成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
拉普拉斯特征映射
关注
273
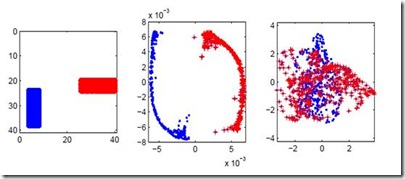
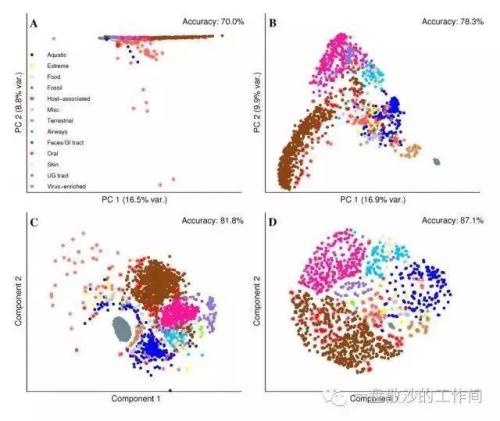
拉普拉斯特征映射 是用局部的角度去构建数据之间的关系。如果两个数据实例i和j很相似,那么i和j在降维后目标子空间中应该尽量接近。它的直观思想是希望相互间有关系的点(在图中相连的点)在降维后的空间中尽可能的靠近。Laplacian Eigenmaps可以反映出数据内在的流形结构。
综合
百科
VIP
热门
动态
论文
精华
精品内容
没有数据了, 换个别的吧!
参考链接
父主题
数据降维
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top