谷歌推出分布式强化学习框架SEED,性能“完爆”IMPALA,可扩展数千台机器,还很便宜


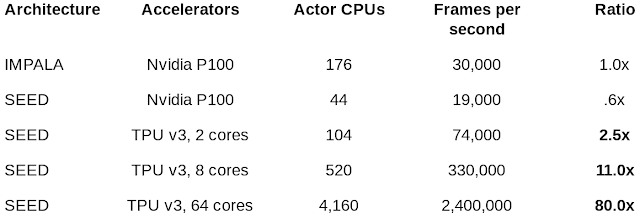
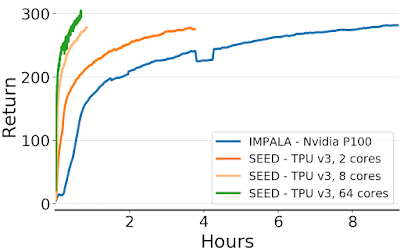


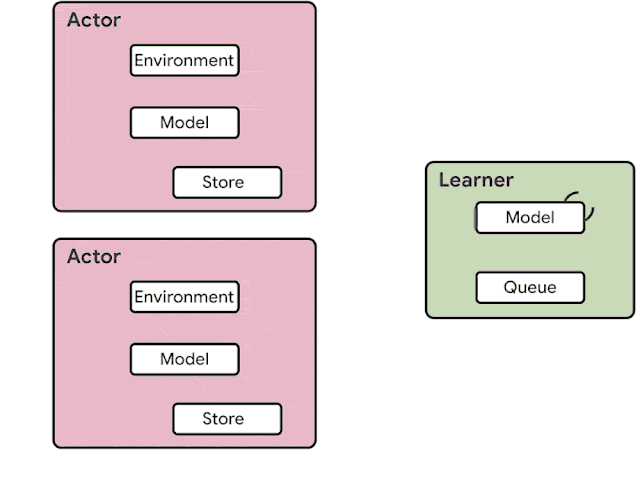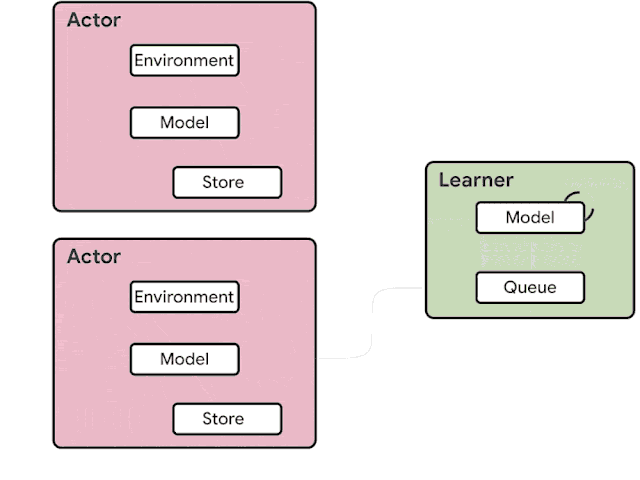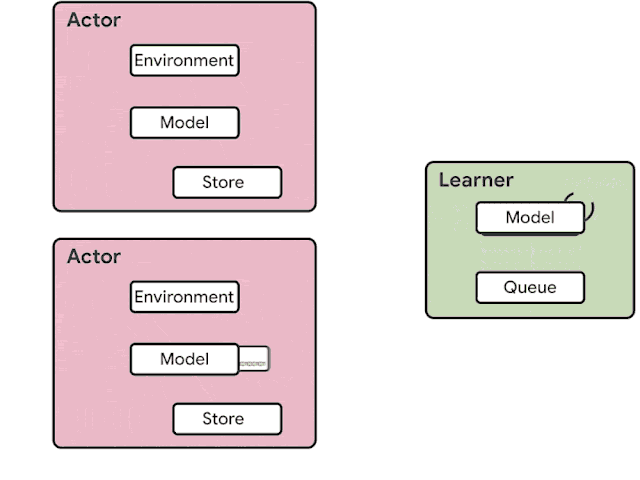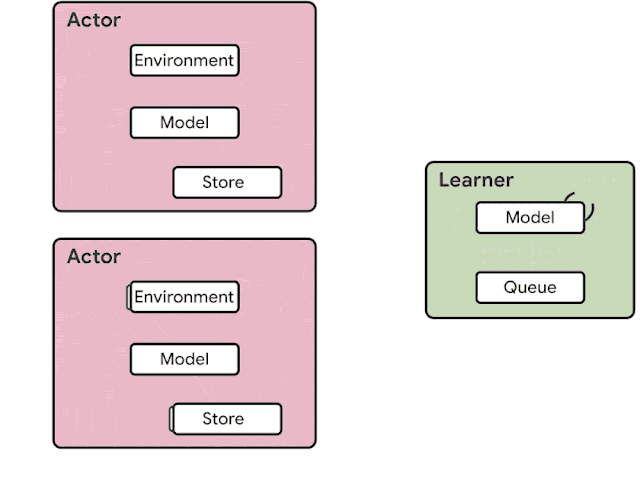
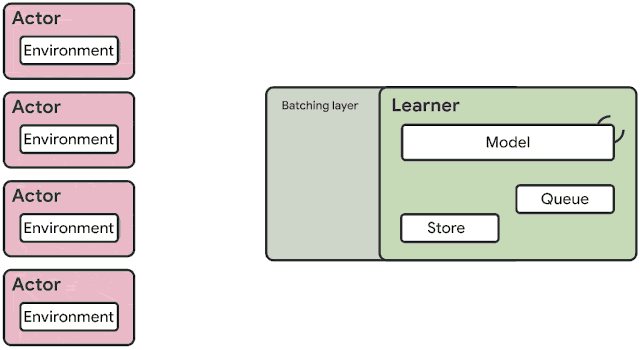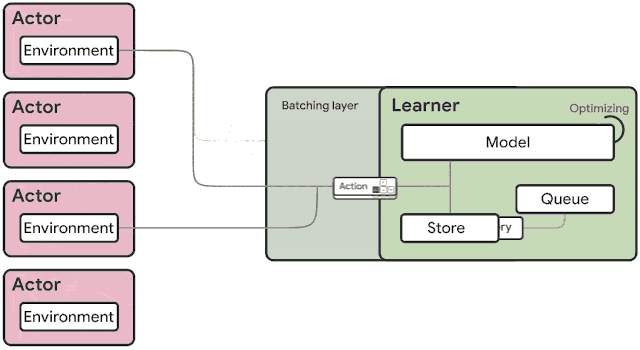