【中国AI实验室项目巡礼】中大HCPLab:基于注意力机制学习的人脸幻构
1新智元专栏
作者:曹擎星
【新智元导读】 在新智元20万读者大调查的反馈中,不少读者朋友反映希望看到更多关于国内人工智能领域实验室及其研究项目的介绍。我们今天为大家带来的是中山大学人机物智能融合实验室(中大HCPLab)和他们“基于注意力机制学习的人脸幻构”的研究介绍。

我们希望能为读者朋友们介绍一些国内优秀的人工智能领域的实验室和他们的研究项目,今天为大家带来的是中山大学人机物智能融合实验室(中大HCPLab)和他们的“基于注意力机制学习的人脸幻构”研究。
中山大学人机物智能融合实验室(http://hcp.sysu.edu.cn)依托于中山大学数据科学与计算机学院,围绕“人工智能原创和前沿技术”布局研究方向与课题,并与产业界开展广泛合作,输出大量原创技术及孵化多个创业团队。
在感知计算与智能学习、机器人与嵌入式系统、人机协同技术、大数据挖掘与分析等领域开展研究,以“攀学术高峰、踏应用实地”为工作理念。实验室目前有教授1名,副教授2名,特聘研究员4名,工程师3名。

中山大学人机物智能融合实验室人员:从左到右依次为——林倞 王青 成慧 张冬雨 李冠彬 陈崇雨 刘中常
其中林倞教授担任商汤集团执行研发总监,是国家优秀青年科学基金获得者,教育部超算工程软件工程研究中心副主任,2017年入选IET Fellow;成慧副教授是中山大学“百人计划”人才引进,分别在香港科技大学和香港大学获得硕士、博士学位;王青副教授获得Google ResearchAward,并曾在麻省理工大学媒体实验室(MIT Media Lab)访问工作。实验室承担或者已完成各级科研项目30余项,共获得科研经费超过数千万元。科研团队迄今在顶级国际学术期刊与会议上发表论文100余篇,包括在IEEE/ACM Trans汇刊发表论文50余篇,在CVPR/ICCV/NIPS/Multimedia/AAAI/IJCAI等顶级会议发表论文40余篇,获得NPAR 2010 BestPaper Award, ACM SIG CHI Best Paper Award Honorable Mention, ICME 2014 BestStudent Paper, The World’s FIRST 10K Best Paper Diamond Award by ICME 2017等奖励。
而在上个月的CVPR 2017计算机视觉顶级年度会议上,林倞教授带领的实验室团队在本次大会共有7篇paper被收录。以下为大家精选一项人脸幻构技术作为分享。
基于注意力机制学习的人脸幻构
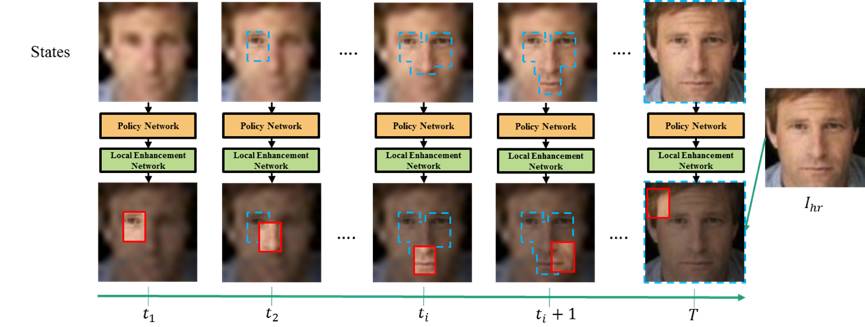
低分辨率人脸图像复原,指的是利用一副或者多幅低分辨率的人脸图像恢复出清晰并且高分辨的人脸图像。目前主流的复原方法都是尝试学习低分辨率图像区域到高分辨率图像区域的映射,而没有对不同区域相关关系进行建模。在监控视频等实际应用场景中,人脸分辨率通常很低,这类方法较难以恢复出高分辨率人脸。针对此难点,我们提出了Attention-awareFace Hallucination增强学习模型框架,旨在通过循环地选择并复原低分辨人脸图像上的不同区域来实现低分辨率人脸的超分辨重建。具体来说,策略网络(Policy Network)将基于之前部分复原的人脸图像,选择一个待复原区域;另一个局部增强网络(local enhancementnetwork)将参考之前复原的结果,仅对该区域进行增强。这样的方式使得区域在进行复原时能获得其它已增强区域的信息,从而在整个图像上对区域的关系进行建模。训练模型时,我们同时对策略网络和局部增强网络进行训练。使用强化学习的方法,将全图的PSNR为奖励信号训练策略网络,使用每一步的局部均方误差训练局部增强网络。我们在LFW上进行了实验,结果表明,我们提出的这项算法大大优于当前最好的算法。

