独家 | 带你入门比Python更高效的Numpy(附代码)

作者:TIRTHAJYOTI SARKAR
翻译:闫晓雨
校对:Uynix
本文约1790字,建议阅读4分钟。
数据科学家介绍了向量化技巧,简单的数学变化可以通过可迭代对象执行。
简介
向量化技巧对于数据科学家来说是相当熟知的,并且常用于编程中,以加速整体数据转换,其中简单的数学变化通过可迭代对象(例如列表)执行。未受到重视的是,把有一定规模的代码模块,如条件循环,进行矢量化,也能带来一些好处。
正文

Python正在迅速成为数据科学家的编程实战语言。但与R或Julia不同的是,它是通用型编程语言,没有功能语法来立即开始分析和转换数值数据。所以,它需要专门的库。
Numpy是Numerical Python的缩写,是Python生态系统中高性能科学计算和数据分析所需的基础软件包。它是几乎所有高级工具(如Pandas和scikit-learn)的基础。
TensorFlow使用NumPy数组作为基础构建模块,在这些模块的基础上,他们为深度学习任务(在长列表/向量/数字矩阵上大量使用线性代数运算)构建了张量对象(Tensor objects)和图形流(graphflow)许多Numpy操作都是用C语言实现的,避免了Python中循环的基本代价,即指针间接寻址和每个元素的动态类型检查。速度的提升取决于您正在执行的操作。对于数据科学和现代机器学习的任务来说,这是一个非常宝贵的优势。
我最近一篇文章讲了使用Numpy向量化简单数据转换任务的优势,它引起了一些联想,并受到读者的欢迎。关于代码简化等矢量化的效用,也有一些有趣的讨论。
现在,基于某些预定义条件的数学转换在数据科学任务中相当普遍。事实证明,通过首先转换为函数然后使用numpy.vectorize方法,可以轻松地对条件循环的简单模块进行矢量化。在我之前的文章中,我展示了Numpy矢量化简单数学变换后一个数量级的速度提升。对于目前的情况来说,由于内部条件循环仍然效率低下,速度提升并不那么显着。但是,与其他纯粹Python代码相比,执行时间至少要提高20-50%。
以下是演示它的简单代码:
import numpy as np
from math import sin as sn
import matplotlib.pyplot as plt
import time
# 测试数量
N_point = 1000
# 定义一个有if else循环的函数
def myfunc(x,y):
if (x>0.5*y and y<0.3): return (sn(x-y))
elif (x<0.5*y): return 0
elif (x>0.2*y): return (2*sn(x+2*y))
else: return (sn(y+x))
# 从正态分布产生存储元素的列表
lst_x = np.random.randn(N_point)
lst_y = np.random.randn(N_point)
lst_result = []
# 可选择画出数据分布
plt.hist(lst_x,bins=20)
plt.show()
plt.hist(lst_y,bins=20)
plt.show()
# 首先,纯粹的Python代码
t1=time.time()
First, plain vanilla for-loop
t1=time.time()
for i in range(len(lst_x)):
x = lst_x[i]
y= lst_y[i]
if (x>0.5*y and y<0.3):
lst_result.append(sn(x-y))
elif (x<0.5*y):
lst_result.append(0)
elif (x>0.2*y):
lst_result.append(2*sn(x+2*y))
else:
lst_result.append(sn(y+x))
t2=time.time()
print("\nTime taken by the plain vanilla for-loop\n----------------------------------------------\n{} us".format(1000000*(t2-t1)))
# List comprehension
print("\nTime taken by list comprehension and zip\n"+'-'*40)
%timeit lst_result = [myfunc(x,y) for x,y in zip(lst_x,lst_y)]
