哈工大秦兵:机器智能中的文本情感计算 | CCF-GAIR 2018
声明:本文转载自公众号 AI科技评论
AI 科技评论按:2018 全球人工智能与机器人峰会(CCF-GAIR)在深圳召开,峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)承办,得到了宝安区政府的大力指导,是国内人工智能和机器人学术界、工业界及投资界三大领域的顶级交流盛会,旨在打造国内人工智能领域最具实力的跨界交流合作平台。
CCF-GAIR 2018 延续前两届的「顶尖」阵容,提供 1 个主会场和 11 个专场(仿生机器人,机器人行业应用,计算机视觉,智能安全,金融科技,智能驾驶,NLP,AI+,AI 芯片,IoT,投资人)的丰富平台,意欲给三界参会者从产学研多个维度,呈现出更富前瞻性与落地性相结合的会议内容与现场体验。

秦兵,女,哈尔滨工业大学计算机学院教授、博士生导师。哈尔滨工业大学社会计算与信息检索中心副主任。中国中文信息学会理事、中国中文信息学会语言与知识计算专委会副主任、社会媒体处理专委会情感分析工作组组长、信息检索专委会常委,国家重点基金项目负责人。在顶级国际会议 ACL、COLING、EMNLP、IEEE TKDE、IEEE TASLP等国内外重要期刊及会议上发表论文60余篇,担任多个会议领域主席以及多个期刊和会议的审稿人。主持多项国家自然科学基金以及国家科技部863项目。同时和多家互联网企业开展合作,多项研究成果进入企业产品。获中文信息学会钱伟长中文信息处理科学技术奖一等奖、黑龙江省技术发明二等奖。
秦兵教授的现场演讲内容 AI 科技评论回顾如下。
主持人 刘挺:CCF-GAIR 大会我去年也参加过,今年办得比去年更成功、规模更大,已经成为中国人工智能风向标,每个会场的参会人数也说明这个方向的火爆程度,今天是第三天开会还能坐满整个会场,说明大家对自然语言处理的关注。
自然语言处理自起步以来,一直做事实型文本,特别是以新闻报道为主要处理对象,最近这十多年来,由于社交媒体的兴起,越来越多学者开始研究人在互联网上表达的情感,今天我们请来哈尔滨工业大学社会计算与信息检索中心副主任秦兵教授。秦老师多年从事自然语言处理的研究,获得国内第一个关于文本情感分析方面的自然科学基金重点项目。作为社会媒体处理专委会情感分析专业组的组长,秦兵教授担任今年SMP 2018大会程序委员会主席,这个大会也会和雷锋网合作,欢迎大家 8月2-4日去哈尔滨。
