【SIGIR2017满分论文】IRGAN:大一统信息检索模型的博弈竞争
新智元译介
作者:汪军 张伟楠等
编译:张易
【新智元导读】SIGIR 2017 三个 strong accept 满分录取的论文《IRGAN:大一统信息检索模型的博弈竞争》(IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models),在 GAN 的启发下,提出了 IRGAN 框架,通过极小化极大算法中的对抗性训练统一了生成式和判别式 IR 模型这两种信息检索方法学派。研究者在四个现实世界数据集上,对三个典型的 IR 任务(即网络搜索、项目推荐和问答)进行了广泛实验,在每组实验中都观察到了显著的性能提升。
在介绍论文内容之外,我们特别讲述了研究的缘起以及研究背后中英两方团队的协作方式,相信能为您带来一定的启发。
在新智元微信公众号回复“IRGAN”下载论文。【新智元独家首发】

作为信息检索领域顶级学术会议,将于 8 月 7 日—11 日在东京举行的 SIGIR 2017 上,有一篇华人研究者提交的论文以三个 strong accept 的满分录取,高居 362 篇论文之首。
这篇论文的题目是《IRGAN:大一统信息检索模型的博弈竞争》(IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models)。第一作者是伦敦大学学院(UCL)长期做信息检索(IR)方面基础研究的汪军教授,他学生时代的导师是 IR 界的泰斗 Stephen Robertson(概率排序原则的发明人)和当前最有影响力的教授之一 Arjen de Vries。另一位通讯作者张伟楠则主持了实验工作,他是汪军教授的学生,目前已在上海交大任教。这篇论文从提出设想到展开实验,直至团队迭代完成论文撰写,都是中英双方团队通力协作的结果。在介绍了论文内容后,我们拿出了专门的篇幅,为你讲述这篇论文背后的故事,希望能给中国研究者一些借鉴和激励。

本文提供了信息检索建模中两种思维流派的统一描述:聚焦于对给定查询的相关文档生成检索模型,以及重点在于预测查询文档的相关性的判别检索模型。我们提出了一个博弈理论式的极小化极大算法来迭代地优化这两个模型。一方面,旨在从标记和未标记数据中挖掘有效信号的判别模型,为训练生成模型提供了指导,以适应在给定查询的文档上隐含的相关性分布。另一方面,作为现有判别模型攻击者的生成模型,通过最小化其判别目标,以对抗的方式,生成对于判别模型来说高难度的样本。
随着这两种模型之间的竞争,我们论证了,统一框架利用了两种思维方式:(i)生成模型通过判别模型的信号学习适应文档的相关性分布;(ii)判别模型能够利用生成模型选择的未标记数据来实现对文档排序的更优评估。我们的实验结果展现出显著的性能优化,在网页搜索、推荐和问答系统等各种应用中,在 Precision@5 和 MAP 上分别超越强基准算法 23.96% 和 15.50%。
信息检索(IR)的典型方法是提供给定查询的文档(排序)列表。它具有广泛的应用,仅举几例,如文本检索、网页搜索、推荐系统、问答和个性化广告。谈到 IR理论和建模,一般认为有两个主要的思维流派。
经典的思维流派是假设在文档和信息需求(由查询可知)之间存在着一个独立的随机生成过程。在文本检索中,信息检索的经典相关模型聚焦在描述如何从给定的信息需求生成(相关)文档:q → d,其中 q 是查询(例如关键字、用户信息、问题,取决于具体的 IR 应用程序),d 是其相应的文档(例如文本文档、商品、答案),箭头表示生成方向。值得注意的例子包括 Robertson 和 Sparck Jones 的二进制独立模型,其中每个单词标记都是独立生成的,以形成相关文档。
文本检索的统计语言模型考虑从文档到查询的逆生成过程:d → q,通常从文档生成查询词(即查询似然函数)。在词嵌入的相关工作中,词汇标记是从他们的上下文词汇生成的。在推荐系统应用中,我们还看到,可以从已知的上下文项目中生成/选择推荐的目标项目(在原始文档标识空间中)。
