仅需2小时学习,基于模型的强化学习方法可以在Atari上实现人类水平
选自arXiv
作者:Łukasz Kaiser 等
机器之心编译
参与:Tianci LIU、Chita
无模型强化学习方法能够用来学习复杂任务(如雅达利游戏)的有效策略,但通常却需要大量的交互,这也意味着更多的时间和更大的成本。本文尝试用基于模型的强化学习方法让智能体在雅达利游戏上达到相似的效果,并比较了几种模型架构。实验结果表明,仅需 10 万次智能体和环境之间的交互(约 2 小时的实时学习),基于模型的方法就能实现有竞争力的结果。
无模型强化学习(RL)能够用于学习复杂任务(如雅达利游戏)的有效策略。但这通常需要非常大量的交互——事实上,比人类掌握相同游戏需要的尝试多多了。为什么人类可以学习如此之快?部分原因可能是,人类能够学习游戏原理,并预测出哪个动作会带来想要的结果。在本文中,研究人员探索了如何基于视频预测模型让智能体在雅达利游戏上达到类似的效果,同时所需的交互比无模型方法要少?
研究人员讨论了模拟策略学习(Simulated Policy Learning,SimPLe)——一个基于视频预测模型的完全无模型深度强化学习算法,并比较了几种模型架构,包括在本文设定下产生最优结果的一种全新架构。研究人员在一系列雅达利游戏上测试评估了 SimPLe,结果显示,仅仅通过 10 万次智能体和环境之间的交互(40 万帧),SimPLe 就可得到有竞争力的结果。
基于模型的学习算法
在本文的方法中,智能体利用由预测模型生成的想象经验完成学习。为此,至关重要的一点是,收集到的关于环境的数据必须足够多样化,以确保习得模型能够在所有关键场景下正确复现出环境的动态。在绝大多数雅达利游戏中,随机探索(exploration)并不足以实现此目标。为了以更直接的方式进行探索,研究人员使用了迭代过程,由以下阶段交替组成:数据收集、模型训练、策略训练,借此,随着策略变得更优,所收集到的数据也具有更多意义,因此可以学习逐渐变好的模型。策略训练使用的是 PPO 算法。
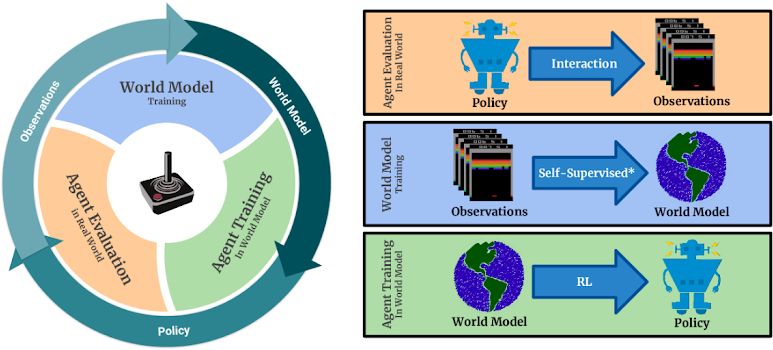
图 1:SimPLe 的主要循环过程。1)智能体开始根据最新策略(随机初始化)与真实环境进行交互。2)收集到的观测结果被用来训练当前及更新的世界模型(world model)。3)智能体通过在世界模型中采取行动来更新策略。评估新策略以衡量智能体的表现和收集更多数据(回到第 1 步)。注意,世界模型训练对观测到的状态进行自监督,对奖励进行监督。
随机离散模型