下面我们以热烈的掌声欢迎秦老师作文本情感分析方面的报告。
秦兵:大家上午好!感谢雷锋网和刘挺教授的邀请,今天我报告的题目是:机器智能中的文本情感。
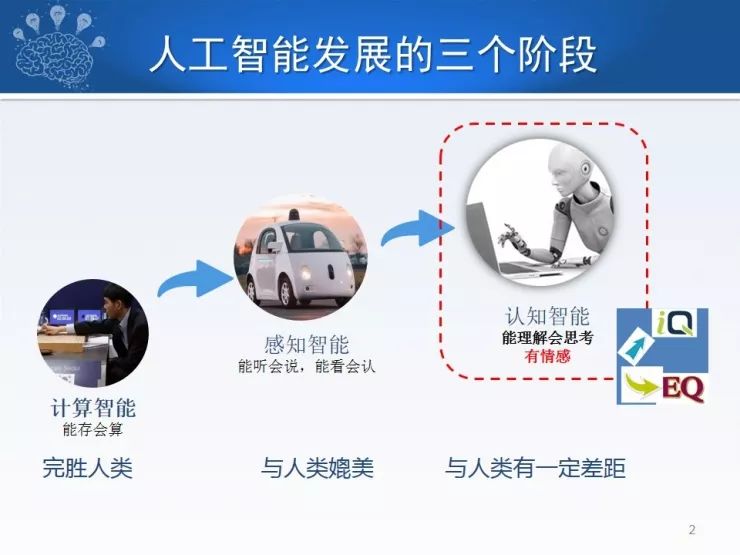
大家也知道,人工智能目前已进入迅猛发展阶段,总体可以分为三个阶段,第一个阶段是计算智能的阶段,这个阶段计算机和人类相比是能存会算,它的超大存储量、超高计算速度,这方面完胜人类。第二个阶段是感知智能,以语音识别、图像识别为代表的技术迅猛发展。大家也看过很多电视节目,包括“机智过人”、“最强大脑”;人和机器比图象识别,机器已经可以和人类相媲美甚至在某些方面超过人类。第三个阶段是认知智能,这个阶段需要机器能够思考,能够具有情感,这个阶段考验的是智能是否有情商,也就是说情感在人工智能认知阶段还是非常重要的。
人工智能中的情感计算也不是现阶段才提出来的,最早在人工智能之父明斯基就提过“我们的问题不是怎样才能让机器智能有情感,而是机器智能怎么能没有情感。”微软全球执行副总裁沈向洋说“我们的智能不光有IQ,还需要有情感”。斯坦福人工智能实验室主任李飞飞也曾说过“情绪和情感是人工智能的未来”。
何为情感?严格定义来讲就是情感是人对客观事物是否满足自己需要而产生的态度体验。机器对于情感的要求就是机器情感计算,也就是机器理解人类的情感和生成情感的能力。所以赋予计算机情感计算能力的研究引起了学术界和企业界的广泛关注。很多人都看过电影《她》,人机恋爱出现在科幻电影中,未来也许会出现在我们的生活当中。

机器情感怎么获得?怎么和人进行交流?它首先要获取人类的情感资源,比如它要去了解或学习如何识别情感、产生情感。社会媒体是观察人类情感的有效窗口,也就是说我们每天在社交媒体上的各种活动,包括购物、聊天、社区、资讯、生活等等,这些都流露出人在某些方面的情感资源。我们可能平时没有意识到,实际上这种资源大量存在,而且社交媒体中不仅有大量的文本资源,还有大量的情感资源。比如微博、大众点评,微博上经常出现一些喜怒哀乐情绪的发布,大众点评中经常是我们对产品、服务的评价,这里面有大量丰富的情感文本资源。社会媒体中的文本情感计算就是要结合社会媒体中除了文本,还有用户和群体信息,然后对文本情感进行分析、处理和归纳,使得情感分析具有更好的针对性和精准性。
今天的报告主要从情感计算的六个维度来讲:
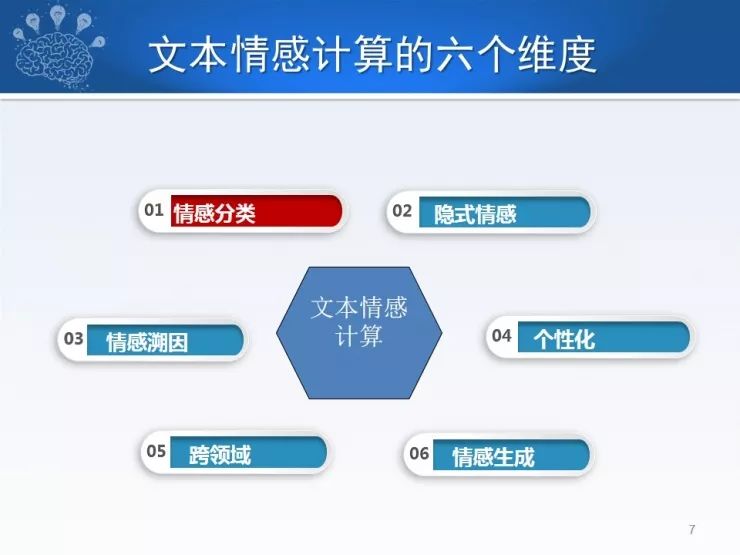
