AI&Society|3万个村民的社会网络因何连接?

2017年11月26日,AI&Society第二期在深圳华侨城创意园linkspace的分享空间里举办。围绕“大连接与大数据”这一主题,来自耶鲁大学的计算社会科学博士施永仁分享了计算社会学方面的研究实例并和在场嘉宾做了相关探讨。

本次活动由北京师范大学系统科学学院教授,集智俱乐部、集智AI学园创始人张江主持

主讲人:施永仁
新一代的人机共生社会需要怎样的社会科学?
社会科学的研究成果又如何促进人工智能的发展?
人工智能会怎样影响人类社会?
社会科学研究又如何借鉴人工智能领域的最新成果?
以下是施永仁博士的分享:
科学的政治偏向性
政治两极化逐渐渗透到了美国社会的各个方面,科学领域似乎成为了一个新的意识形态斗争的战场。为了量化意识形态对于大众消费和传播科学知识的影响,我们通过分析数百万册亚马逊图书的购买纪录,让志愿者对1400本政治书籍进行意识形态标注,然后去推断网络中其他书籍的意识形态倾向,并利用可视化软件呈现了这些书籍的从购买网络。如图所示:

其中,每个节点表示一本书,连边表示两本书曾经被同一个用户购买。红的节点代表的是倾向保守主义(conservative)的书,而蓝色的节点是倾向自由主义(liberal)的书。
此外,我们还对书籍按照学科进行了聚类,并研究了不同政治偏好的购买者对学科书籍的购买也有偏向性。我们发现,偏向liberal的人同时也偏好基础科学的图书,而偏向conservative的人更偏好应用科学的图书。如图所示:
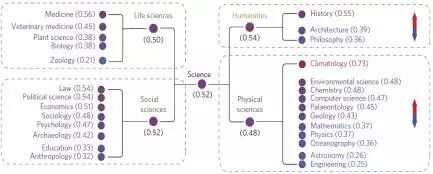
该图展示了图书归类后的每一个领域平均的“政治倾向性”,颜色越红(括号中的数值越大)的学科越偏向于保守主义。我们看到,类似气象学(Climatology)就是典型的“保守主义者”,工程则是比较典型的“自由主义者”。而当我们对所有书进行平均的时候,我们看到整个科学更加“政治中立”(0.52)。但是,与此相对,人类学和社会学更加”保守“,而生命科学和物理科学则更加“开放”。
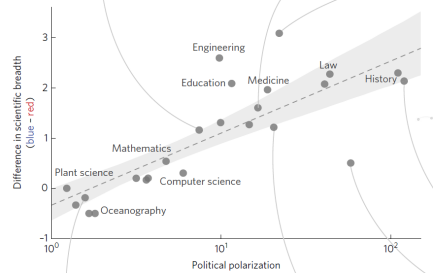
进一步,我们还可以将每个学科的政治倾向性和政治倾向的差异性绘制成如上图所示的样子。随着政治倾向性逐渐变得保守,学科内部的差异性也会变大。
[小结]上面是我们使用大数据研究社会计算科学的一个例子。我们的计算社会科学更偏向于把人类的行为和社会的交互转换成这样一种拓扑网络的构想,而且我们研究了仅仅局限于某一种的社会交互。所以我在做这个社会网络分析的过程当中经常会问自己这样一个问题,就是社会连接到底是什么?什么样的东西能够构成一个社会连接?
