TTFNet | 提高训练效率的实时目标检测(附源码)
计算机视觉研究院专栏
作者:Edison_G
在 目标检测模型的training time, inference speed, 和accuracy之间寻找trade off,重点关注如何在保持另外两个指标的情况下,减少模型的训练时间。 启示: 1、单纯的数据扩增能增加数据数量,但也会降低数据质量,导致需更多的训练时间才会收敛; 2、根据Linear Scaling Rule,学习率与batchsize一般情况下呈线性正比,增加高质量的sample也能起到类似batchsize的作用,从而可以提高学习率,缩短模型训练时间;
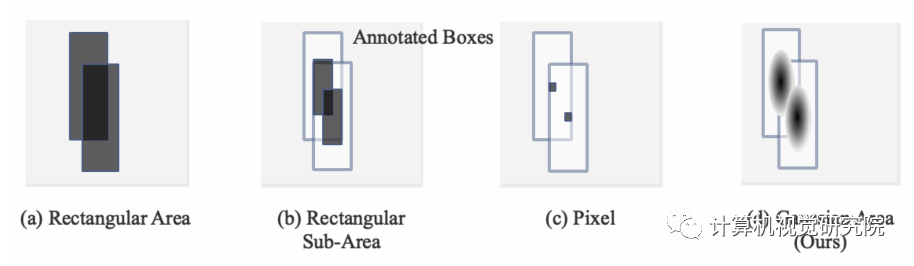
3、在精度方面,实验显示res18下与CenterNet都在COCO上达到了28.1的mAP,但0.5的mAP比CenterNet低了1个点左右,0.75的mAP比CenterNet高了0.6个点,所以猜测TTFNet可能检测出的bbox更加紧凑,因此提高了mAP。


扫码关注我们
公众号 : 计算机视觉战队
关注回复:TTFNet,获取源码

简要
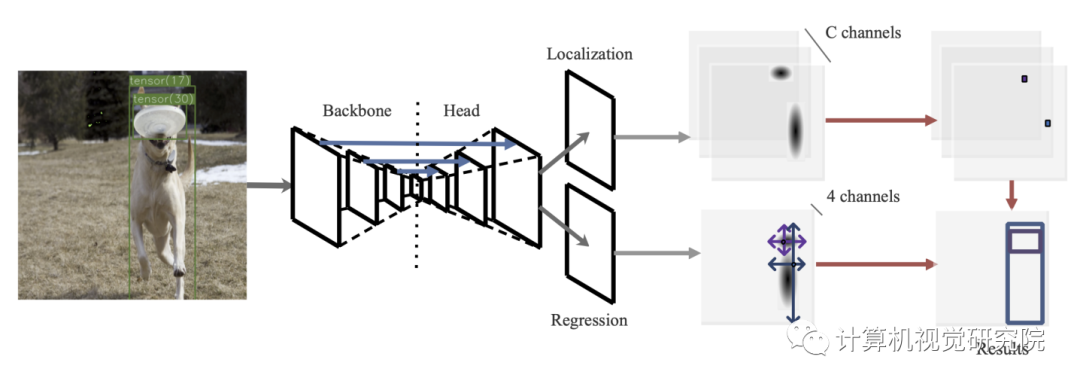
现在目标检测器很少能同时实现训练时间短,推理速度快,精度高。为了达到平衡,作者就提出了Train-Friendly Network(TTFNet)。作者从light-head, single-stage, and anchor-free设计开始,这使得推理速度更快。然后作者重点缩短训练时间。
我们注意到,从注释框中编码更多的训练样本与增加批处理大小具有相似的作用,这有助于扩大学习速率和加速训练过程。为此作者就介绍了一种利用高斯核对训练样本进行编码的新方法。此外,为了更好地利用信息,还设计了主动样本权重。在MSCOCO上的实验表明,TTFNet在平衡训练时间、推理速度和精度方面具有很大的优势。它比以前的实时检测器减少了7倍以上的训练时间,同时保持了最先进的性能。此外,super-fast版本的TTFNet-18和TTFNet-53可以分别是SSD300和YOLOv3的训练时间不到十分之一。