一、情感分类
首先从情感分类的角度出发,比如说人类的情感是多样性的,我们经常能想起来的词或者看到的词,比如喜极而泣、抱头痛哭、捶胸顿足、七情六欲、五味杂陈等等,表达了我们的喜怒哀乐。实际上多年来也有很多人在这方面做了很多研究,比如七情六欲分为好、恶、乐、怒、哀、惧、欲等。此外,还有人从高兴、悲伤、愤怒、恐惧、厌恶、惊奇等进行分类。
对于情感分类,一般来讲有粗粒度情感分类,粗粒度情感分类主要用来判断文本整体情感倾向,表明一个人对某件事或对某个物体的整体评价。情感计算中大多采用两种,一种是倾向性分类,即褒、贬、中的分类,还有一种是微博中经常出现的情绪分类,表示个人主观情绪的喜、怒、悲、恐、惊。
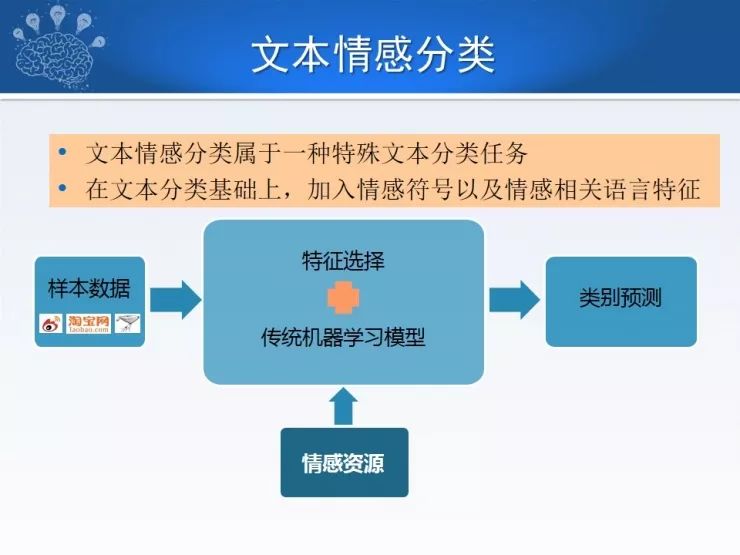
有了这么多类别体系,又有倾向性分类或情绪分类,分别针对我们对不同的产品、不同的服务,甚至表达的是我们个人的不同情感,无论它怎么划分或者划分的颗粒度有多细,总体来讲它是一个分类任务,也就是说传统的文本分类任务适用于情感分类,文本的情感分类可以看成是一种特殊的文本分类任务。那么传统文本分类是通过训练样本、特征提取+机器学习模型,训练好参数,对未知样本进行分类预测。对于情感分类,考虑到特定的情感资源,相对于传统文本分类,有了更多可利用的知识。
随着深度学习的发展,也给文本情感分类带来很多生机。这些年出现很多关于深度学习和情感分析相结合的情感类别预测任务。在深度学习过程当中可以加入情感资源,包括语言学的约束、情感辞典的信息,加入之后可以使情感分类和深度学习结合得更充分。
刚才讲的是粗粒度分类,便于我们从整体上把握用户对情感、对世界、对产品的整体倾向。还有一种分类叫细粒度情感分类,所谓细粒度即针对评价对象及其属性的情感倾向,比如“iPhone10很不错,除了贵,买不起,新的 iWatch 可以买一个,跑步就不要带手机了”。这里面有两个评价对象,第一个评价对象的评价是 iPhone 很不错,但是很贵,在购不购买上持否定态度,对于 iWatch 来讲,评价对象认为跑步时可以不用带手机,所以相对于 iPhone 来讲,更倾向于买 iWatch。我们做细粒度情感分析时就要分别把不同的评价对象抽取出来,把评价词语、情感类别分别判定出来,这样我们就可以细粒度分析一个产品、服务甚至情感。