大规模田野实验揭示人类社会关系
我们在做大数据分析的时候,往往是把整个社会关系的内容剥离出来,我们只是去从非常结构化的角度去研究网络拓扑结构或者这个拓扑结构是如何变化的。但是我们很少关心的问题是某一个连接的意义是什么?它是在什么样的环境下面产生的?这种连接和另一种连接的区别是什么?因此,也就有了这样一个大规模田野实验的构想和实践。
我现在正在做的工作是去洪都拉斯北部的一百多个村庄进行田野调查,我们收集了将近3万个村民的社会网络,包括不同种类的网络,比如亲属关系、朋友关系、金钱交易关系、卫生咨询关系、组织从属关系等。为了更高的精度,我们需要先派一个小队到每家每户去采集每个人的照片信息,然后我们第二次去村庄的时候就给每个村民看一系列的照片,让他们指认你是否认识这个人,TA和你的关系是什么,比如说是你的父母?谁是你最要好的朋友?等等,整个过程还是非常辛苦的。
这里我们可以看到14种不同关系下的网络:
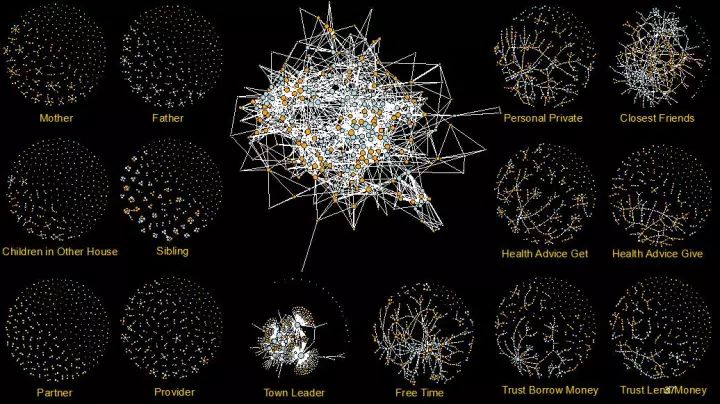
我们看到,两个人有相同的属性,就更容易成为朋友,更容易有一条网络的边存在他们两个人之间。在这样一个社会网络上,我们的研究更加关注的是,关于健康,新的知识、新的消息如何更好的传播。
在这里,我们把眼光放在三个因素上:
一、节点边属性的多样性,一个节点边的种类更多,就更容易获得多样的健康知识;
二、另一个是边的分布,如果这两个人有同样数量的边和同样种类的边的话,那边的分布会决定你到底能够获得什么样的信息,什么样的新的知识;
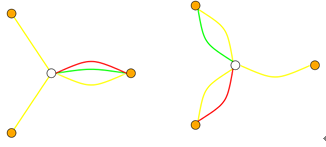
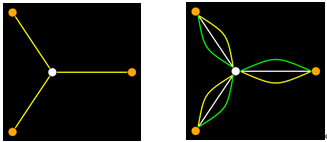
三、第三个因素是分散性,如下图:
比如说右边的人有三个朋友,但这三个朋友之间毫无关系;左边的人同样有三个朋友,但他们之间都存在着社会关系。这样的话,左边这个人所获得的新的知识的概率就大大减少,因为他们的信息都是重叠的,而右边的人就可能获得不同的信息,从网络的不同的位置获得新的信息。
第二个大问题就是如何去用社会网络干预人们的行为,就是最大化社会利益。比如说,如果要干预一个人群,我们尽可能去干预那些网络中中心度比较高的人,而不是干预在网络边缘的人。因为如果A这个人接受了某种创新,那很容易他附近的人员也会跟随着接受某一种创新。进而,我们可以去讨论如何去预防流行病的爆发,如何去筛选样本来种植疫苗?但是,其实这是一个非常困难的问题,为什么?因为如果要把整个网络都画出来的话,是非常费时费力的一件事,问出所有的人的社会关系几乎是不可能的;而且在很多情况下,我根本不知道如何去找到他们。
