联邦学习的做法是,首先通过加密交换的手段,建立用户的识别符(identifier)并进行沟通,在加密状态下用减法找出共有的部分用户。因为关键用户信息并没有得到交换,交换的只是共有的识别符,因此这并不违反数据隐私保护条例。
然后,双方将这部分数据提取出来,将各自拥有的同样用户的不同特征作为输入,迭代地训练模型、交换参数的过程。杨强教授等研究者证明了给定模型参数,双方不能互相反推出对方拥有的、自己没有的特征,因此用户隐私仍然得到了保护。在不违反 GDPR 的情况下,双方的模型性能都得到了提高。
在数据越来越隐私与重要的今天,联邦学习越发引人注目。机器学习学者除了关心算法的准确率、效率之外,也该将思考的维度上升到管理与合规的角度。
为什么我们需要联邦学习框架与标准
从前面可以了解,联邦学习会有它的特殊性,即它主要用于多方协同训练模型,这样联邦学习就更关注开源社区。微众银行 AI 部门副总经理陈天健表示,既然是多方协作的框架,那么我们就必须说明它的安全性与保密性,并且各方都能快速对其进行验证,这是闭源软件办不到的。
既然联邦学习框架需要开源,那么就会有维护主体,以前联邦学习项目都是微众银行维护的,微众会将业务上使用的一些联邦学习技术开源出来。但是如果想要构建更完美的生态,单一主体是很难支撑的,因为联邦学习本身就是面向合作的机器学习技术。因此,陈天健说:「微众银行将 FATE 托管给 Linux 基金会,它将成为一个基金会项目,因此也就变成了由项目技术委员会、企业及组织联合开发的状态,以此保证联邦学习框架的稳定性与延续性。」
对于开发者而言,以后 FATE 项目将变得越来越好用、越来越稳定。但是随着联邦学习更加普及,目前的开源框架肯定是有局限的,这就要求开发者根据具体业务需求修改 FATE 或者重新写框架。这也就是微众银行携手 AIOSS 推出联邦学习标准的原因,它规范了我们对联邦学习的理解与接口标准。
如果有一个完善的标准,那么不同的开发者并不一定只能使用 FATE 作为联邦学习系统的实现,我们可以在遵循工业标准下构建自己的实现。这样的系统会有比较强的兼容性,可以与其它使用 FATE 的项目或遵循相同标准的系统互联互通。陈天健说:「整个生态一定是开放的,并不是所有人都必须使用 FATE 作为联邦学习系统,我们的核心目标还是希望大家能互联互通地进行大数据和 AI 方面的合作。」
联邦学习到底怎样工作的
那么联邦学习的简要过程到底是什么样的?在整个联邦学习过程中,加密训练是最为核心的部分,各个数据方需要基于本地数据和其它方的训练信息完成模型的训练。
如果参与联邦学习的各方数据结构和特征空间相同,加密训练也有比较简单和直观的方法,例如谷歌有尝试以梯度加密聚合为基础的联邦学习,他们会如同分布式训练一样计算局部梯度,然后将加密的局部梯度传入参数服务器,参数服务器再统筹加密的局部梯度,并将解密的全局梯度传入各个数据方,从而达到更新模型的效果。
但这种直观方法也有很难处理的缺陷,它要求各数据方的数据结构都是一样的,很难满足大数据合作领域的需求。陈天健介绍了一种针对更常见的异构特征空间场景的加密训练方法。如下所示,A 和 B 都有各自的数据,它们希望在不交换数据的情况下训练更优秀的模型。
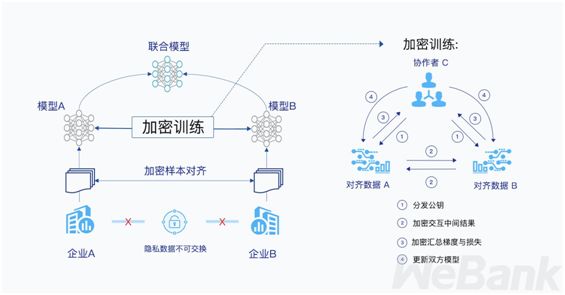
总体上,该加密训练过程从分发公钥到更新模型可以分为四步。我们先假设训练的模型都是简单的线性回归,即 u = Θx,其中Θ为权重矩阵、x 为特征向量、u 为预测结果向量。
如下所示以 A 为例,它会根据自己的数据计算预测值 u_A,但这个时候 u_A 只使用了一半的特征,它并不能作为模型的预测结果,它还要加上 B 的计算结果 u_B 才是最终结果。因此现在 A 会把中间结果 u_A 加密,并传递给 B。这就是第二步传递的中间结果,[[u_A]] 表示 u_A 的加密输出。
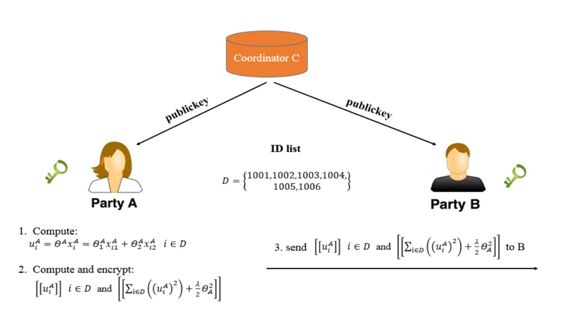
现在 A 和 B 都有完整的预测结果 [[u_A]] +[[ u_B]],虽然结果是经过加密的。有了预测结果就能计算损失函数,但这里会计算一个额外的残差项 [[d]] = [[u_A]] + [[u_B - y]],它相当于梯度计算中的系数。例如常规线性回归的损失函数为 L = (Θx - y)^2,那么 dL/dΘ = 2 * (Θx - y) * x,这里经过加密的残差项 [[d]] 就相当于 x 前面的系数。
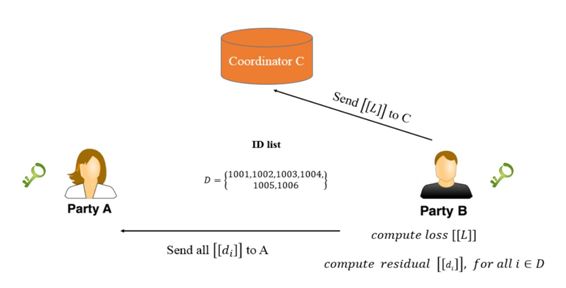
如下所示,借助相互反馈的残差项,A 和 B 能快速算出局部加密梯度,例如 A 的加密梯度为 [[∂L/∂Θ_A]] = [[d]] * x_A。现在加密的局部梯度就可以传递到协作者 C 了。
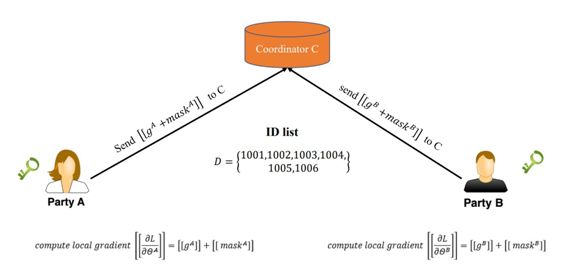
最后,协作者 C 会将解密后的梯度传回各个数据方,数据方也就能使用对应的梯度更新自己那一部分模型。值得注意的是,因为各个数据方都只有部分特征与权重,相当于只有部分模型。所以这里需要一个 Mask 以告诉各模型到底都需要更新哪些东西。
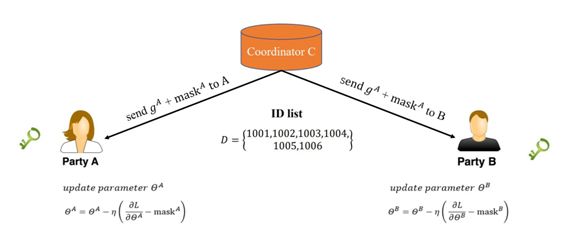
在训练的最后,A 和 B 都不知道对方的数据结构,并且只能获得自己那一部分特征需要的参数。所以 A 和 B 之间并没有直接传递数据相关的信息,它们间的通信也是非常安全的。在这样的联邦学习下,我们的特征变多了,当然我们的模型效果就更优了。
第一个联邦学习开源框架 FATE
那么我们该怎样完成加密训练呢,难不成还需要从头开始写?这就需要 FATE 来帮忙了。
FATE 是微众银行最先维护的一个项目,它提供了一个安全的计算框架以支持联邦学习算法。它实现了基于同态加密和多方计算的安全计算协议,并支持联邦学习架构与各种机器学习算法的安全计算,包括逻辑回归和梯度提升树等经典 ML 算法,也包括深度学习和迁移学习等前沿研究。
陈天健说:「FATE 最主要的特征和优势在于,它源自微众银行进行大数据风控建模的实际场景,因此 FATE 是一个生产系统,它的可扩展性非常优秀。FATE 自带一个分布式计算框架,它的稳定性肯定比一般的研究型项目好很多,而且预测和训练也都集成在了一起。」
FATE 并不只有一个框架,它还带了一些经典算法,包括线性回归、提升树和其它分类模型等。这些都得到了大量实践证明,是工业上很常见的方法,所以如果开发者不愿意从头构建,那么就可以直接使用这些方法,或者在这些方法上做修改。