# Map() 函数
print("\nTime taken by map function\n"+'-'*40)
%timeit list(map(myfunc,lst_x,lst_y))
# Numpy.vectorize 方法
print("\nTime taken by numpy.vectorize method\n"+'-'*40)
vectfunc = np.vectorize(myfunc,otypes=[np.float],cache=False)
%timeit list(vectfunc(lst_x,lst_y))
# 结果
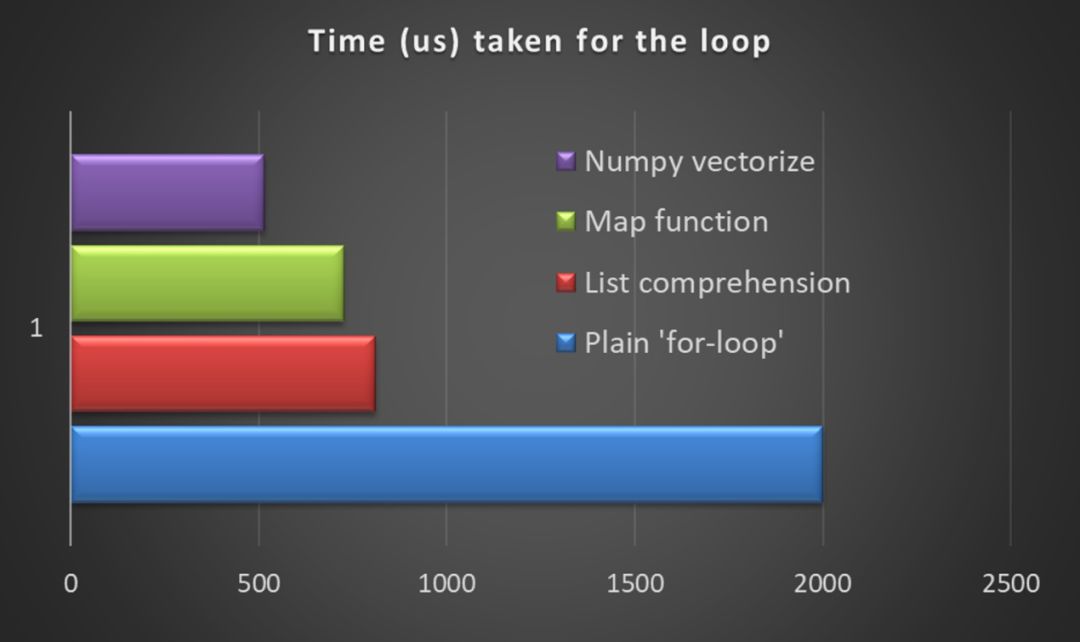
Time taken by the plain vanilla for-loop
----------------------------------------------
2000.0934600830078 us
Time taken by list comprehension and zip
----------------------------------------
1000 loops, best of 3: 810 µs per loop
Time taken by map function
----------------------------------------
1000 loops, best of 3: 726 µs per loop
Time taken by numpy.vectorize method
----------------------------------------
1000 loops, best of 3: 516 µs per
请注意,我已经在任何可以把表达式用一行语句来实现的地方使用了%timeit Jupyter魔术命令。这样我就可以有效运行超过1000个相同表达式的循环,来计算平均执行时间以避免任何随机效应。因此,如果您在Jupyter Notebook中运行整个脚本,则可能会出现与第一种情况(即普通循环执行)略有不同的结果,但接下来的三种应该会给出非常一致的趋势(基于您的计算机硬件)。
我们看到的证据表明,对于基于一系列条件检查的数据转换任务,与一般Python方法相比,使用Numpy的向量化方法通常会使速度提高20-50%。
这貌似不是一个显著改进,但节省的每一点时间都可以加入数据科学工作流程中,从长远来看是值得的!如果数据科学工作要求这种转换发生一百万次,那么可能会导致短则八小时,长则两天的差异。
简而言之,任何时候你有长的数据列表并需要对它们进行数学转换,都应强烈考虑将这些Python数据结构(列表或元组或字典)转换为numpy.ndarray对象并使用自带的向量化功能。
Numpy提供了一个用于更快代码执行的C应用程序接口(C-API),但是它失去了Python编程的简单性。这个Scipy讲义能告诉你在这方面的所有相关选项。
法国神经科学研究人员撰写了关于该主题的完整开源在线书籍。看看这里。
作者的话
如果您有任何问题或想法可以分享,请联系作者tirthajyoti [AT] gmail.com。您也可以在作者的GitHub仓库以获取Python,R或MATLAB的代码片段以及机器学习相关资源。如果你像我一样热衷于机器学习/数据科学/半导体,请随时在LinkedIn上添加我。
作者简介

Tirthajyoti Sarkar ,半导体从业人员,数据科学与机器学习爱好者。使用Python\R\Matlab进行数据科学和机器学习的实践者。半导体专业人员。伊利诺伊大学电子工程博士。在三藩湾区生活与工作。
原文标题:
Data science with Python: Turn your conditional loops to Numpy vectors
原文链接:
https://www.codementor.io/tirthajyotisarkar/data-science-with-python-turn-your-conditional-loops-to-numpy-vectors-he1yo9265
译者简介

闫晓雨,本科毕业于北京林业大学,即将就读于南加州大学应用生物统计与流行病硕士项目。继续在生统道路上摸爬滚打,热爱数据,期待未来。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织