所以在这种情况下,用一些比较有效的基于网络的干预手段,那可能会起到事半功倍的效果。所谓的干预就包括发放卫生产品,发放使用说明或教育小册子等。我们选取了5%的村民,同时每个参与的村民都会给四张选票,可以发给其他村民,这样的话得到选票的村民也可以参与到项目中来,从而接受药物的发放。
问题的关键是我们应该去干预谁。我们有5%的人口选择,但我们有三种不同的干预方法:
第一个方法是根据内度数,找到内度数最大的节点对他们进行干预(也就是选择那些获得村民推荐比较多的村民作为干预对象);
第二个方法是随机选取节点,在网络里随机去干预5%的人口。
第三个方法是随机节点的朋友:我们先找到5%的随机节点,然后让他们提名他们的朋友,进而去干预这些朋友。最后的实验结果表明,以朋友提名的网络策略,是最行之有效的。
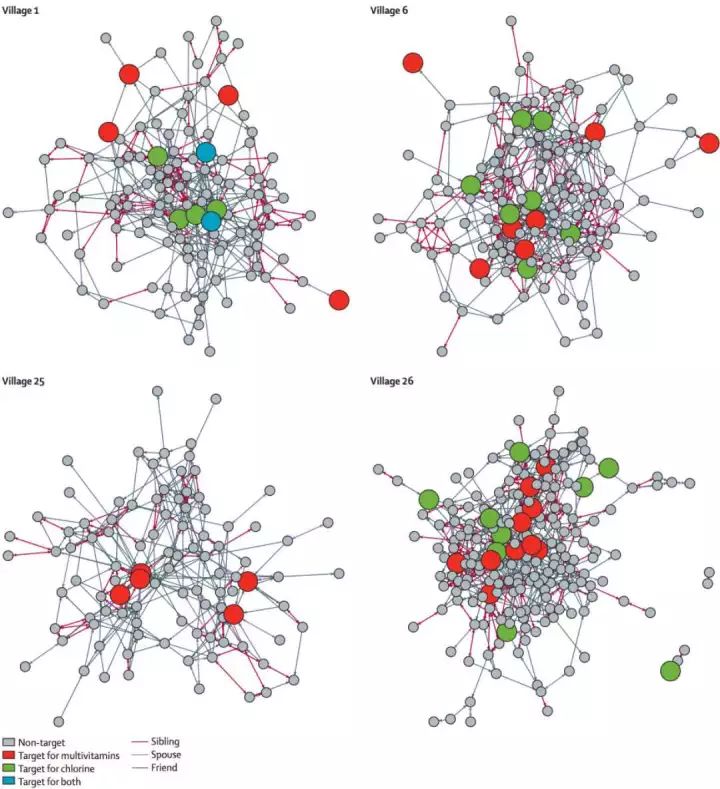
四个村庄的社会网络图,节点是村民,不同颜色的连边表示不同的关系(红色:兄弟关系、灰色是配偶关系;绿色是朋友关系)。我们针对每个村进行了两组干预试验,一种实验是发放多种维生素(Multivitamins),其中红色的节点就是我们选择的目标干预节点;第二种实验是发放含氯消毒液(chlorine),绿色为我们选定的目标节点。
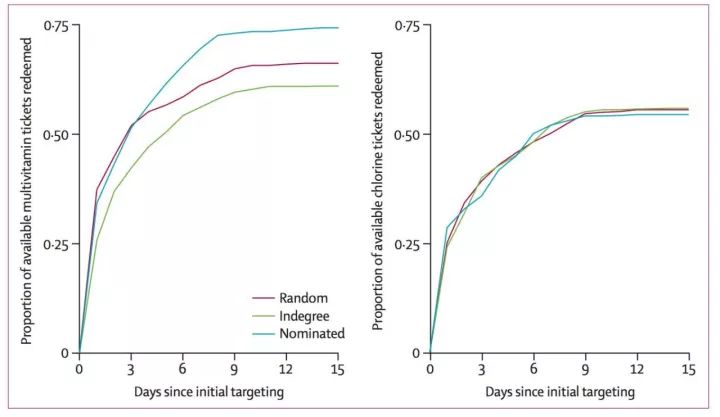
不同选取目标节点的方法会导致不同的干预效果。横坐标为实验进行的时间,纵坐标为愿意参与项目,实现卫生防治的村民比例。在左边的图中,我们看到最后一种方法,也就是选择随机村民推荐的朋友作为我们的干预节点会得到更好的效果。右侧的图是含氯消毒液发放实验,也是第三种方法更有效,但是不同方法的区分并不明显。
为什么第三种方法更好呢?就其原因就在于一般的社交网络都是无标度的,而这种网络会存在着所谓的“节点悖论”的效应,也就是:你自己的平均好友数会低于你朋友们的平均好友数。
节点悖论可以应用到广告推广活动中。一个现实的意义就是,如果你想去推广你的产品,不仅仅要为你的受众推广,还要附赠他另外的产品,让他推荐给他的朋友们。
人工智能如何影响人类社会

如何用机器人来干预我们人类的集体行为?这是DeepMind的AlphaGo打败了李世石之后,我们思考的一个问题。如何用一些比较低级的机器人或AI改造这个世界,让我们人类社会更加有效地工作?
