如何快速理解马尔科夫链蒙特卡洛法?

©PaperWeekly 原创 · 作者|邓妍蕾
学校|香港大学硕士
研究方向|NLP、语音识别
概览
马尔科夫蒙特卡洛法(Markov Chain Monte Carlo, MCMC)经常用在贝叶斯概率模型的推理和学习中,主要是为了解决计算困难的问题。
日常中我们会用采样的方法采集样本,进行近似的数值计算,比如计算样本均值,方差,期望。虽然许多常见的概率密度函数(t 分布,均匀分布,正态分布),我们都可以直接在 Numpy,Scikit-Learn 中找到,但很多时候,一些概率密度函数,特别是高维的概率密度函数,并不是常见的分布,这个时候我们就需要用到 MCMC。
在开始马尔科夫蒙特卡洛法之前,我们先简单介绍一些蒙特卡洛法和马尔科夫链。
蒙特卡洛法是比较宽泛的一系列算法的统称(想了解可自行 google),它的特点是假设概率分布已知,通过重复的随机采样来获得数值结果。比如根据大数定理,我们可以用采样得到的样本计算得到的样本均值来估计总体期望(例子 1)。又比如,积分的运算往往可以表示为随机变量在一个概率密度函数分布上的期望(例子 2)。
例子 1:假设有随机变量 x,定义域 X,其概率密度函数为 p(x),f(x) 为定义在 X 上的函数,目标是求函数 f(x) 关于密度函数 p(x) 的数学期望 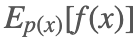
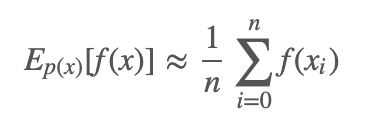
例子 2: 假设我们想要求解 h(x) 在 X 上的积分:
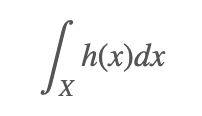 :
:
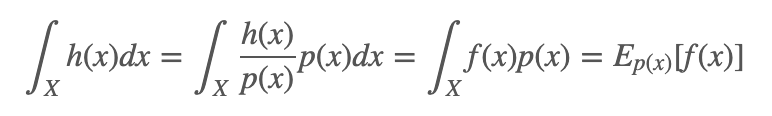
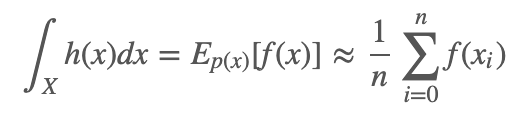
 ,那么如何用采样的方法来得到这个值呢?
,那么如何用采样的方法来得到这个值呢?
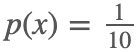 ,0<x<10,那么
,0<x<10,那么 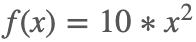 。
。
import random
numSamples = 10000
# 在 0-10的均匀分布内采样
samples = [random.uniform(0,10) for _ in range(num_samples)]
f_samples = [10 * sample ** 2 for sample in samples]
result = 1/10000.0 * sum(f_samples)
#>>> result
#333.7766822849899
假设有一个非常复杂不常见的分布 p(x),我们没有现成的工具包可以调用后进行采样,那么我们可以用我们已经有的采样分布比如高斯分布作为建议分布(proposal distribution),用 q(x) 表示,来进行采样,再按照一定的方法来拒绝当前的样本,使得最后得到的样本尽可能的逼近于 p(x)。
首先我们需要找到一个常数 k 使得 kq(x) 一定大于等于 p(x), 也就是如图所示(图摘自 [2]),p(x) 在 q(x) 下面。接着对 q(x) 进行采样,假设得到的样本为 。然后我们按照均匀分布在
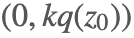
。重复这个过程得到一系列的样本
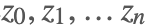
