AAAI 2018 | 浙江大学提出设计网络嵌入算法的度惩罚原则,可有效保留无标度特性
选自arXiv
作者:Rui Feng、Yang Yang、Wenjie Hu、Fei Wu、Yueting Zhuang
机器之心编译
参与:Jane W、刘晓坤
在 AAAI 2018 接收论文列表中,来自浙江大学的 Rui Feng 等研究者的一篇论文提出设计网络嵌入算法的度惩罚原则,可有效保留无标度特性,重构重尾分布的度分布,克服传统网络嵌入算法对高度顶点数量估计过高的缺点。机器之心对此论文做了简要介绍,更多详细内容请查看原文。
由于网络能够编码丰富而复杂的数据(如人际关系和互动),网络分析(network analysis)已经在人工智能的许多领域吸引了大量的研究工作。网络分析的一个主要挑战是如何正确表示网络,以保留网络的结构特性。最直接的方法是用邻接矩阵(adjacency matrix)表示网络。但邻接矩阵会受到数据稀疏性的影响。其它传统的网络表征依赖于人工设计的网络特征(例如聚类系数),不够灵活、不可扩展,并且需要艰苦的人力。
本文研究了学习保留无标度(scale-free)特性的网络嵌入(Network Embedding)问题。作为一个网络的表征,顶点(vertex)嵌入向量被认为可以很好地重构网络。现存的多数算法都是在欧氏空间学习网络嵌入。然而,我们发现大多数传统的网络嵌入算法会对高度(high degree)顶点的数量估计过高。图 1(b)给出了一个例子,其表征由拉普拉斯特征映射(Laplacian Eigenmap)学习得到。我们尝试从理论上分析和理解这一点,并研究通过把我们的问题转化为高维球体填充问题(Sphere-Packing Problem),在欧氏空间中恢复幂律分布(power-law distributed)顶点度的可行性。通过分析,我们发现从理论上,适度增加嵌入向量的维度有助于保留无标度特性。详见第 2 部分。