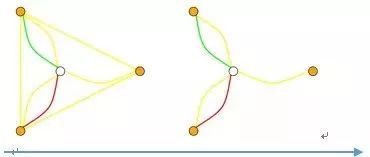
我们设计了一个很简单的颜色博弈实验。我们在亚马逊土耳其机器人(Amazon Mechanical Turk)这个众包平台上雇佣了大量的志愿者,并让他们在线参与这个颜色协调博弈实验。参与者之间的社会关系是我们事先通过网络连接设置好的,每个参与者只能看到自己周围的网络邻居,如下图所示:
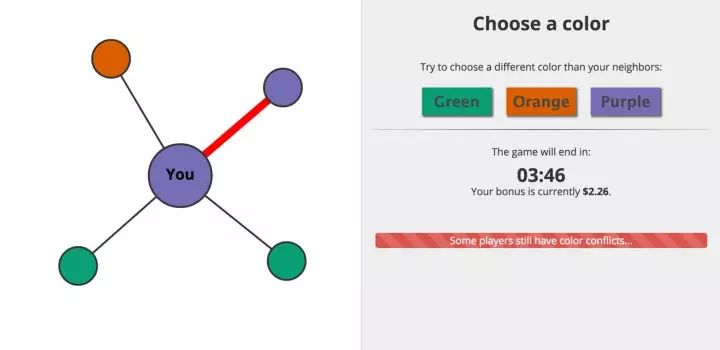
首先,我们的平台会随机为网络中每个参与者给出一种颜色,如果你的颜色和邻居的颜色不同,就说明你们之间存在着一种冲突。因此,我们的实验要求参与者在尽可能短的时间里尽可能多地解决冲突。如果所有参与者能够在5分钟之内协调好所有颜色的话(也就是使得网络上不存在着冲突),那么所有参与者都会得到一份奖励。如果解决所有颜色冲突所用的时间越短的话,那整个系统的人的这个协调的工作做得越出色。
于是,我们问这样的问题:假如我们让一些机器人参与到博弈实验当中,它是否会帮助人类群体更快地解决颜色协调博弈问题呢?如下图所示:
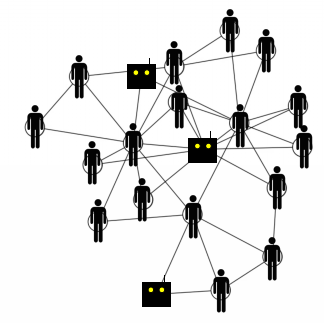
那么我们应该如何放置这些机器人呢?我们对比了三种情况:第一种是随机放置机器人;第二种是将机器人放置到网络的中心位置;第三种是放置到边缘位置。
除此之外,我们的机器人应该遵循什么样的规则呢?首先,它应该是理性的,也就是它会选择一个和周围邻居颜色冲突数最少的一种行动方案;其次,我们的机器人也可能包含一些非理性的因素,它偶尔会随机乱来选择自己的行动。我们把随机行动所占的比例用噪声来表示,区分出0噪声、低噪声(10%的随机选择)和高噪声(30%的随机选择)三种情况。
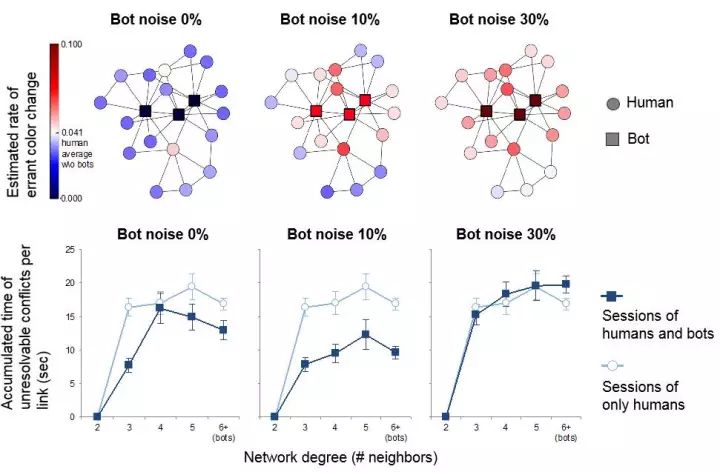
于是,三种噪声水平以及三种放置机器人的网络位置两两组合一共九种可能性,我们希望知道哪一种组合会让人们完成协调博弈的速度更快呢?