在这个过程中,我们可以发现只有当建议分布 q(x) 和复杂分布 p(x) 重合的尽可能多的地方的样本更有可能被接受。那么相反的,如果他们重合部分非常少,那么就会导致拒绝的比例很高,抽样的效率就降低了。很多时候我们时候在高维空间进行采样,所以即使 p(x) 和 q(x) 很接近,两者的差异也可能很大。
我们可以发现接受-拒绝法需要我们提出一个建议分布和常量,而且采样的效率也不高,那么我们就需要一个更一般的方法,就是我们的马尔科夫蒙特卡洛法。不过 MCMC 依旧有个问题, 它的抽样样本不是独立的。到了 Gibbs Sampling 的部分,我们可以看到它做了一些小 trick,来假装使得样本独立。
平稳分布
设有马尔科夫链 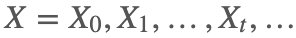
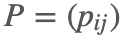
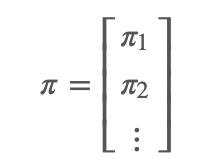
使得 π=Pπ,则称 π 为马尔科夫链
我们可以理解为,当一个初始分布为该马尔科夫链的平稳分布的时候,接下来的任何转移操作之后的结果分布依然是这个平稳分布。注意,马尔科夫链可能存在唯一平稳分布,无穷多个平稳分布,或者不存在平稳分布。
其它定理:
1. 不可约且非周期的有限状态马尔科夫链,有唯一平稳分布存在。
2. 不可约、非周期且正常返的马尔科夫链,有唯一平稳分布存在。
其中,不可约和正常返大家请自行查阅相关定义。直观上可以理解为,任何两个状态都是连通的,即从任意一个状态跳转到其它任意状态的概率值大于零。
遍历定理
设有马尔科夫链 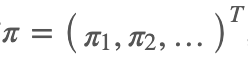
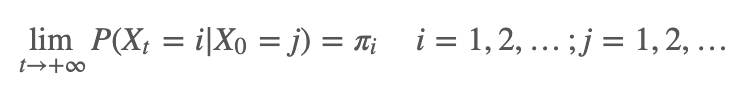

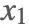 ,因为我们需要转移一定次数后才会收敛到我们的平稳分布,所以比如我们设定了 m 次迭代后为平稳分布,那么
,因为我们需要转移一定次数后才会收敛到我们的平稳分布,所以比如我们设定了 m 次迭代后为平稳分布,那么 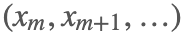 即为平稳分布对应的样本集。
,其状态空间为 S,转移概率矩阵为 P,如果有状态分布 ,对于任意状态 i,j∈S,对于任意一个时刻 t 满足:
即为平稳分布对应的样本集。
,其状态空间为 S,转移概率矩阵为 P,如果有状态分布 ,对于任意状态 i,j∈S,对于任意一个时刻 t 满足:
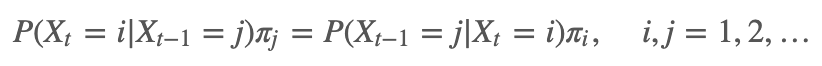

我们先来看一下 MCMC 方法的大致思路:在随机变量 x 的状态空间 S 上定义一个满足遍历定理的马尔科夫链
Metropilis-Hastings 算法是马尔科夫链蒙特卡洛法的代表算法。假设要抽样的终极概率分布是 p(x),它采用的转移核为:
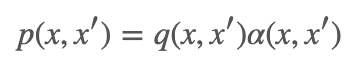
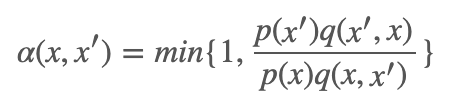
到这里为止,读者可能觉得好像又和之前的拒绝-接受法很相似了呢。但是不同的地方是之前我们在拒绝-接受法里需要定义的建议分布还是比较难设定的,因为它需要满足一定的条件才可以。但是这里的建议分布相是一个比较容易抽样的分布。同理,我们根据建议分布 q(x,x′) 来进行随机游走,产生样本后,按照接受分布 α(x,x′) 来确定是否要进行转移。
那接下来,我们需要解决的主要问题是,如何证明通过这个方式最后生成的样本是符合 p(x) 分布的呢?也就是说,如何证明这个转移核 p(x,x′) 满足遍历定理以及最后的平稳分布是 p(x) 呢?