图1. 对局部区域进行超分辨率重建时,给出相关高清区域信息将使复原变得更为简单
模型:
下图2是我们Attention-aware Face Hallucination的整体框架示意图:
图2. Attention-aware Face Hallucination的整体框架示意图
在每一步,输入之前的全图增强结果,使用策略网络选取全图的一块区域,并通过局部增强网络进行图像增强,增强的结果将拷贝并覆盖至原图,并作为下一步的输入。重复该步骤T次,得到最终的复原结果。
策略网络和局部增强网络模型细节过程如图3所示:
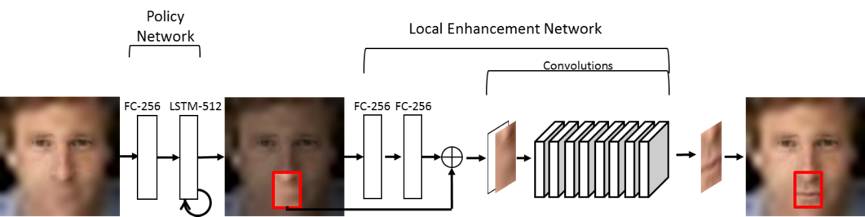
图3 策略网络和局部增强网络模型细节过程
在每一步中,策略网络的输入为上一轮产生的“状态”。“状态”包含两个部分,一部分是之前所有步骤在全图的局部增强结果,另一部分是S3中策略网络里长短期记忆网络产生的隐向量。策略网络将输入图像拉成一个长向量,经过一个全连接层,和一个长短期记忆网络产生一个512维的隐变量,该隐变量通过全连接层输出原图大小的概率图。我们依据概率图,随机采样出一个固定大小的图像区域。
局部增强网络则同样将之前的增强结果使用两层全连接层进行编码,然后通过另一层全连接层缩放至和选择区域同样大小的特征图,并和图像区域合并在一起,经过卷积神经网络得到增强的图像区域,放回到输入图像中。
我们使用两种不同的训练方法来同时训练策略网络和局部增强网络。对于局部增强网络,我们使用选择区域和高分辨图像区域的均方误差作为损失函数,使用梯度下降的方法训练网络。而策略网络的区域选择并没有监督信息,我们使用强化学习的方法进行训练。设定奖励信号R为最后恢复出的图像与原始的高分辨率图像之间的均方误差。这种延迟的全局奖励信号能训练策略网络,使得网络更多的考虑整个序列选择的区域和选择的顺序,提高最终的恢复效果。
实验:
我们在LFW和BioID数据集上测试了8倍降采样和4倍降采样人脸图像的恢复效果,相比于之前的方法有了较大的提高:
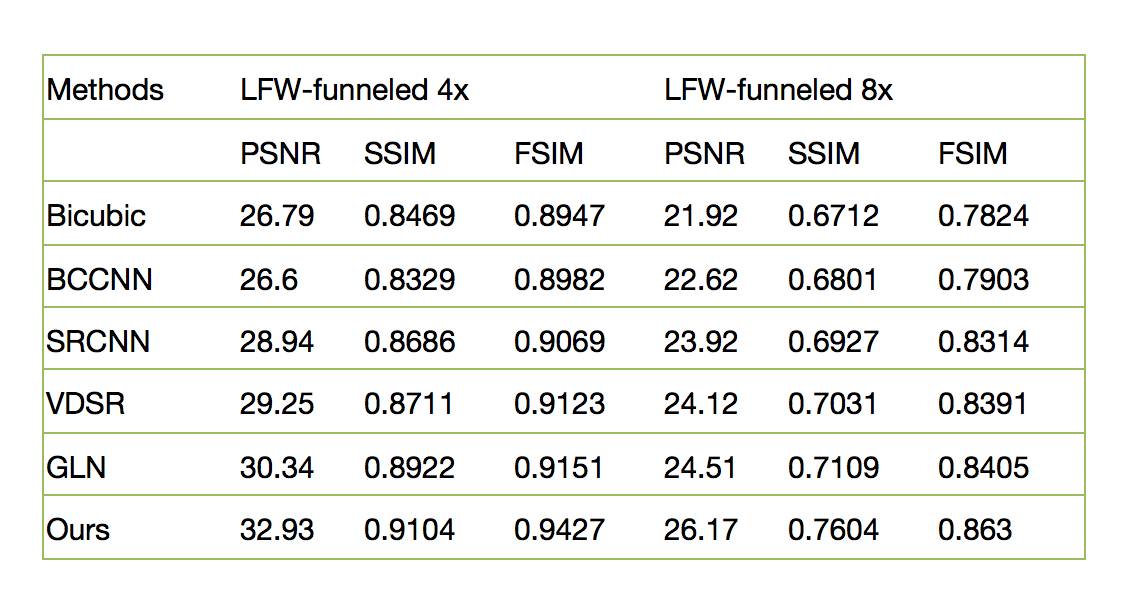
图4. 部分复原图像的可视化结果:

图4
附录:
1. 论文信息:
“Attention-AwareFace Hallucination via Deep Reinforcement Learning”, Qingxing Cao, Liang Lin*, Yukai Shi,Xiaodan Liang, and Guanbin Li,roc. of IEEE Conference on Computer Vision andPattern Recognition (CVPR), 2017.
2. 中山大学人机物智能融合实验室官网对应论文链接:http://hcp.sysu.edu.cn/attention-aware-face-hallucination/
3. 论文下载链接:http://openaccess.thecvf.com/content_cvpr_2017/papers/Cao_Attention-Aware_Face_Hallucination_CVPR_2017_paper.pdf
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~