现代的 IR 思想流派认识到了机器学习的力量,并转向了从标记的相关判断或其代表事件(如点击或评级)中学习判别(分类)解决方案。它将文档和查询联合考虑为特征,并从大量训练数据中预测其相关性或排序顺序标签:q + d → r,其中 r 表示相关性,符号+ 表示特征的组合。网页搜索的一个重大进展是学习排序(learning to rank,LTR),这是一系列机器学习技术,其中训练目标是提供给定查询(或上下文)的文档列表的正确排序。
学习排序的三个主要模式是逐点的(pointwise)、成对的(pairwise)和列表的(listwise)。对于每个文献的相关性,逐点法通过学习,逐渐逼近人类评价出的相关性;成对法旨在从任何文档对中识别更相关的文档。列表法学习优化每个查询在整个排名列表上定义的(平滑)损失函数。此外,推荐系统的最新研究进展是矩阵分解,其中用户特征和项目特征的交互模式通过向量内积被利用来进行相关性的预测。
虽然信息检索的生成模型在为特征建模(例如文本统计、文档标识符空间分布)方面理论坚实,非常成功,但它们在利用来自其他渠道的相关性信号(如链接,点击等等)方面遇到了很大的困难,这主要可以在基于互联网的应用中观察到。虽然诸如学习排序的信息检索判别模型能够从大量的标记/未标记数据中隐式地学习检索排序函数,但是它们目前缺乏从大量未标记数据中获取有用特征或收集有用信号的原则性方法,特别是从文本统计(源自文档和查询两方面)或从集合内相关文档的分布中。
在本文中,我们认为生成和判别检索模型是同等重要的,就像同一枚硬币的两面。受机器学习中生成对抗网络(GAN)的启发,我们提出了一个博弈理论式的极小化极大算法来结合上述两种思维方式。具体来说,我们为两个模型定义一个共同的检索函数(例如基于判别的目标函数)。一方面,判别模型 pφ(r | q,d)旨在通过从标记数据中学习来最大化目标函数。它自然地提供了超越传统对数似然性的生成检索模型的替代性指导。另一方面,生成检索模型 pθ (d |q, r ) 充当挑战者,不断地将判别器推向其极限。它为判别器迭代地提供最困难的情况,判别器通过对抗地最小化目标函数来重新训练自身。
以这种方式,两种类型的检索模型在极小化极大算法中扮演了比赛中的双方,都会在每一场比赛中努力提高自己以“打败”对手。请注意,我们的极小化极大算法,和现有的博弈理论式的 IR 方法有根本性的不同。因为现有的方法通常是试图为用户与系统之间的交互建模,而我们的方法旨在统一生成式和判别式 IR 模型。
在实践中,我们已经在三个典型的IR 应用中实现了提出的极小化极大检索框架:网页搜索、项目推荐和问答。在我们的实验中,我们发现极小化极大算法达到了不同的均衡,因此在不同的环境设定下,有不同的统一效果。通过逐点对抗训练,生成检索模型可以通过判别检索模型的训练奖励来显著提高。在 Precision@5 上,和几个强基准相比,得到的模型在网页搜索中提高了 22.56%,在项目推荐中提高了 14.38%。我们还发现,通过新的成对对抗训练,判别检索模型在很大程度上得到了生成检索模型所选择的样本的推动,和所选择的强力算法相比,在Precision@5 网络搜索上提高了 23.96%,而在 Precision@1 问答任务中提高了 3.23%。
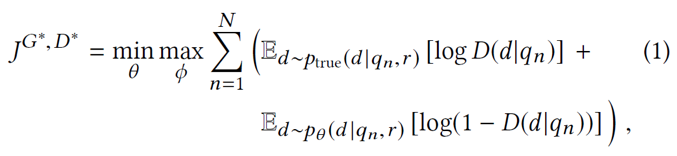

算法1
我们提出的IRGAN解决方案的总体逻辑总结在算法1 中。在对抗训练之前,生成器和判别器可以通过其常规模型初始化。之后,在对抗训练阶段,生成器和判别器在等式(5)和(3)中以另外的方式训练。
判别器和生成器是如何相互帮助的?对于positive的文档,无论是否被观察到了,它们由判别器 fφ(q,d) 和条件概率密度 pθ(d| q,r) 给出的相关性分数可能在一定程度上正相关。在每个训练阶段,生成器试图产生接近判别器决策边界的样本,以对下一轮训练造成迷惑,而判别器则努力对生成的样本进行判别。由于在 positive 但 unobserved(即 true-positive)的样本和(部分)观察到的 positive 样本之间存在正相关,和其他带有来自判别器信号的样本相比,生成器应该能够学习更快地上推这些positive 但不可观察的样本。