证明略。其实我们只要能证明这个构造出来的转移核 p(x,x′) 对应的马尔科夫链是可逆的,并且其对应的平稳分布就是 π 即可。也就是说需要证明:
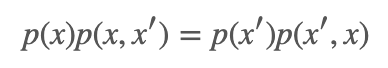
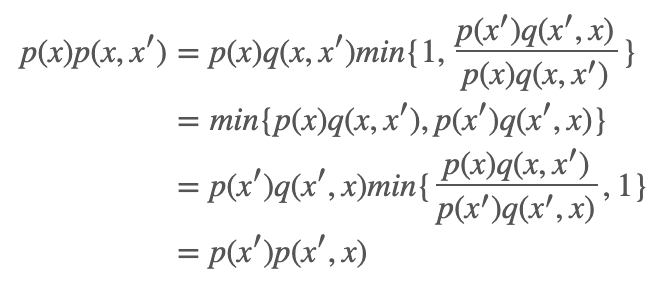
并且根据细致平衡方程,p(x) 即为这个转移核 p(x,x′) 的平衡分布。
在给出 M-H 方法的总体流程之前,我们先来看几个特殊的建议分布。
对称建议分布:假设我们的建议分布是对称的,即 q(x,x′)=q(x′,x),那么我们的接受分布 α(x,x′) 可以写成:
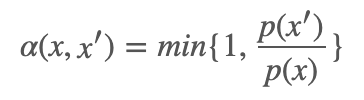
特别地,q(x,x′)=q(|x−x′|) 被称为随机游走 Metropolis 算法,例子:
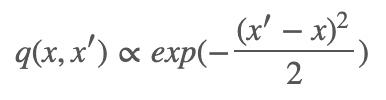
读者也很容易发现,当正态分布的方差为常数,均值为 x,参数为 x′ 的这些转移核都满足这种类型。这种类型的转移核的特点是,当 x′ 在均值 x 附近的时候,其概率也就越高。
独立抽样:前面的抽样过程中,可以发现下一个样本总是依赖于前一个样本。那么我们假设设定的建议分布 q(x,x’) 与当前状态 x 无关,即 q(x,x′)=q(x′), 此时的接受分布 α(x,x′) 可以写成:
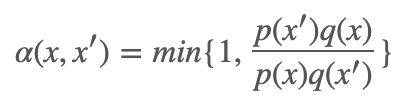
书上说,这样的抽样虽然简单,但是收敛速度慢,通常选择接近目标分布 p(x) 的分布作为建议分布 q(x)。
接下来,我们看一下 M-H 方法的总体过程。
输入:任意选定的建议分布(状态转移核)q,抽样的目标分布密度函数 p(x),收敛步数 m,需要样本数 n。
Step 1:随机选择一个初始值 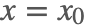
按照建议分布 q(x,x′) 随机抽取一个候选状态 x′
计算接受概率:
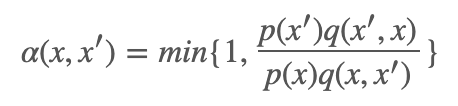
从区间 (0,1) 中按均匀分布随机抽取一个数 u。若 u≤α(x,x′),则状态 x=x′,否则,x 保持不变
if (t >= m) 将 x 加入到 samples 中
# -*- coding:utf-8 -*-
import random
import numpy as np
import matplotlib.pyplot as plt
def mh(q, p, m, n):
# randomize a number
x = random.uniform(0.1, 1)
for t in range(0, m+n):
x_sample = q.sample(x)
try:
accept_prob = min(1, p.prob(x_sample)*q.prob(x_sample, x)/(p.prob(x)*q.prob(x, x_sample)))
except:
accept_prob = 0
u = random.uniform(0, 1)
if u < accept_prob:
x = x_sample
if t >= m:
yield x
class Exponential(object):
def __init__(self, scale):
self.scale = scale
self.lam = 1.0 / scale
def prob(self, x):
if x <= 0:
raise Exception("The sample shouldn't be less than zero")