本文的智能体从视频预测模型所生成的原始像素观测结果中学习。研究人员试验了几种架构,效果最好的模型是前馈卷积神经网络。它利用一组卷积对一系列输入帧进行编码,并给定智能体采取的行动,然后利用一组解卷积对下一帧进行解码。奖励是基于瓶颈表征(bottleneck representation)预测的。
研究人员发现,将随机性引入模型会带来不错的效果,可以让策略在训练阶段尝试更多不同的场景。为此,研究人员添加了一个隐变量,而来自隐变量的样本被添加至瓶颈表征。在离散变量该设定下效果最优,被编码为比特序列。模型的整体架构类似于变分自编码器,其中隐变量上的后验是基于整个序列(输入帧+目标帧)近似得到,从该后验中抽取一个值,并将该值与输入帧和行动一起用于预测下一帧。在推断阶段,潜代码(latent code)由自回归 LSTM 网络生成。
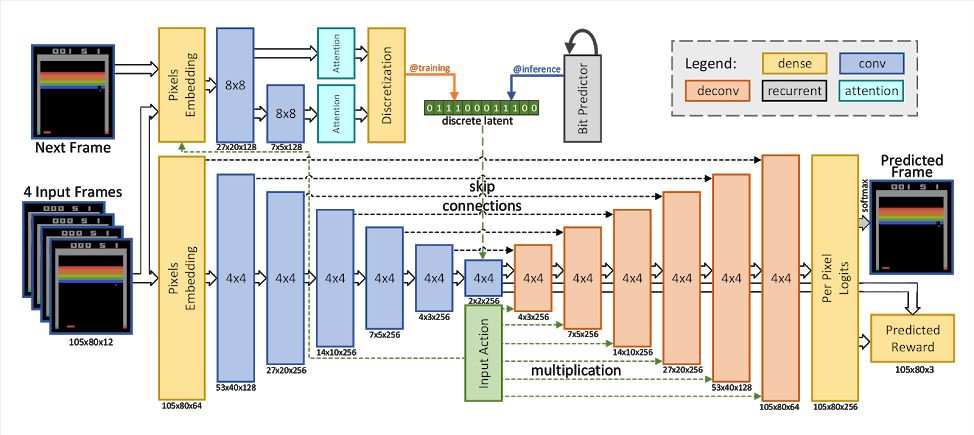
图 2:带有离散隐变量的随机模型架构。模型输入是 4 个堆叠的帧(以及智能体选择的策略),输出则是预测的下一帧及预期奖励。利用全连接层嵌入输入像素和行动,在输出中有像素级的 softmax(256 色)函数。该模型有两个主要组成部分。首先,网络底部由带有残差连接的卷积编码器和解码器组成。为了根据智能体的行动调节输出,解码器中每一层的输出都乘以(习得的)嵌入行动。模型的第二部分是卷积推断网络,类似于 Babaeizadeh 等人 (2017) 的观点,它在给定下一帧的条件下近似估计后验。在训练阶段,从近似后验抽样得到的隐变量值将离散化为比特。为使模型可微,反向传播根据 Kaiser & Bengio (2018) 的方法避开离散化,并训练第三个基于 LSTM 的网络,以在给定先前比特时近似估计当前比特。在推断阶段,利用该网络自回归地预测隐比特。确定性模型(deterministic model)与上图架构相同,但不包含推断网络。
结果
本文的主要目的是利用无模型方法实现当前最佳的样本效率。这引出了以下问题:在适度的 10 万次交互(2 小时的实时学习)中,可以获得怎样的分数?
研究人员对本文方法与 Rainbow(在雅达利游戏上当前表现最佳的无模型算法)进行了比较,然后根据该方法与环境的一百万次交互重新调整,以获得最优结果。并与训练中使用的 PPO 实现进行了对比。结果如下所示,说明了为获得与本文方法相同的分数,无模型算法所需要的交互次数。红线表示本文方法所使用的交互次数。不难看出,使用该方法可以将大多数游戏上的样本效率提升两倍不止。