当然,这种分类任务要结合文本当中不同的评价对象,所以面向评价对象的情感分类有很多种方法,比较典型的可以利用上下文信息,采用神经网络中的注意力机制,使某个评价对象和词语能更好地寻找到搭配,从而来判断。我们在 EMNLP2016 上发表的一篇论文就介绍了我们的成果。
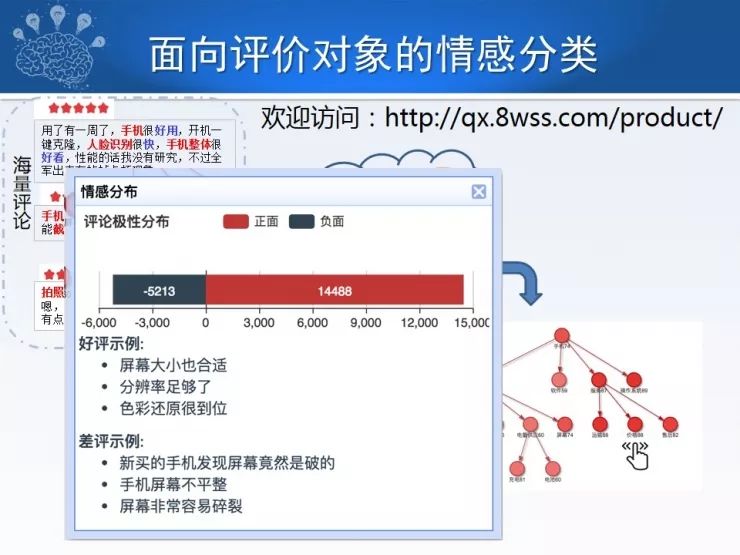
面向评价对象的情感分类,可以落地很多应用,比如现在网络上有很多文本,海量的评论,比如评论手机,具体来讲是华为手机,我们在评论时按照细粒度分类,可以把评价对象、评价词、属性抽取出来,进一步构建出评价手机体系的维度空间,也就是说你可能事先对某一个产品或某一个分类不知道从哪些角度去了解它,或者从哪些维度去分析它,但我们可以通过细粒度情感分类把这个体系归纳出来,同时对每一个粒度进行打分,比如图中红色和蓝色的区别就是褒贬,颜色的不同表示它们打分值,这样用户可以在购买时进行评价,比如华为手机、苹果手机或其他类型的手机。同时我们还可以把这些评论总结出来,比如评论的极性分布,刚才是细粒度的,总体来讲有多少人是评价正面的,有多少人评价是负面的,这是粗粒度的,这些都可以给用户提供全方位评价体验。
粗粒度情感分类是为商家了解用户对产品的评论,政府了解公众舆情提供参考。细粒度情感分类可以提供所评价的产品或服务的精准画像,为商家和用户提供不同的评估。
二、隐式情感
无论是你听别人的话,还是自己表达情感时,可能未必会使用情感词。情感表达中有20%-30%是没有情感词的,它属于隐式情感,而隐式情感多使用事实型陈述和语言修辞表达,从隐式情感分布来讲,有事实型,有比喻型,有反问型,其中事实型情感占72%。采用事实型情感,比如一个人住到酒店,他在发微博时说“桌子上有一层灰”,这没有任何情感词,但实际上已经表达了他的不满,这就是事实型表述。再看褒义描述,“从下单到收到货不到24小时”,表明他称赞快递速度很快,但没有明显的表达词,这些都属于事实型表述。
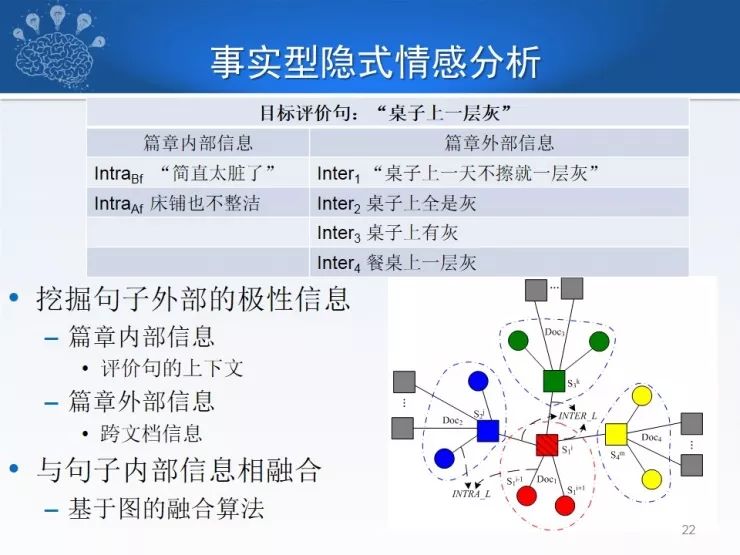
这种事实型描述怎么挖掘?这种事实型表述出现很频繁,这个时候我们可以采用上下文,比如我说“桌子上有一层灰,很不高兴”,就可以把“桌子上有一层灰”定义为贬义的。或者找不到上下文的话,也可以在其他文当中找到跟它相似的语句,再判定情感,通过借助周围上下文的分析进行推理,得到这句话的情感,这是一种解决策略。同时,我们也可以借助某种知识,比如快递多长时间算快,或者说这个人身高1.8米,我们有个常识,一米几以上就算高个儿,类似这样的知识可以帮助我们进行隐式情感分析。