答案如下图所示,我们可以看到在所有的这些组合当中,只有中间的那一个组合,机器人会显著提高系统整体的效率。在每张图中,横坐标是实验进行的时间(总共五分钟),纵坐标是解决冲突的比例,蓝色的线是人机混合解决问题的情况,浅蓝色的线是只有人做实验的情况。我们明显看到,在大多数情况下,机器人的参与都会提高解决问题的效率(体现为深蓝曲线通常在浅蓝曲线下方),而正中间的情况(机器人被放置到网络中心,他们有10%的随机选择)会让整体效率最高(深蓝色曲线下降最快)。
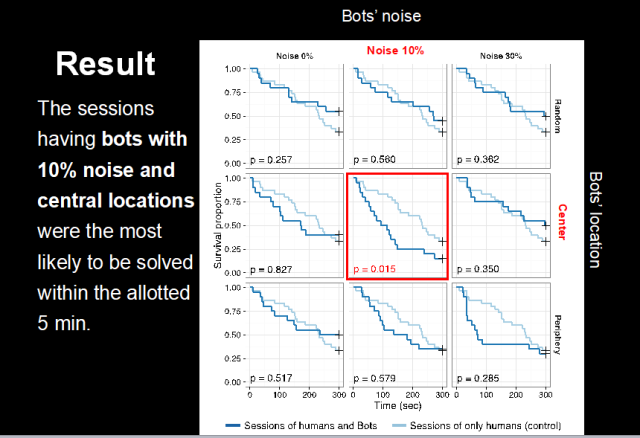
这个实验告诉我们,在人机共生的社会下,只要我们合理地布置机器人所在社会网络中的位置,精巧地设置他们的行为规则,我们的社会将会更加高效。本篇文章“Hirokazu Shirado & NicholasA. Christakis: Locally noisy autonomous agents improve global human coordinationin network experiments, Nature 545, 370–374, 2017”发表在今年五月的Nature上面,并被选为该期的封面文章。

施博士的分享结束后,集智嘉宾与在场观众针对本次活动的主题在现场做了深入的思考和探讨。大家从不同的专业背景分享了自己对于施博士工作的看法和背后的现实意义。同时也结合自己的领域和实际情况探讨了未来社会科学的发展和AI的对人类社会的影响。具体参见讨论环节记录,并且还有附上现场大家一起交流、讨论的彩蛋照片哦。
> AI & Society 沙龙计划 <
人类已经全面进入了智能社会,以人工智能为代表的新一代技术必将逐步渗透到我们的日常生活之中,并彻底改变我们的社会形态。
那么,新一代的人机共生社会需要怎样的社会科学?社会科学的研究成果又如何促进人工智能的发展?人工智能会怎样影响人类社会?社会科学研究又如何借鉴人工智能领域的最新成果?