为了验证方法的有效性,我们在第四部分中对合成数据和五组真实数据集进行了实验。实验结果表明,我们的方法不仅能够保留网络的无标度特性,而且在不同的网络分析任务中优于最先进的嵌入算法。论文的贡献总结如下:
我们通过将问题转化为高维球体填充问题,分析了在欧氏空间中基于学习到的顶点表征来重构无标度网络的难度和可行性。
我们提出度惩罚(degree penalty)原则和两个实现来保留网络的无标度特性,并提高顶点表征的有效性。
我们通过进行大量实验来验证我们提出的原则,并发现与几个最先进的基线算法相比,我们的方法在 6 个数据集和 3 个任务上有显著提升。
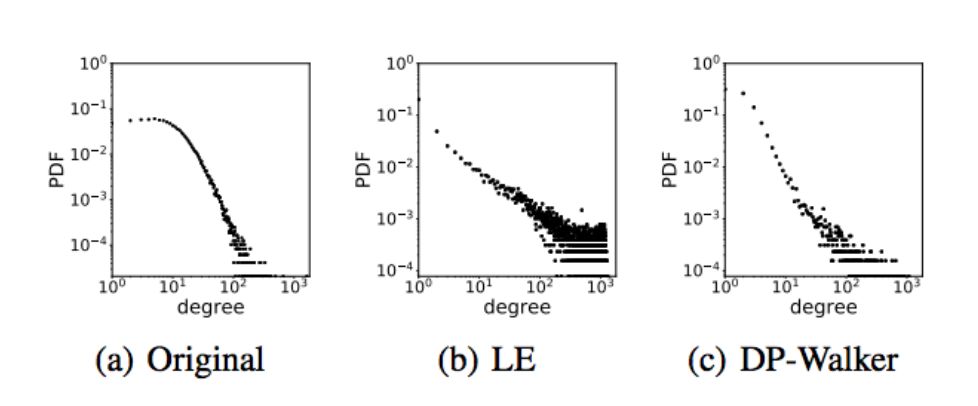
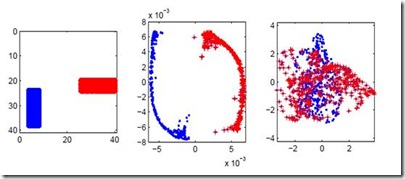
图 1:真实网络的无标度特性。(a)是一个学术网络的度分布。(b)和(c)分别是基于拉普拉斯特征映射(LE)和我们提出的方法(DPWalker)学习的顶点表征重构的网络的度分布。
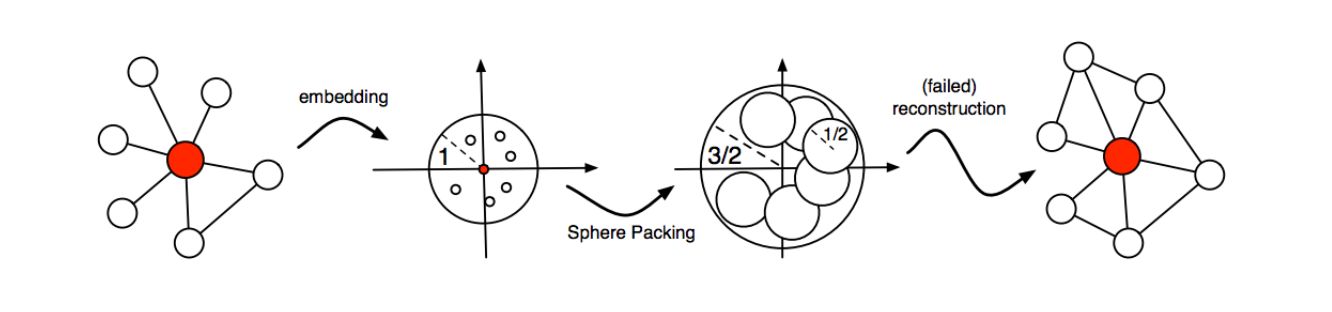
图 2:从左到右:一个以集线器顶点为中心的自我中心网络(ego-network),一个可能的嵌入解决方案(等价于一个高维球填充解决方案),但导致重构失败,其中高度顶点的数目被估计过高。

表 1:数据集的统计数字。|V| 表示顶点的数量,|E| 表示边的数量。
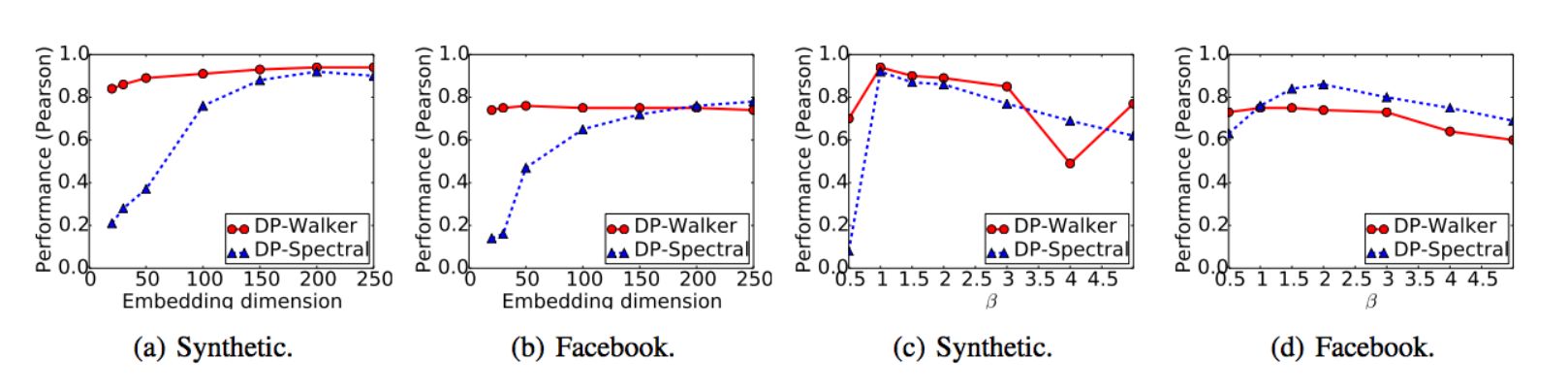
图 3:模型参数分析。(a)和(b)分别展示了合成数据集和 Facebook 数据集中嵌入维度 k 的敏感性。(c)和(d)表示度惩罚参数 β 的敏感性。由于空间限制,我们忽略了其它数据集上的结果。
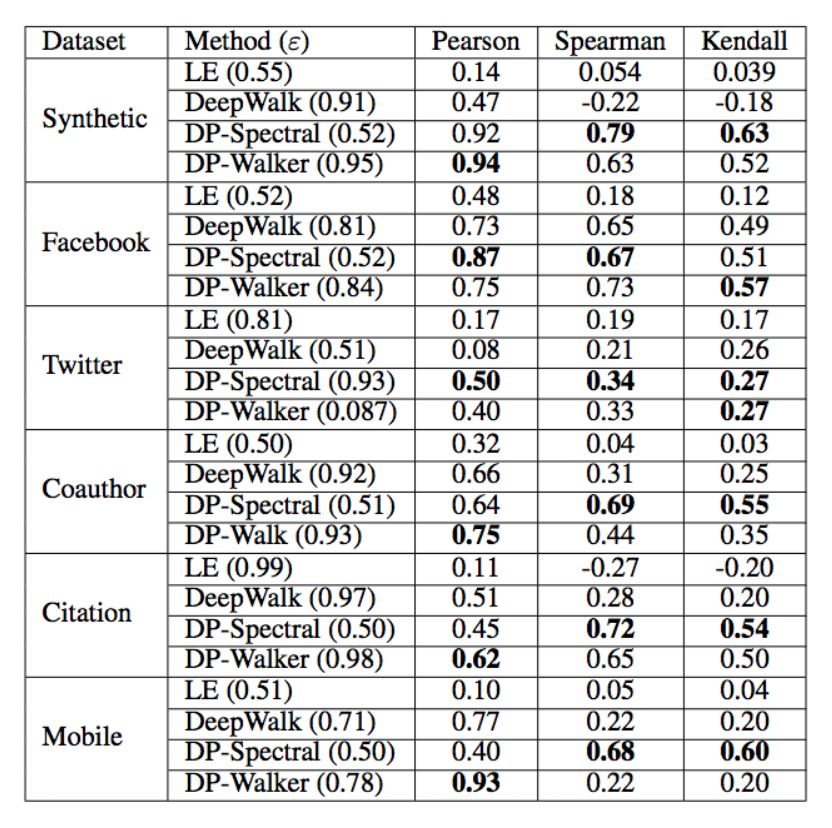
表 2:不同方法在无标度特性重构中的表现。对于每种方法,选择使 Pearson 系数最大化的 ε。
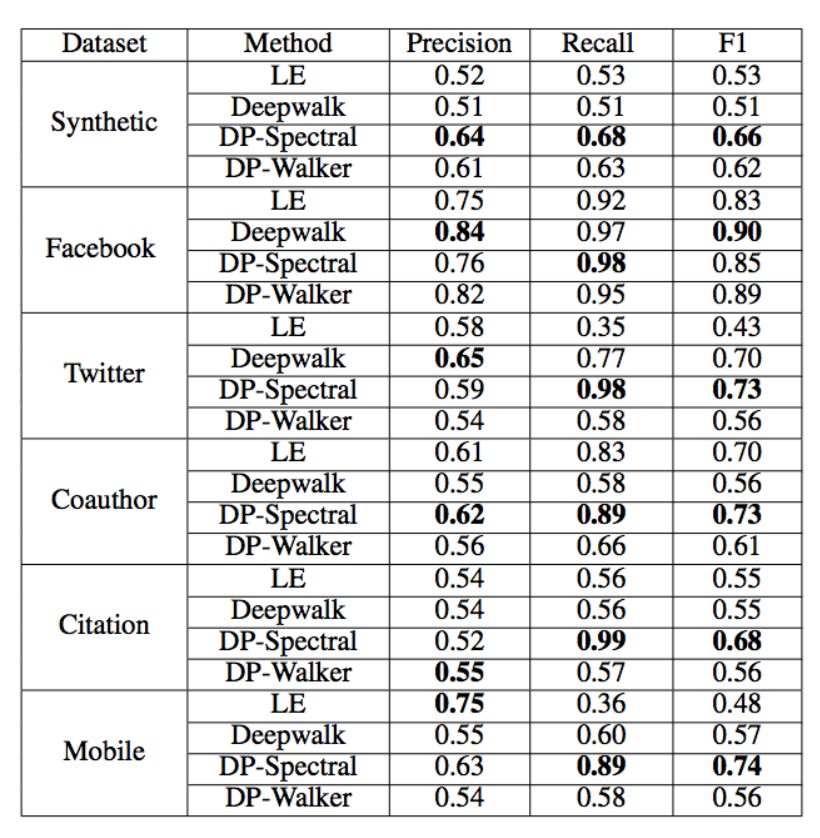
