Google 开源可大规模扩展的深度强化学习新架构 SEED RL

如今,深度强化学习(Deep reinforcement learning,DRL)是深度学习领域发展最快的一个方向。AI领域近年来的一些重大里程碑都源自DRL,例如AlphaGo、Dota2 Five或Alpha Star,DRL似乎是最接近人类智能的学科。然而,虽然我们取得了如此大的进展,但DRL方法在现实世界中的实现仍局限于大型人工智能实验室。部分原因是DRL体系结构依赖巨量的训练,对大多数组织而言,这笔费用超出了可承受的范围且不切实际。
最近,Google Research发表的一篇论文中提出了SEED RL,这是一种可大规模扩展的DRL模型新架构。
在现实世界中实现DRL模型的难度与它们的架构有着直接的关系。本质上,DRL包含各种任务,例如运行环境、模型推断、模型训练或重放缓冲等等。大多数现代DRL架构都无法有效地分配这类任务的计算资源,从而导致实现成本不合理。在AI硬件加速器等组件的帮助下,我们已经克服了其中的一些限制,但仍然很有限。近年来出现的新架构已被市场上许多成功的DRL实现所采用。

IMPALA带来的启示
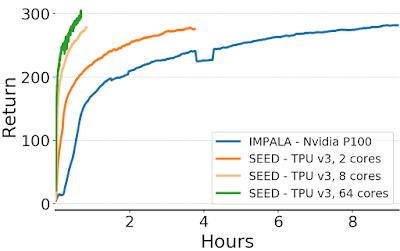
在当前的DRL架构中,IMPALA为该领域树立了新标准。IMPALA最初是由DeepMind在2018年的一篇研究论文中提出的,它引入了一种模型,利用专门的数值计算加速器,充分发挥了监督学习早已享有多年的速度和效率。IMPALA的核心是角色模型(Actor model),常常用于最大化并发和并行。
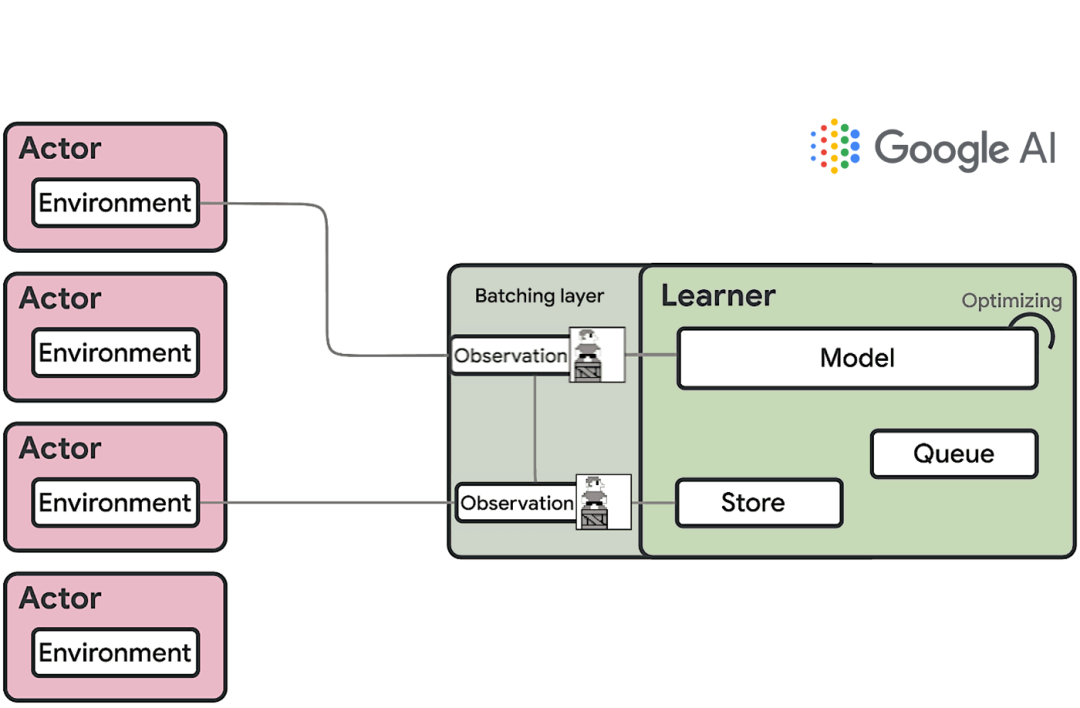
基于IMPALA的DRL代理架构主要包含两大组件:Actor和Learner。在这个模型中,通常Actor都在CPU上运行,并在环境中采取的步骤与对该模型的推断之间进行迭代,以预测下一个动作。Actor会不断更新推理模型的参数,并在收集到足够数量的观测后,将观测和动作的轨迹发送给Learner,以完成对Learner的优化。在这种架构中,Learner使用来自数百台机器的分布式推理输入在GPU上训练模型。从计算的角度来看,IMPALA架构可使用GPU加速Learner的学习,而Actor可在许多机器上扩展。
IMPALA在DRL架构中建立了新的标准。但是,该模型具有一些固有的局限性。
-
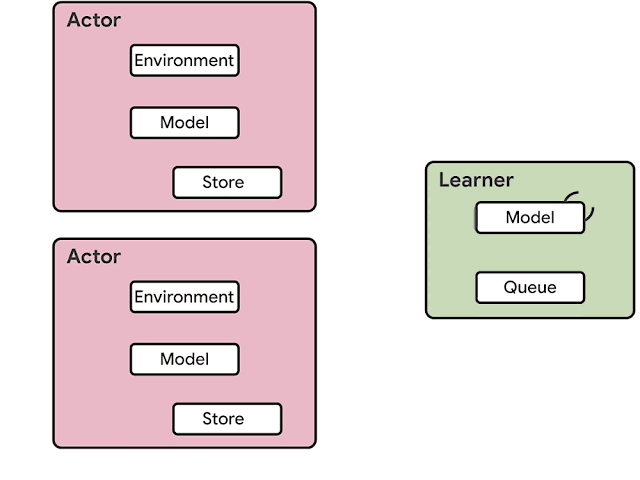
使用CPU进行神经网络推断:Actor机器通常基于CPU。当模型的计算需求增加时,推理所花费的时间会超过环境步骤的计算。解决方案是增加Actor的数量,而这会增加成本并影响融合。
-
资源利用效率低下:Actor在两个任务之间交替进行:环境步骤和推断步骤。通常这两个任务的计算要求并不一样,因此会导致资源利用率低下或Actor迟缓。
-
带宽要求:模型参数、循环状态和观测在Actor和Learner之间传递。此外,基于内存的模型需要发送很大的状态数据,因此增加了带宽需求。