result = self.lam * np.exp(-x * self.lam)
return result
def sample(self, num):
sample = np.random.exponential(self.scale, num)
return sample
# 假设我们的目标概率密度函数p1(x)是指数概率密度函数
scale = 5
p1 = Exponential(scale)
class Norm():
def __init__(self, mean, std):
self.mean = mean
self.sigma = std
def prob(self, x):
return np.exp(-(x - self.mean) ** 2 / (2 * self.sigma ** 2.0)) * 1.0 / (np.sqrt(2 * np.pi) * self.sigma)
def sample(self, num):
sample = np.random.normal(self.mean, self.sigma, size=num)
return sample
# 假设我们的目标概率密度函数p1(x)是均值方差分别为3,2的正态分布
p2 = Norm(3, 2)
class Transition():
def __init__(self, sigma):
self.sigma = sigma
def sample(self, cur_mean):
cur_sample = np.random.normal(cur_mean, scale=self.sigma, size=1)[0]
return cur_sample
def prob(self, mean, x):
return np.exp(-(x-mean)**2/(2*self.sigma**2.0)) * 1.0/(np.sqrt(2 * np.pi)*self.sigma)
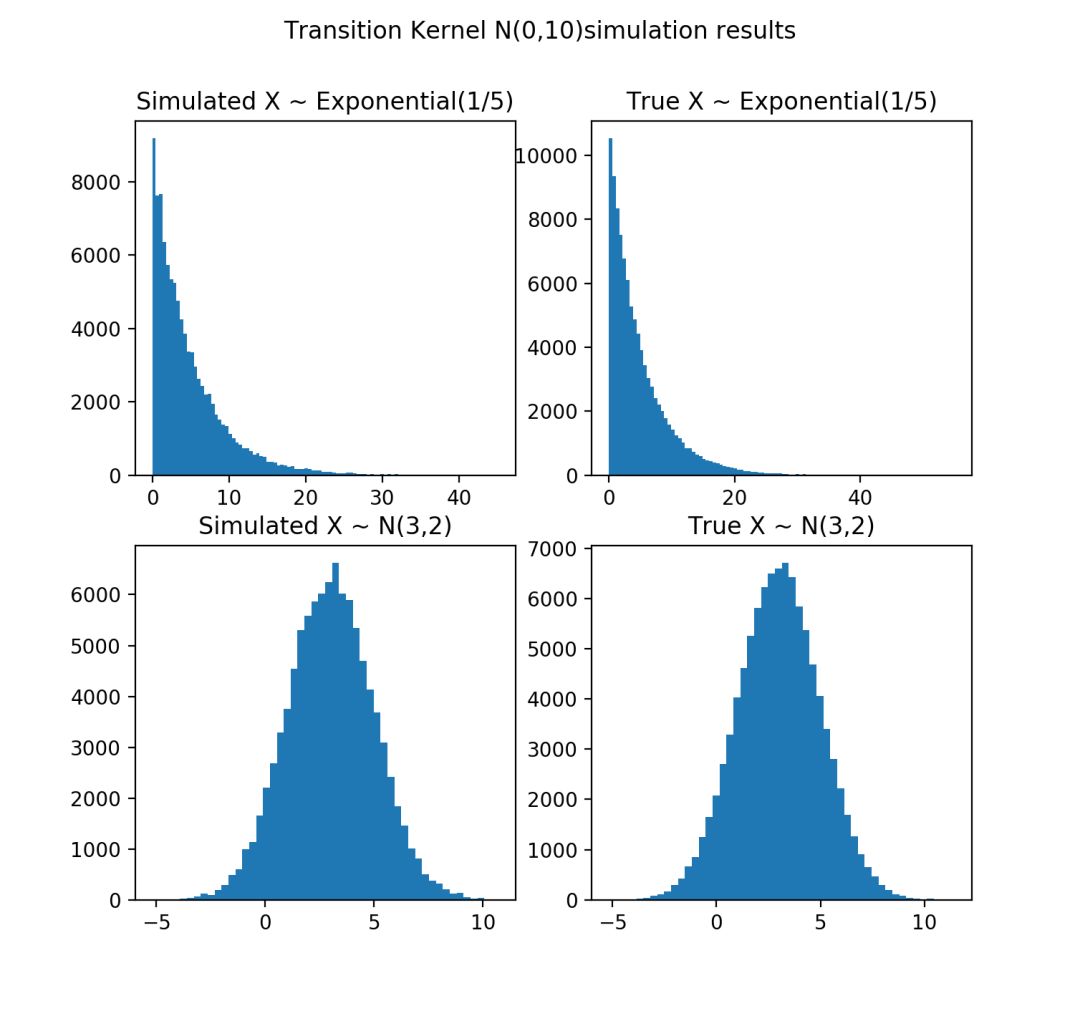
# 假设我们的转移核方差为10的正态分布
q = Transition(10)
m = 100
n = 100000 # 采样个数
simulate_samples_p1 = [li for li in mh(q, p1, m, n)]
plt.subplot(2,2,1)
plt.hist(simulate_samples_p1, 100)
plt.title("Simulated X ~ Exponential(1/5)")
samples = p1.sample(n)
plt.subplot(2,2,2)
plt.hist(samples, 100)
plt.title("True X ~ Exponential(1/5)")
simulate_samples_p2 = [li for li in mh(q, p2, m, n)]
plt.subplot(2,2,3)
plt.hist(simulate_samples_p2, 50)
plt.title("Simulated X ~ N(3,2)")
samples = p2.sample(n)
plt.subplot(2,2,4)
plt.hist(samples, 50)
plt.title("True X ~ N(3,2)")
plt.suptitle("Transition Kernel N(0,10)simulation results")
plt.show()代码运行结果:
在很多情况下,我们的目标分布是多元联合概率分布 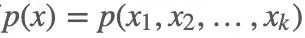