根据Linear Scaling Rule,可以通过增大batchsize提高learning rate,然而仔细分析SGD的公式,我们也可以通过增加高质量的正样本个数来起到同样的作用。也就是不仅可以增大n,也可以增大m。
回顾随机梯度下降(SGD)的公式,权重更新表达式可以描述为:
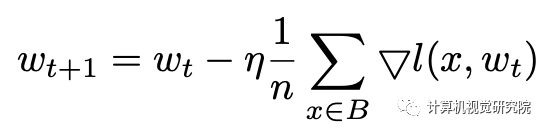
至于目标检测,图像x可以包含多个注释框,这些框将被编码到训练样本s∈Sx。Mx=|Sx|表示图像x中所有框产生的样本数, 因此上公式可以表述为:
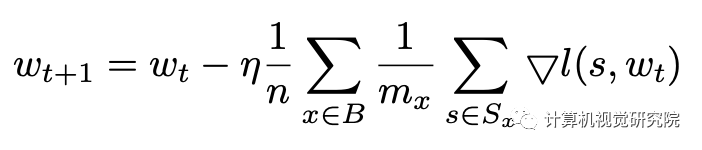
为了简化,假设mx对于小批量B中的每个图像x是相同的。关注个体训练样本s,上式可以改写为:
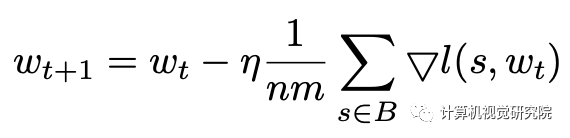
线性缩放规则是在经验中发现的,如果批处理大小乘以k,则学习速率应该乘以k,除非网络正在迅速变化,或者采用非常大的mini-batch批处理。也就是说,用小的mini-batch Bj和学习速率η执行k迭代基本上相当于用大的mini-batch ∪j∈[0,k)Bj和学习速率kη执行1迭代,只有当我们可以假设:
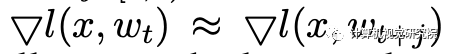
这个条件通常是在大规模的真实世界数据下满足的。
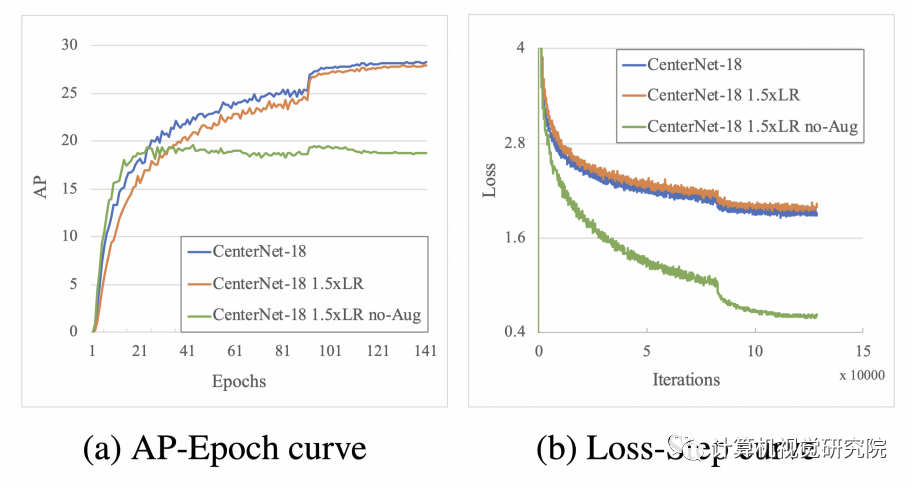
较大的学习速率不能帮助CenterNet更快地收敛,并且删除数据增强会导致性能变差。根据上面的结论,我认为这是因为CenterNet在训练过程中只在目标中心编码一个单一的回归样本。这种设计使得CenterNet在很大程度上依赖于数据增强和较长的训练时间,导致不友好的训练时间。