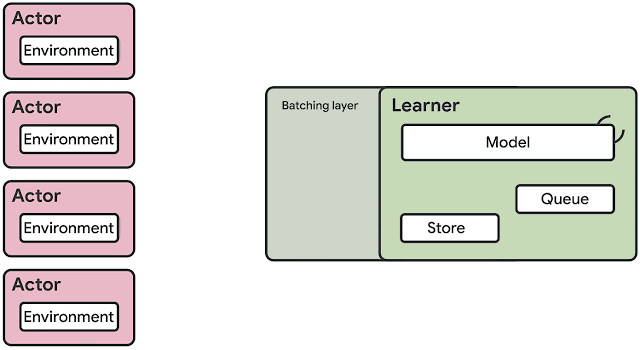 图源:Google AI 官博
图源:Google AI 官博
-
推理 -
数据预取 -
训练
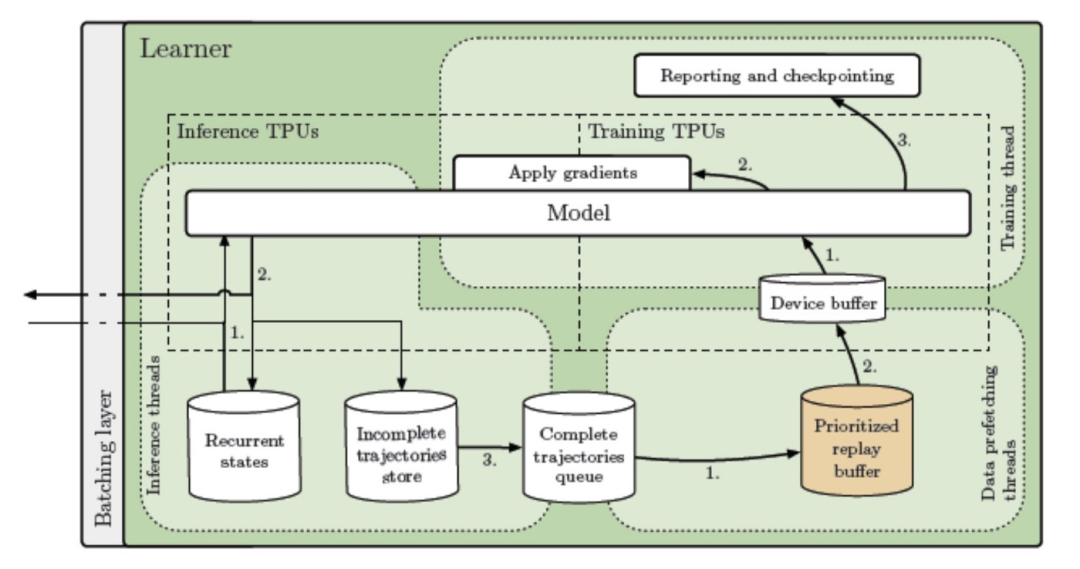 图源:Google AI 官博
图源:Google AI 官博

作为“百万人学AI”的重要组成部分,2020 AIProCon 开发者万人大会将于6月26日通过线上直播形式,让开发者们一站式学习了解当下 AI 的前沿技术研究、核心技术与应用以及企业案例的实践经验,同时还可以在线参加精彩多样的开发者沙龙与编程项目。参与前瞻系列活动、在线直播互动,不仅可以与上万名开发者们一起交流,还有机会赢取直播专属好礼,与技术大咖连麦。
评论区留言入选,可获得价值299元的「2020 AI开发者万人大会」在线直播门票一张。 快来动动手指,写下你想说的话吧!
☞互联网之父确诊新冠,一代传奇:任谷歌副总裁、NASA 访问科学家

点击阅读原文,参与报名!