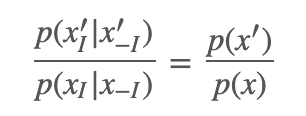
其中:

并且 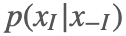
而在用转移核对多元变量分布进行抽样的时候,可以对多元变量的每一个变量的条件分布一次分别进行抽样,从而实现对整个多元变量的一次抽样。
针对多元变量的情况,我们来讨论一下其中的一个特例,吉布斯采样(Gibbs Sampling)。
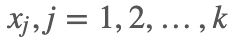 的满条件概率分布:
的满条件概率分布:
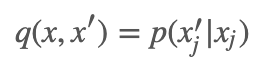
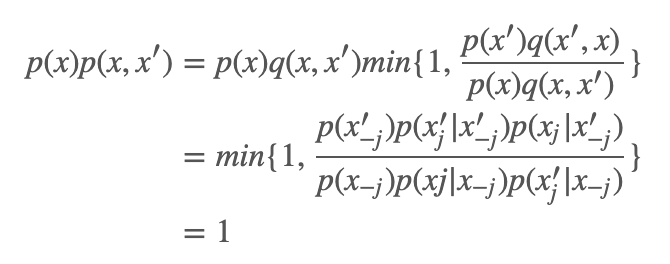
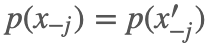 因为不难想象,假设对第 j 个变量采样前
因为不难想象,假设对第 j 个变量采样前  ,对其采完样后
,对其采完样后  ,那么在 x′ 中分别去掉第 j 项, 剩下的其余变量全部相同,所以它们的概率值也相同。
,那么在 x′ 中分别去掉第 j 项, 剩下的其余变量全部相同,所以它们的概率值也相同。
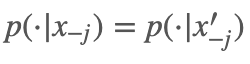
吉布斯采样算法
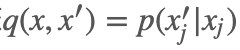 收敛步数 m,需要样本数 n。
收敛步数 m,需要样本数 n。
Step 1:随机选择一个样本 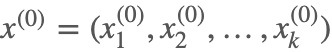
Step 2:
for i=1 to m+n:
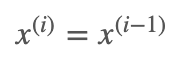
for j=1 to k:
根据:
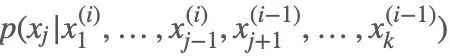
抽取 ,并赋值给
。
if (i >= m) 将 加入到 samples 中。
Step 3:返回 samples。
来看个例子吧。假设我们有二维正态分布:
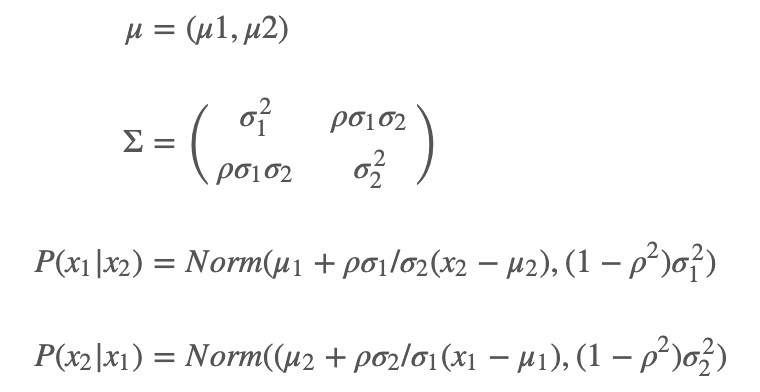
假设我们期望抽样的二元正态分布是 μ=(5,8),协方差矩阵为:

import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
class Transition():
def __init__(self, mean, cov):
self.mean = mean
self.sigmas = []
for i in range(K):
self.sigmas.append(np.sqrt(cov[i][i]))
self.rho = cov[0][1]/(self.sigmas[0] * self.sigmas[1])
def sample(self, id1, id2_list, x2_list):
id2 = id2_list[0] # only consider two dimension
x2 = x2_list[0] # only consider two dimension
cur_mean = self.mean[id1] + self.rho*self.sigmas[id1]/self.sigmas[id2] * (x2-self.mean[id2])
cur_sigma = (1-self.rho**2) * self.sigmas[id1]**2