除了事实型之外,还有一种是修辞型的,修辞型的更难区分,“拿机器人和人相比,“你咋这么聪明呢?”平常你可以听到别人这么夸你或者这么讽刺你,但有的时候光看语言的话,我们很难判定是夸你聪明还是笨。此外,还有隐喻的方式,比如一个人去旅游胜地爱琴海,他在描述中说“此乃西方文明的摇篮”,这就是一种比喻,这种比喻包含很多赞赏,这种修辞型怎么表达出来?或者怎么把大量的存在于我们生活当中的隐式情感挖掘出来,这需要很多知识,从资源的角度来讲,大连理工大学林鸿飞老师有一些隐喻语料库,山西大学王素格老师有一些隐式情感语料库,分别对事实型和修辞型隐式情感提供了一定帮助。当然,语料库只是提供某些支持,隐式情感是一种含蓄的表达方式,隐式情感表达因为缺少情感词的指引,所以需要寻找新的特征与表示方法。而且要结合目标,比如我们说到玫瑰花、红豆、月亮,说到这些词的时候会联想到哪些情感,这些和知识和上下文都会通过分析推理获得隐式情感的语义。
三、情感溯因
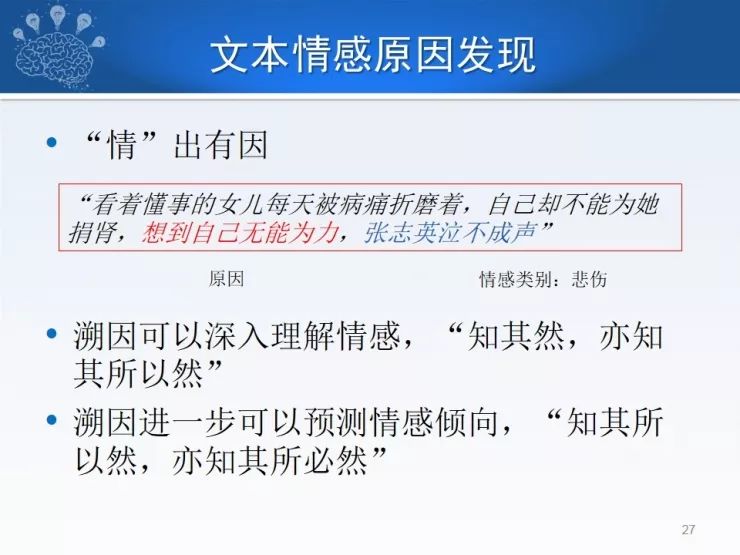
分析情感的目的是什么?这些情感产生的原因又是什么?比如他是因为什么高兴、因为什么伤心、因为什么愤怒,我们需要情感溯因,也为了大家更好地观察产品、体会服务以及体察对方的情感。从原因来看,一般是“情”出有因,这里有一个例子看着懂事的女儿每天被病痛折磨着,自己却不能为她捐肾,想到自己无能为力,张志英泣不成声”。我们可以进行溯因,也就是要知其然,也要知其所以然,知道了原因之后,比如你知道一个人有洁癖,忍受不了桌子上有一层灰,下次她再看到一个地方的桌子上有一层灰,可能她没有表达出来,但你能预期到她会生气。
文本情感的原因发现方法,比如哈工大深圳研究院的徐睿峰老师做过一些工作,也有语料库,一般是按照类似问答系统研究的方式,这里面有情感词、有原文,通过记忆网络判别这个文章中哪句话是原因,通过类别判断是或不是。
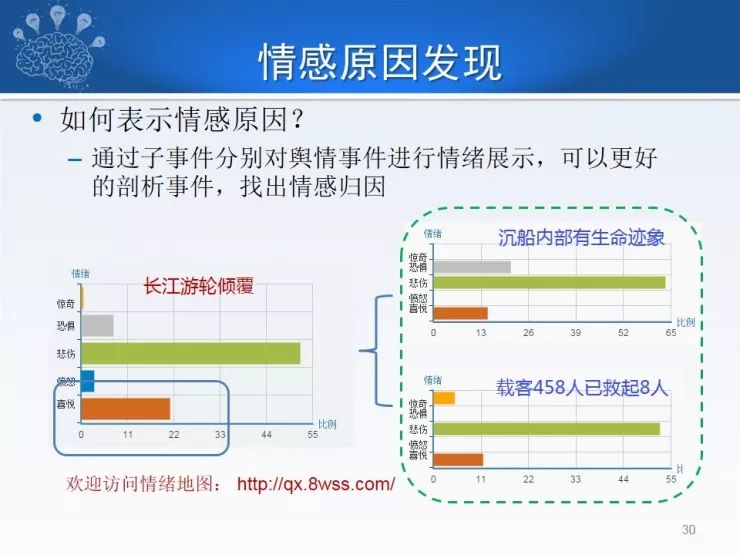
另外一种是群体,除了文本情感原因,社交媒体上也有很多值得我们发掘的原因,比如长江邮轮倾覆这件事中有很多悲哀的情绪,但是为什么还会有喜悦的成分呢?大家也会疑惑,我们通过此事件分析,对长江邮轮倾覆事件的喜悦实际上是由于沉船内部有生命迹象和载客458人,救起8人,由这些子事件导致大家觉得有希望的情感,所以表达出来了喜悦,这也是情感原因的发现方法,从社交媒体上通过子事件进行分析。