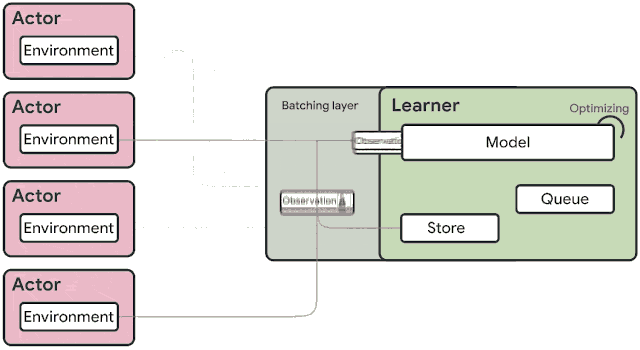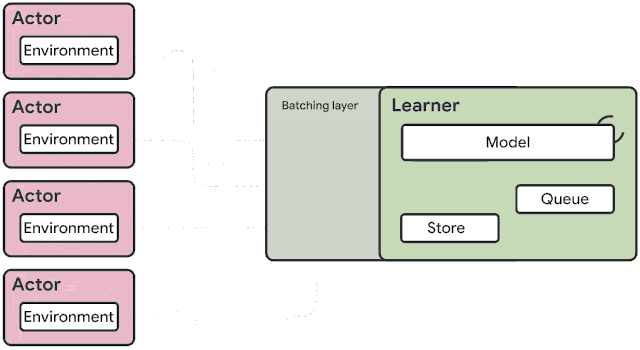
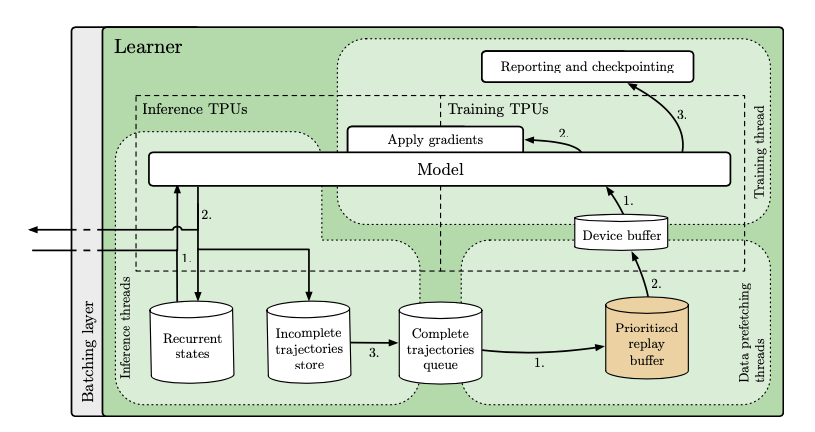
火爆的图机器学习,ICLR 2020上有哪些研究趋势?
03. Spotlight | 组合泛化能力太差?用深度学习融合组合求解器试试
04. Spotlight | 加速NAS,仅用0.1秒完成搜索
01. Poster | 华为诺亚:巧妙思想,NAS与「对抗」结合,速率提高11倍
《2020科技趋势报告》重磅发布,点击下方图片跳转查看全文及解读!



登录查看更多
相关内容
Arxiv
4+阅读 · 2018年1月11日


相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月11日