FATE 项目中提升树算法的教程页面,它不仅展示了怎样运行单机版,还介绍了如何运行计算集群版。
陈天健表示,在加入 Linux 基金会后,技术委员会也在对项目进行进一步的规划与拆分。他们会把用于特定运算框架和特定集群的支持分离出来,并把它们变得通用,从而支持常用的计算框架与大数据基础设施。此外,在技术更新上,FATE 也规划对分布式异构计算进行加速,对于 GPU 和 FPGA 的支持也都在日程中。
最后,FATE 还在不停地提升中。陈天健说:「联邦学习的应用主要受限于网络带宽与芯片的计算力,我们现在主要还是在数据中心做联邦学习,这两者都能比较好地满足。如果未来需要在手机等边缘设备上做联邦学习,那么更大带宽的通讯技术和更强劲的边缘算力必不可少。我非常看好 5G 通讯技术,它能为联邦学习带来足够的带宽,同时随着手机芯片越来越强,联邦学习落地到广大移动端设备并不会太远。」
首届「市北•GMIS 2019 全球数据智能峰会」将于 7 月 19 日- 20 日在上海市静安区举行,杨强教授特将在峰会上分享更多有关联邦学习的精彩内容。点击「阅读原文」立即报名,在现场与顶级大牛近距离接触交流。
本次会议的联合主办方上海市市北高新技术服务业园区是上海市唯一的大数据产业基地,已经集聚了全上海 30% 的大数据企业,正全力打造上海大数据和人工智能产业的「内核腹地」,朝着「中国大数据产业之都、中国创新型产业社区」目标迈进。

市北·GMIS 2019全球数据智能峰会于7月19日-20日在上海市静安区举行。本次峰会以「数据智能」为主题,聚焦最前沿研究方向,同时更加关注数据智能经济及其产业生态的发展情况,为技术从研究走向落地提供借鉴。
本次峰会设置主旨演讲、主题演讲、AI画展、「AI00」数据智能榜单发布、闭门晚宴等环节,已确认出席嘉宾如下:

我们为广大学生用户准备了最高优惠的学生票,点击阅读原文即刻报名。