表 3:连接(link)预测的实验结果。
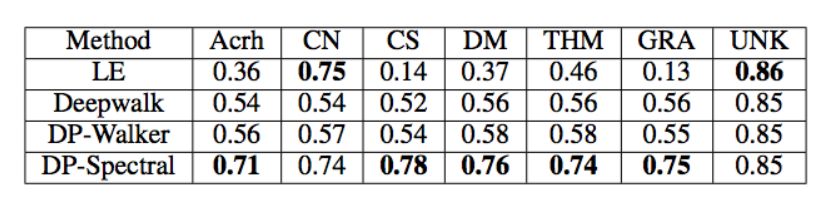
表 4:多分类任务的准确率。标签简写分别代表架构(Architecture)、计算机网络(Computer Network)、计算机科学(Computer Science)、数据挖掘(Data Mining)、理论(Theory)、图论(Graphics)和未知(Unknown)。
论文:Representation Learning for Scale-free Networks

论文链接:https://arxiv.org/abs/1711.10755
网络嵌入(network embedding)的目的是学习网络中顶点的低维表征,同时保留网络的结构和固有特性。现有的网络嵌入研究主要集中在保留微观结构上,如顶点的一阶和二阶近似(proximity),而宏观无标度(scale-free)特性在很大程度上被忽略。无标度特性描绘了顶点度服从重尾(heavy-tailed)分布(即只有少数顶点具有高维度)的情形,这也是真实网络(例如社交网络)的关键特性。在本文中,我们研究学习无标度网络的表征问题。我们首先通过把我们的问题转化为高维球体填充(sphere packing)问题,从理论上分析了在欧氏空间嵌入和重构一个无标度网络的困难。然后,我们提出了保留无标度特性的网络嵌入算法的度惩罚(degree penalty)原则:惩罚高维度顶点之间的近似度。我们分别利用谱技术(spectral technique)和 Skip-Gram 模型来引入基于我们原则的两个实现。在 6 个数据集上的大量实验表明,我们的算法不仅可以重构重尾分布的度分布,而且还可以超过各种网络挖掘任务(如顶点分类和连接预测)中最先进的嵌入模型的效果。
其它 AAAI 2018 论文:
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论