图1
为了进一步解释这个过程,让我们用水中的肥皂打个比方,如图1 所示。在未观察到的 positive 肥皂与观察到的 positive 肥皂之间存在着潜在的连接线(即正相关性),观察到的 positive 肥皂永久漂浮在水面(即判别器的判定边界)上。判别器起着将浮在水面上的未观察到的肥皂敲下水面的作用,而生成器充当选择性地将肥皂浮上水面的水。即使生成器不能完全适应条件数据分布,也仍然可能存在动态平衡,这是在水的不同深度下,positive 和 negative 的未观察肥皂的分布取得稳定时获得的。由于未观察到的 positive 肥皂与水面上的观察到的 positive 肥皂相连接。因此总体而言,它们最后应该能够达到比(未观察到的)negative 肥皂更高的位置。
我们的实验对应于我们提出的 IRGAN 的三个现实世界的应用,即网页搜索、推荐系统和问答系统。由于三个应用程序中的每一个都有自己的背景和基线算法,所以我们的实验分为三个子部分。我们首先在网页搜索的单个任务中测试 IRGAN-pointwise 和 IRGAN-pairwise 方法; 然后在排序偏差不太关键的项目推荐任务中进一步对 IRGAN-pointwise 进行了研究。我们又在排序偏差更为关键(通常只有一个答案是正确的)的问答任务中对 IRGAN-pairwise 进行了测试。
在本文中,我们提出了 IRGAN 框架,通过在极小化极大算法中的对抗性训练来统一两种信息检索方法学派,即生成模型和判别模型。这种对抗性训练框架利用了两个学派的方法学:(i)生成式检索模型受从判别检索模型获得的信号引导,这使得它比非学习方法或最大似然估计方案更有利;(ii)可以通过策略性地让生成器的提供 negative 样本,增强判别式检索模型,从而更好地为文档排序。总体而言,IRGAN 提供了一个更加灵活和有原则的训练环境,结合了这两种检索模型。在四个现实世界数据集上,对三个典型的 IR 任务(即网络搜索、项目推荐和问答)进行了广泛实验。在每组实验中都观察到了显著的性能提升。
尽管 GAN 的实践取得了巨大的成功,但仍有许多问题需要研究人员回答。 例如,现在还“不完全清楚”为什么 GAN 可以产生比其他技术更清晰的逼真图像。我们在提出的 IRGAN 框架中对信息检索的对抗性训练的探索表明,根据任务和设定,最终可以达到不同的均衡。在 IRGAN 的逐点(pointwise)方法版本中,生成检索模型比判别检索模型得到了更多改进,但在 IRGAN 的成对(pairwise)方法中我们得到了相反的观察。 这肯定有待进一步研究。
未来,我们将进行更多的基于实际数据集的进一步实验。我们还计划扩展我们的框架,并对词标记的生成进行测试。一个可能的研究方向是探索从 IRGAN 生成检索模型中学习词加权方案,然后在此基础上导出新的特征排序。此外,语言模型可以随着GAN 训练重新定义,其中可能会出现新的有用的词模式。
1.生成式和判别式,信息检索两大学派
信息检索界一直有两大学派。经典的方法以生成模型为主,大名鼎鼎的概率排序原则(Probabilistic Ranking Principle)和 搜索语言模型(IR Language Model),以及汪军教授(本文的第一作者)的组合排序原则(Portfolio Ranking Principle),其实都是需要生成模型具体量化每个文档对检索关键字的相关度。受机器学习影响,近年有利用大量数据集,通过判别模型训练排序的方法,其中包括,learning to rank 和神经网络的方法。但是两大学派都有优缺点,怎样提供一个大一统的方法一直是没有解决的问题。
2012 年的 9 月底,张伟楠提着行囊远赴英国伦敦汪军教授处求学。汪军教授在伦敦大学学院(UCL)长期做信息检索(IR)方面的基础研究,他学生时代的导师则是 IR 界的泰斗 Stephen Robertson(概率排序原则的发明人)和当前最有影响力的教授之一 Arjen de Vries。