我们认为挖掘AI与社会领域有想法的年轻学者,促进AI与社会原创思想的交流与碰撞是探索、回答这一系列重大问题的第一步。因此,腾讯研究院S-Tech工作室与集智俱乐部共同打造了“AI&Society”的系列学术沙龙活动。我们真诚地希望有想法的学者能够涌现而出,并真正形成跨学科的思想碰撞。
该系列沙龙以线下实体活动为主,我们将邀请AI与社会领域的交叉研究学者进行公开性的讨论与思想碰撞。沙龙的主题可涵盖但不限于如下的内容和主题:
计算社会科学(Computational Social Sicence)
社会计算(Social Computing)
多主体系统(Multi agent systems)
算法经济学(Algorithm Economy)
人工智能社会学(Artificial Intelligence Sociology)
群体智慧(Swarm Intelligence)
人类计算(Human Computation)
机器学习(Machine Learning)
技术与人类社会(Technology and Human Society)
人工智能与城市科学(Artificial Intelligence and Urban Science)
该沙龙已经在上海、深圳举办了两期精彩的线下活动:

AI&Society 第一期
AI&Society 第三期(预告)
颠覆性创新一百年:来自大学、公司、与互联网社区的大数据观察
报告简介
人类的技术和科学发展史,常常面临重大转型。每一次重大转折中,都会出现致“颠覆性创新”的团队或者个人,其贡献的知识或者技术,不是沿着既有技术发展,而是冒着巨大风险开辟了新的方向。随着新的方向逐渐树立,小团队成长为大团队,年轻成员成为资深专家,他们获得越来越多的资源和注意力,要维持越来越多的合作关系,工作日程日趋繁忙,思想决策却日趋保守,形成又一轮的技术锁定,等待着新一轮技术突破的产生。
报告分析了Web of Science数据库中在一百年(1915-2015)中记录的四千五百万论文团队,美国专利数据库中在四十年(1975-2015)中记录的五百万专利团队,和GitHub数据库在四年中记录的一千五百万开源代码团队,揭示了团队规模及成员分工对团队创新能力的影响。研究发现,小团队经常以小博大,以慢制快,来实现颠覆性创新。
相关论文:https://arxiv.org/abs/1709.02445
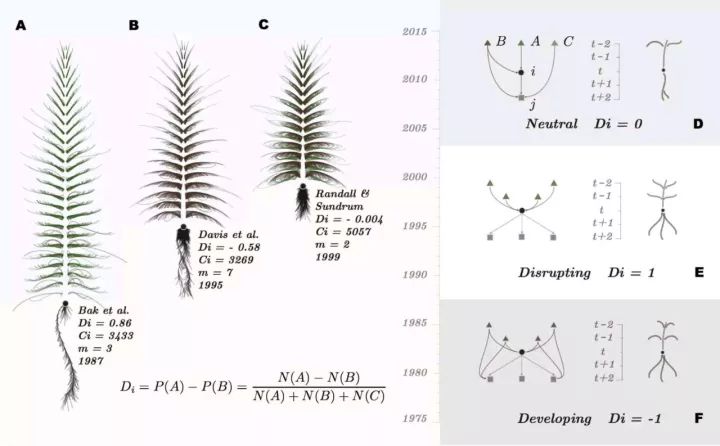
三篇引用量类似,却有着非常不同的“颠覆程度”的论文
主讲人介绍

吴令飞:芝加哥大学社会学系博士后,研究兴趣是组织创新与学习。通过使用数学模型和机器学习方法,通过研究来自科学界(例如Web of Science 和 ORCID数据)、工业界(例如美国专利数据)、和互联网众包社区(例如Stack Exchange 和 GitHub)大量团队的人员结构与产出的关系,报告人致力于寻找组织创新与学习的一般规律,促进组织管理和政策制定。
2013年从香港城市大学获得传播学博士学位。博士最后一年曾在百度推荐与个性化部作为算法工程师实习生。在到芝加哥大学前曾在亚利桑那州立大学人类行为、制度与环境研究中心担任博士后研究员两年。
报告信息
主办方:腾讯研究院S-Tech工作室、集智俱乐部
时间:2017年12月24日 9:00-17:30
地点:腾讯研究院(北京)
日程:08:30-09:00 签到
09:00-10:00 报告
10:00-10:30 Q&A
10:30-10:40 休息
10:40-11:40 讨论
11:40-13:30 午餐
13:30-17:30 workshop
AI技术追踪
每位讲者20分钟,穿插讨论互动
傅渥成:生物进化与多任务学习
东京大学综合文化研究科特任研究员(博士后),博士毕业于南京大学物理学院。主要研究兴趣是与生命现象(分子运动和神经科学)和机器学习有关的统计物理问题。
尹相志:人工智能新零售
DeepBelief.ai首席数据科学家
王晓:社会机器的社会管理
复杂系统管理与控制国家重点实验室助理研究员
史雪松:深度学习与智能机器人
英特尔中国研究院研究员
侯月源:揭秘彩云小译
彩云AI算法工程师/集智志愿者
谷伟伟:复杂网络中的深度学习
北京师范大学系统科学学院研究生
龚力:图像增强与超分辨率重建
北京师范大学系统科学学院研究生
报名方式:扫描下方二维码或者点击阅读原文,此次报名为审核通过制,仅50个名额,请认真填写报名信息,确保我们可以联系上您。





