学界 | 循环神经网络自动生成程序:谷歌大脑提出「优先级队列训练」
选自arXiv
作者:Daniel A. Abolafia、Mohammad Norouzi、Quoc V. Le
机器之心编译
参与:路雪、李泽南
由谷歌大脑 Quoc V. Le 团队提交的论文提出了一种使用循环神经网络进行程序合成的新方法——优先级队列训练(PQT)。目前,该论文已提交 ICLR 2018 大会,正在接受评议。
GitHub 链接:https://github.com/tensorflow/models/tree/master/research/brain_coder
自动程序合成是一项具备广泛应用潜力的任务。传统方法(如 Muggleton & de Raedt (1994); Angulin (1987))通常不使用机器学习,因此需要编程语言和手动启发式方法方面的专业知识来加速底层组合搜索。为了创建无需领域专业知识的更通用的编程工具,近期大量研究开始开发神经模型,可促进某种形式的内存访问和符号推理(如 Reed & de Freitas (2016); Neelakantan et al. (2016); Kaiser & Sutskever (2016); Zaremba et al. (2016); Graves et al. (2016))。尽管这些研究取得了很大成果,但是没有一种方法能够用富于表达性的编程语言合成源代码。
近期出现了多项使用神经网络从输入-输出示例导出程序的成功尝试(Riedel et al., 2016; Bunel et al., 2016; Balog et al., 2017; Parisotto et al., 2016),甚至从非结构化文本生成程序(Parisotto et al., 2016),但是它们通常使用限制性编程语法,需要真正程序或正确输出形式的监控信号。与之相反,本论文提倡使用富于表达性的编程语言 BF,其语法简单,且图灵完备。此外,本论文旨在使用强化学习合成程序,只需要一个 solution checker 就可以计算奖励信号。你可以将代码长度罚分或执行速度纳入奖励信号,进而搜索高效的短程序。因此,相比训练过程中需要程序或正确输出的其他方式,基于奖励的程序合成具备更高的灵活性。
为解决基于奖励信号的程序合成,本论文研究了两种不同方法。第一种方法是策略梯度(PG)算法(Williams, 1992),训练一个循环神经网络(RNN)来生成程序,每次生成一个 token。然后执行该程序并打分,奖励反馈将返回至 RNN 以更新参数,这样随着时间,生成的程序将越来越好。第二个方法是一种欺骗性的简单优化算法——优先级队列训练(priority queue training,PQT)。训练过程中保持 K 个最优程序的优先级队列可见,对队列中前 K 个程序使用对数似然目标函数来训练 RNN。然后从 RNN 中采样新程序,更新队列,进行迭代。本论文还对比了遗传算法(GA)基线(之前证明其可生成 BF 程序,Becker & Gottschlich (2017))。令人惊讶的是,论文发现 PQT 算法显著优于 GA 和 PG 方法。
论文在 BF 编程语言上评估了提出方法的有效性。BF 语言是图灵完备的语言,仅有 8 条指令。BF 语言的极简语法使之易于生成语法正确的程序,这与比较高级的语言相反。本论文考虑了不同字符串操作、数值和算法任务。结果显示文中考虑的所有搜索算法在大部分任务中都能够找到正确的程序,而论文提出的方法是最可靠的,因为它是在最随机的种子上找到解决方案的,且可以解决的任务也是最多的。