return np.random.normal(cur_mean, scale=cur_sigma, size=1)[0]
def gibbs(p, m, n):
# randomize a number
x = np.random.rand(K)
for t in range(0, m+n):
for j in range(K):
total_indexes = list(range(K))
total_indexes.remove(j)
left_x = x[total_indexes]
x[j] = p.sample(j, total_indexes, left_x)
if t >= m:
yield x
mean = [5, 8]
cov = [[1, 0.5], [0.5, 1]]
K = len(mean)
q = Transition(mean, cov)
m = 100
n = 1000
gib = gibbs(q, m, n)
simulated_samples = []
x_samples = []
y_samples = []
for li in gib:
x_samples.append(li[0])
y_samples.append(li[1])
fig = plt.figure()
ax = fig.add_subplot(131, projection='3d')
hist, xedges, yedges = np.histogram2d(x_samples, y_samples, bins=100, range=[[0,10],[0,16]])
xpos, ypos = np.meshgrid(xedges[:-1], yedges[:-1])
xpos = xpos.ravel()
ypos = ypos.ravel()
zpos = 0
dx = xedges[1] - xedges[0]
dy = yedges[1] - yedges[0]
dz = hist.flatten()
ax.bar3d(xpos, ypos, zpos, dx, dy, dz, zsort='average')
ax = fig.add_subplot(132)
ax.hist(x_samples, bins=50)
ax.set_title("Simulated on dim1")
ax = fig.add_subplot(133)
ax.hist(y_samples, bins=50)
ax.set_title("Simulated on dim2")
plt.show()
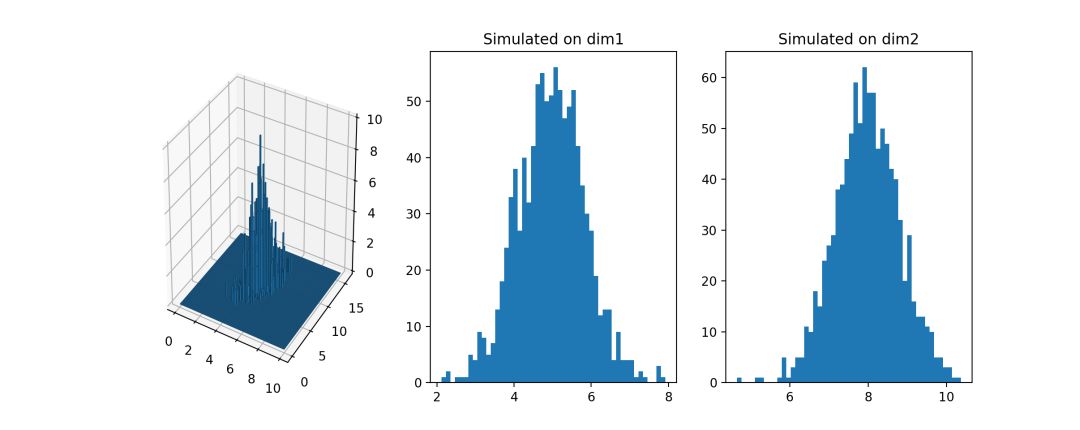
从马尔科夫链蒙特卡洛法中我们得到的样本序列,相邻点是相关的,因此如果需要独立样本,我们可以在该样本序列中再次进行随机抽样,比如每隔一段时间抽取一次样本,将这样得到的样本集合作为独立样本集合。
另外,关于“燃烧期”,即过多少步后马尔科夫链是趋向稳定分布的,通常是经验性的。比如书上说,可以游走一段时间后采集的样本均值和过一段时间后采集的样本均值做个比较,如果均值稳定,那可以认为马尔科夫链收敛。
本文回顾了马尔科夫链蒙特卡洛法的相关基本知识点、Metropolis-Hastings, Gibbs sampling 基本原理。下一篇文章,我们一起来看看 MCMC 大法在实际应用中的一些例子。
[1] 李航. 统计学习方法第二版[J]. 2019.
[2] https://www.cnblogs.com/pinard/p/6625739.html

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐