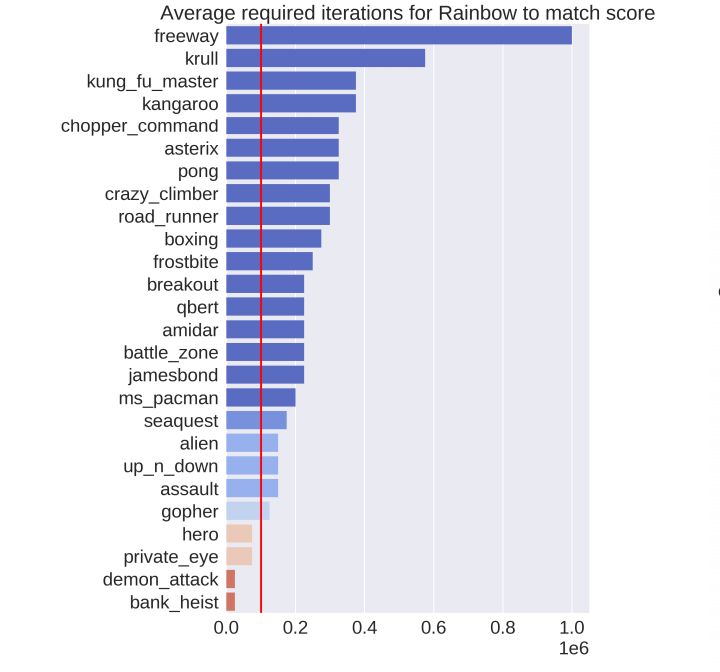
图 3:本文方法与 Rainbow 的对比。每个长条说明:为达到和本文方法(SimPLe)相同的分数,Rainbow 所需与环境进行交互的次数。红线表示 10 万次交互的阈值,是 SimPLe 所使用的次数。
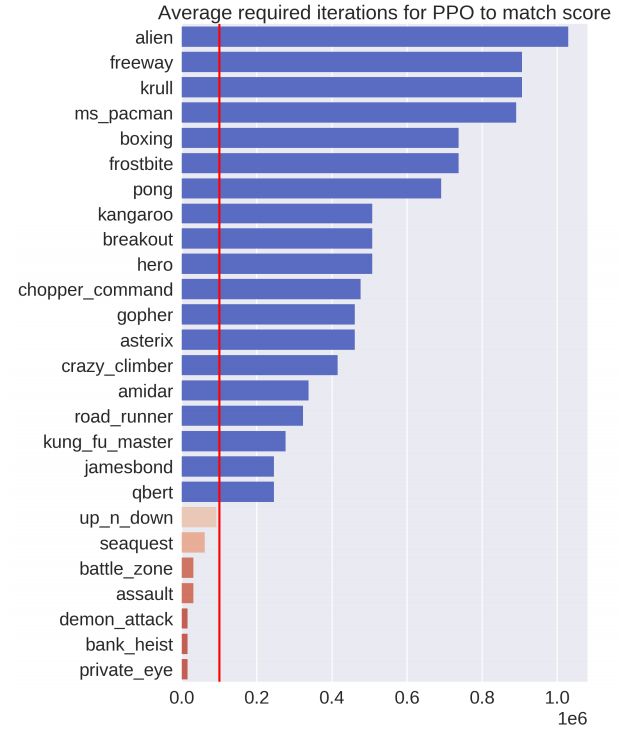
图 4:本文方法与 PPO 的对比。每个长条表示:为达到和本文方法(SimPLe)相同的分数,PPO 所需与环境进行交互的次数。红线表示 10 万次交互的阈值,为 SimPLe 所使用的次数。
通关游戏
另人惊喜的是,在 pong 和 Freeway 两款游戏上,本文完全在模拟环境下训练的智能体在真实游戏中表现突出:分别获得了最高分。需要强调的是,没有为每个游戏单独调整方法和超参数。
下面的视频是 Pong 的一个首秀,本文方法习得的策略获得了 21 分的满分。
Freeway 也是一个非常有趣的游戏。虽然简单,但却是一个巨大的探索挑战。由智能体操控的鸡,在进行随机探索时上升速度很慢,因为它总是会被汽车撞到。这使得它完全通过马路并获得非零奖励几乎是不可能的。然而,SimPLe 能够捕获这种罕见的事件,并将其转化为预测模型,进而成功习得获胜策略(见视频)
论文:Model Based Reinforcement Learning for Atari

论文地址:https://arxiv.org/pdf/1903.00374.pdf
摘要:无模型强化学习能够用于在复杂任务(如雅达利游戏,甚至基于图像观测)中学习非常有效的策略。但是,这通常需要非常大量的交互——事实上,比人类掌握相同游戏需要的次数更多。为什么人类可以学习如此之快?部分原因可能是,人类能够学习游戏原理,并预测出哪个动作会带来想要的结果。在本文中,我们探索了如何基于视频预测模型来达到类似效果,让智能体能够通过更少的交互(相较于无模型方法而言,次数降低了几个数量级),通过雅达利游戏。本文讨论了模拟策略学习(SimPLe),一个基于视频预测模型的完全基于模型的深度强化学习算法,并比较了几种模型架构,包括一个在本文设定下得出最优结果的全新架构。我们在一系列雅达利游戏上测试评估了 SimPLe,实验结果显示,仅通过 10 万次智能体和环境之间的交互(40 万帧),约 2 小时的实时学习,SimPLe 就可获得有竞争力的结果。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