其实关于 IRGAN 的大致思想,汪军和张伟楠很早就已经讨论过。因为通过生成器作为一个很强的带策略的负采样器,肯定能够帮助判别式的排序模型提高头部文档的排序效果,这个现象在他们撰写一篇 SIGIR 2013 的文章时,两人就已经明确发现。GAN 出来以后,汪军一注意到这个对抗训练框架,就立马想到 GAN 可能用来帮助生成式的 IR 模型直接挑选文档(不用做文档排序),甚至生成新的文档,从而达到了统一生成模型和判别模型的目的。不过这个点子一直处在初步思考中,并未成熟。
2.中英团队的合作速度
2016 年 12 月初,已经在上海交大任教的张伟楠突然接到汪军的电话,此时他远在西班牙出席当年的 NIPS,听了 Ian Goodfellow 的 GAN tutorial。一时间,关于用 GAN 来融汇 IR 界的两大派别的解决方案清晰地出现在他的脑中,并且推导出来。理解了 IRGAN 的思路之后,张伟楠立即聚集了交大致远工科的大三学生于澜涛和计算机系研三学生龚禹开展实验工作。龚禹其实已经加入阿里巴巴徐盈辉博士的研究团队。为了能加强交流,张伟楠直接让他俩搬进了自己的办公室,开始了快速迭代开发。后来汪军又联系了天津大学的张鹏教授和他的学生王本友加入项目,团队兵分三路分别在网页排序、个性化推荐、问答系统方面验证 IRGAN 的有效性。而在英国的汪军和 Dell Zhang 教授则着手开始论文的撰写工作。
汪军说:“现在做计算机的研究再也不能单兵作战了,需要一个强大的团队做支撑,工程和数学都要擅长。我不得不说,我们中国研究团队是十分优秀并且令人佩服的。于澜涛和龚禹同学之前都已发表过 AAAI 论文,而王本友同学也在 IR 领域有多篇 SCI 以及 CIKM 论文。这些科研经验让他们在快速迭代 IRGAN 的实验中做出了更好的判断。更让我感到吃惊的是,他们的工作勤奋到令人不敢想象的程度。正是因为他们的勤恳,IRGAN 繁重的实验工作才能在 4 周内全部完成。”
伟楠补充道,“作为小老板的我们也丝毫没有懈怠。我和澜涛龚禹朝夕相处,快速迭代实验开发以及论文的撰写。徐盈辉博士则直接从杭州赶到上海交大和我们详谈了论文和实验的每个细节。在无数次电话会议中就明显感到,徐博士是 hard-core 的 IR 资深研究者,在建模方面为我们出了很多力。天大张鹏教授长期研究 IR 和 QA 方面的课题,他保证了 QA 这一路的实验推进顺利,并和我们配合修改了论文。”
SIGIR 的截稿日期在 1 月 25 日,两天后就是大年除夕。在拼到最后几天的时候,校园里早已是人去楼空,学生们开始有些急躁,张伟楠则和他们在交大咖啡厅喝下午茶,忙里偷闲地把心静下来。而张鹏教授则直接帮学生买好了回家的机票,让他们没有后顾之忧。
汪军说,“中英团队之间的 8 小时时差对我们快速迭代是有利的,英国的工作在深夜结束后,直接提交给中国的团队(已经是中国的第二天清晨)。中国的团队结束后,又可以交给英方。我们基本上是 24 小时不停的快速迭代,保证工作的质量和速度。”
图2
整个团队8个人在 bitbucket 上面提交论文 latex 修改,借助 git 强大的修改 merge 功能,我们总是能多人并行迭代论文工作。在最后的 1 月 24 日那一天,我们的提交次数就超过了 200 次,这个项目的总提交数则在 550 次。
3. 论文接收与后记
在 2017 年 4 月的一天, IRGAN 论文以三个 strong accept 的满分录取,高居 362 篇论文之首。IRGAN 的微信群自然也是欢声笑语一片。
IRGAN 的成功录用只是研究的开始。之前汪军和张伟楠课题组已经合作发表了一篇生成离散文本序列的 SeqGAN 工作。汪军说:“GAN 算是一个双智体群体智能,以对抗为主。我们之前在离散数据的判别和生成方面有一定的研究基础。离散数据的生成方面很可能需要借助强化学习,这激发我们往多智体强化学习方向进一步探索。”