本论文的主要贡献:
提出一个程序合成学习框架,训练过程中仅需要奖励函数(无需真正程序或正确输出)。此外,论文提倡使用简单且富于表达性的编程语言 BF 作为程序合成的基准环境(还可以参考 Becker & Gottschlich (2017))。
受 Liang et al. (2017) 论文的启发,本论文使用优先级队列和 RNN 的搜索算法进行实验,并展示了将优先级队列作为 RNN 的训练目标是一种高效、稳定的方法。
提出一种实验方法来对比不同的程序合成方法,包括遗传算法和策略梯度方法。该方法评估了每个合成方法的平均成功率,并提供了一种调整超参数的标准方法。使用该方法,研究者发现使用优先级队列训练的循环神经网络优于基线模型。
方法
研究者实现了一个程序生成模型,即每次输出一串 BF 语言字符串的 RNN。图 2 展示了 RNN 模型,允许用自回归方式采样 BF 字符串,即将前一个预测作为下一步的输入。第一步的输入是特殊的 START 符号。RNN 生成特殊的 EOS 符号时终止,该符号表示字符串终结,或者程序长度超出预先指定的最大长度。每个时间步的预测通过多项式分布(一种多个时间步共享权重的 softmax 层)进行采样。程序序列的联合概率是所有 token 概率的积。
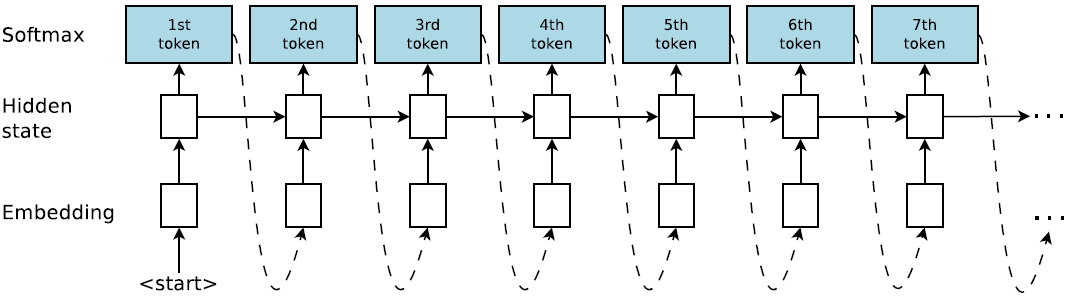
图 1:合成器图示。合成器是一个循环神经网络,以自回归的方式生成程序。
表 3 展示了相同的算法加上均匀随机搜索的成功率,以及训练和评估测试案例的成功率。研究者还在最后一行列出平均值,进行各列之间的整体对比。从表中可知,根据训练和评估平均值,PQT 要明显优于 PG 和 GA。PG+PQT 仅与 PQT 相当。由于过拟合,在很多情况下评估成功率要低于训练成功率。
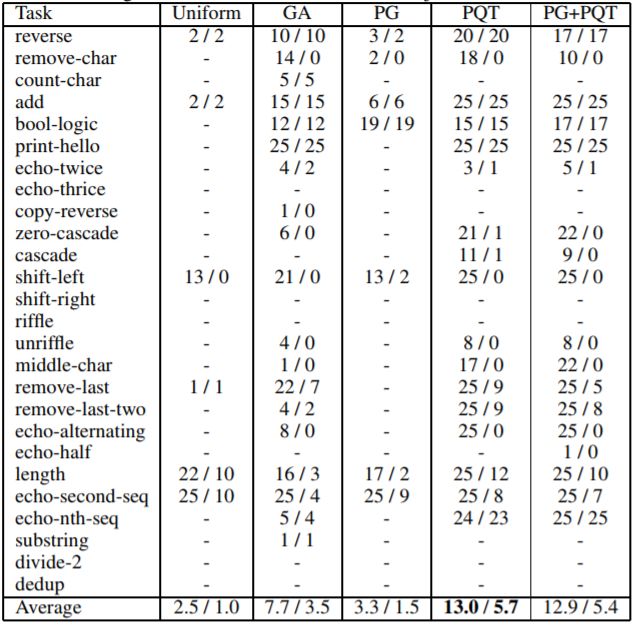
表 3:当执行程序的最大数(max NPE)是 20M 时,在所有任务上合成方法成功的数量(25 个之中)。单元格中有斜杠分割的两个数。第一个数是训练测试案例中的成功数量,第二个数是留出评估测试案例中的成功数量。对于无法合成满足某个任务训练案例的方法,用短线进行标记。

表 4:用于已解决任务的合成 BF 程序。所有程序由原本的智能体发现,并且没有任何代码字符被删除或改变。注意,一些程序与任务产生过拟合。我们标红了代码方案过拟合的所有任务(经过手动检查确定)。
论文:Neural Program Synthesis with Priority Queue Training

论文链接:https://arxiv.org/abs/1801.03526
摘要:我们认为程序合成任务是在程序的输出中存在一个奖励函数,目标是找到奖励最大的程序。我们采用了一种迭代优化方案,在这种方法中,我们在目前已生成的 K 个最佳程序数据集上训练一个 RNN 模型。随后,我们合成新的程序,并通过 RNN 采样将它们添加到优先级队列中。我们使用一种简单但富于表达性的图灵完备语言 BF,对该算法(优先级队列训练,PQT)与遗传算法和强化学习基线进行了对比。实验结果证明简单的 PQT 算法显著优于基线。通过在奖励函数中添加程序长度罚分,我们就可以生成简短、人类可读的程序。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论