四、个性化
通过进一步分析我们可以知道人和人是不同的,同一对象,不同人立场不同,可能表达出不同情感;相同对象,不同人表达相同情感,用词风格不同。比如男生和女生对待某一件事的时候可能分歧很大,所以在情感计算中要加入用户特征,比如用户画像技术,这里面包括自然属性、社会属性、兴趣属性、心理属性等。一般立场不同,情感可能会不同,比如去年广为人知的“青岛38元大虾”和“哈尔滨天价鱼”事件,关于青岛38元大虾,“在南方的东北妹子”评价说“米饭按粒卖,我不得不倾家荡产么!”关于哈尔滨天价鱼中的评价是“北方人觉得南方小小气气,南方人觉得北方人没素质”。此外,人们的用词风格也会不同,这里有两个人,一个人很容易用非常夸张的词,比如“这个车太漂亮了”,另一个人会说“还行吧”,他所说的“还行吧”对他来讲就是很好了。我们用两个人发表的文章进行对比,不同的人发表的文章在情感分值差异性上会有不同,用词风格也如此,同一篇文档,比如这个人发表的文档相似度很高,他评价车、评价服装时都会使用很夸张的词。如果跟另外一个人来比较,文章用词的相似度就很低。
我们在神经网络分类中融入用户和产品的向量和矩阵表示信息,然后把它融入已有神经网络框架,应用到文本情感分类任务,这一部分内容的论文发表在 2015 年的 ACL 上。
五、领域问题
我们在不同的领域都存在迁移的问题,以图书和电子领域为例,每个领域的评价对象都不同,不同领域的评价表达千差万别,不同领域中的同一情感表达极性不同。比如“简单”这一词,情节简单和上手简单表达的情感就不一样。这需要我们进行跨领域的情感研究,也就是进行模型迁移过程,通常在情感分析领域的迁移,一是利用领域无关的词和领域相关词的链接关系,再进行分别聚类。在神经网络当中,通过神经网络的隐层参数尽量提取与情感相关、但与领域无关的词的特征来分类。
六、情感生成
实际上我们一直分析的是人类的情感,我们一直很期待机器是不是能产生情感,也就是说机器有情感吗?有三观吗?目前机器是没有自主意识的,而指定情感类别的情感生成可以做到,比如说我们可以根据指定的情感类别生成情感表达,也可以在聊天机器人当中根据转移概率进行变换,此外也可以对情感表达进行润色和风格转换。
评论文本生成很简单,只要你输入一个用户名、产品名,输入打分、偏好,就可以生成相应的文本情感表达,大家可能会经常会在产品评论中看到一些机器生成的评论,有些时候可以判别出是机器生成的,有的时候判别不出来。
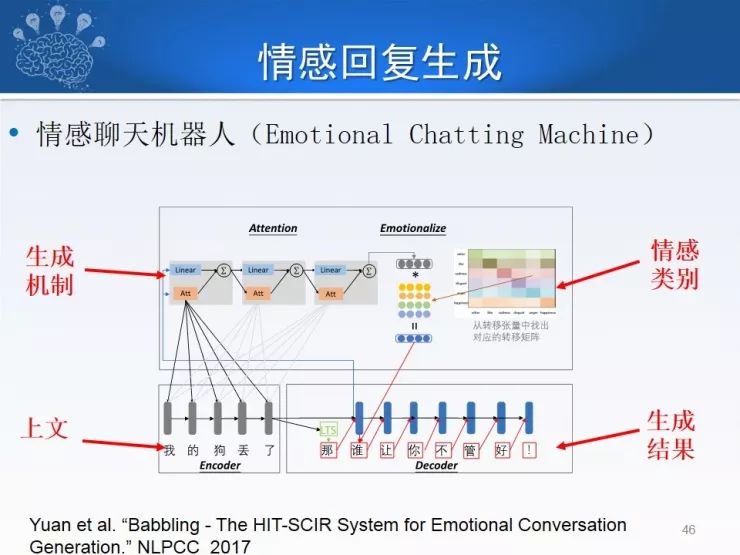
在聊天系统中可以情感回复生成,例如上一句话说“我的狗丢了”,然后生成一个生气的回复,我们在这一部分加入情感类别因素,向量和矩阵叠加起来,生成新词带入到下面,所以生成的下文是“谁让你不管好!”这是明显的表达生气情感回复。

此外,我们可以进行文本的情感极性变换及润色,比如原句是“服务不周,而且极其粗鲁”,可以修改为“服务到位,而且非常清爽”。还可以进行文章的润色,比如“两只狗在树边玩耍”,我们可以把它修改为“两只狗在树边玩耍,享受童年的快乐”。

情感文本生成迈出机器发出情感的第一步,在聊天系统中可以进行情感互动,自动生成评论文本可以丰富用户的表达方式,比如一个人不善表达,但他对这个东西打分非常好,我们可以帮助他生成一段文字,丰富他的表达方式。
总的来讲,情感分析已经发展了很多年,已经落地产生了很多应用,产生巨大价值,比如在社会舆情方面、电子商务方面,如大家经常看到的淘宝网等等,再比如在传统行业方面,比如帮助ZARA进行服装设计改进,此外在金融等特定领域都发挥了巨大的作用,这是一个很接地气的方向,同时也具有很多技术挑战。

我们来看一下能否进行诗词鉴赏。例如一个高考题目,关于一首杜甫的诗,“韦曲花无赖,家家恼煞人”,描写春色的美。“绿樽须尽日,白发好禁春”是说在这样的日子需要喝酒,需要好好享受春天的气息。“石角钩衣破,藤梢刺眼新”描述他已经不顾衣服被石角钩破,欣赏藤梢冒出的新芽。“何时占丛竹,头戴小乌巾”表达什么时候能头戴小乌巾归隐山林。问题是谈谈诗的最后两句表达了诗人怎样的思想感情。参考答案是对于春色的描述表达出作者的喜爱之情,因此产生对归隐山林的隐士生活的向往。情感分析中用了很多其他技术,包括古诗词、隐喻等等,能表达情感和背后隐藏的归隐山林的心情,什么时候·机器的情感分析也能进一步分析出这种情感,同时又能像刚才孙茂松老师介绍的古诗词一样,能够生成带有指定情感的古诗词也是情感分析未来需要探索的。
最后总结一下。情感是人类的高级思维方式;机器可以通过学习理解人类的情感模式,了解人类的情感;情感溯因可以帮助更深入理解人类情感动机;机器可以借助指定情感类别方式生成情感文本;鉴赏类或文学作品赏析情感计算值得我们继续探索。真正具有自主意识的情感智能还未到来。谢谢大家!
本期责任编辑: 赵森栋
本期编辑: 蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。






