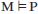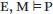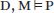![]()
本文约8813字,建议阅读12分钟
本文介绍了如何兑现人工智能带来好处的承诺以及如何实现可信AI?
对于某些任务,人工智能系统已经取得足够好的表现,可以部署在我们的道路和家里。比如,物体识别可以帮助汽车识别道路;语音识别则有助于个性化语音助手(如Siri和Alexa)交流。对于其他任务,人工智能系统的表现甚至超过了人类,AlphaGo 就是第一个击败世界最强围棋选手的计算机程序。
人工智能的前景广阔。它们将开我们的车,它们将帮助医生更准确地诊断疾病,它们将帮助法官做出更加一致的法庭裁决,它们将帮助雇主聘用更合适的求职者。
然而,我们也知道这些
人工智能系统可能是不堪一击且不公正的
。在停车标志上涂鸦可以骗过分类器使其认为这不是停车标志。向良性皮肤病变的图像中加入噪音也会欺骗分类器,使其误以为是恶性的。美国法院使用的风险评估工具已被证明对黑人持有偏见,企业的招聘工具也被证明歧视女性。
那么,我们如何才能兑现人工智能带来好处的承诺,同时解决这些对人类和社会来说生死攸关的情况呢?简而言之,我们
怎样才能实现可信AI
?
本文的最终目的是
团结计算机社区,通过来自多个研究社区和利益相关者的专业知识和情感,来支持一个关于可信AI的广泛且长期的研究项目
。本文侧重于解决三个关键研究社区的问题,原因如下:可信AI在可信计算的基础上增加了新的所需属性;人工智能系统需要新的形式和技术,尤其是数据的使用提出了全新的研究问题;人工智能系统可能会受益于对确保可信度的正式方法的审查。通过将可信计算、形式方法和人工智能领域的研究人员聚集在一起,我们的目标是在可信AI领域内培育一个跨学术界、产业界和政府的新型研究社区。
周以真
(英文名Jeannette M. Wing),美国计算机科学家,曾任卡内基-梅隆大学教授。美国国家自然基金会计算与信息科学工程部助理部长。ACM和IEEE会士。她的主要研究领域是形式方法、可信计算、分布式系统、编程语言等。现为哥伦比亚大学数据科学研究院主任、计算机科学教授,其长期研究兴趣主要集中于网络安全、数据隐私以及人工智能。
具有里程碑意义的1999年国家科学院网络空间信任(Trust in Cyberspace 1999 National Academies)报告奠定了可信计算的基础,此后,可信计算持续成为一个活跃的研究领域。
大约在同一时期,
美国国家科学基金会
(National Science Foundation)启动了一系列关于信任的项目。从始于2001年的可信计算(Trusted Computing)为起点,到2004年的网络信任(Cyber Trust),再到2007年的可信赖计算(Trustworthy Computing),以及2011年的安全可信的网络空间(Secure and Trustworthy Cyberspace),
计算机和信息科学与工程理事会
(Computer and Information Science and Engineering Directorate)已经发展成可信计算的学术研究社区。虽然它源于计算机科学社区,但现在支持可信计算的研究已跨越了美国国家科学基金会的多个部门,并涉及许多其他资助组织,包括通过网络和信息技术研究与发展(NITRD)计划和20个联邦机构。
产业界也一直是可信计算的领导者和积极参与者。在比尔·盖茨2002年1月的“可信计算(Trustworthy Computing)”备忘录中,微软向它的员工、客户、股东和其他信息技术部门传达了可信软件和硬件产品的重要性。它提到了微软内部的一份白皮书,该白皮书确定了信任的四个支柱:
安全、隐私、可靠和商业诚信。
经过 20 年的投资和研发进步,“可信”已经意味着一组(重叠的)属性:
我们希望这些属性存在于硬件和软件等计算系统中,以及存在于这些系统与人类和物理世界的交互。在过去的几十年里,学术界和产业界在可信计算方面取得了巨大的进步。然而,随着技术的进步和对手变得越来越复杂,可信计算仍然是一个艰难的梦想。
人工智能系统在利益属性方面提高了标准
。除了与可信计算相关的属性(如前所述),我们还需要(重叠的)属性,例如:
-
准确性:与训练和测试过的数据相比,人工智能系统在新的(不可见的)数据上表现如何?
-
-
-
-
透明度:外部观察员是否清楚系统的结果是如何产生的?
-
可理解性/可解释性:系统的结果是否可以通过人类可以理解和/或对最终用户有意义的解释来证明?
机器学习社区将准确性视为黄金标准,但可信AI要求我们在这些属性之间进行权衡。比如,我们也许愿意为了部署一个更公平的模型而舍弃一些准确性。此外,上述的某些属性可能有不同的解释,最终导致不同的形式。例如,有许多合理的公平概念,包括人口平等、机会均等和个人公平等等,这其中的一些概念彼此并不相容。
传统的软件和硬件系统由于其规模和组件之间的交互数量而变得复杂。在大多数情况下,我们可以根据离散逻辑和确定性状态机来定义它们的行为。
今天的人工智能系统,尤其是那些使用深度神经网络的系统,给传统的计算机系统增加了一个复杂的维度。这种复杂性是由于它们固有的概率性质。通过概率,人工智能系统对人类行为和物理世界的不确定性进行建模。更多机器学习的最新进展依赖于大数据,这增加了它们的概率性质,因为来自现实世界的数据只是概率空间中的点。因此,
可信AI必然会将我们的注意力从传统计算系统的主要确定性本质转向人工智能系统的概率本质。
我们如何设计、执行和部署人工智能系统,使其值得信赖?
在计算系统中建立最终用户信任的一种方法是
形式验证
,其中属性在一个大域中得到一劳永逸的证明,例如,对一个程序的所有输入或者对于并发或分布式系统的所有行为。或者,验证过程识别出的反例,例如,一个输入值,其中程序产生错误的输出或行为未能满足所需属性,从而提供关于如何改进系统的有价值的反馈。
形式验证的优点是无需逐一测试单个输入值或行为
,这对于大型(或无限)状态空间是不可能完全实现的。例如,在验证缓存一致性协议和检测设备驱动程序错误等形式方法的早期成功案例,导致了它们今天的可扩展性和实用性。这些方法现用于硬件和软件行业,例如,英特尔、IBM、微软和亚马逊。由于形式方法语言、算法和工具的进步以及硬件和软件的规模和复杂性的增加,在过去的几年里,我们已经看到了人们对形式验证产生的新一轮兴趣和兴奋,特别是在确保系统基础设施关键组件的正确性方面。
形式验证是一种提供可证保证的方式,从而增加人们对系统将按预期运行的信任。
从传统的形式方法到人工智能的形式方法。在传统的形式方法中,我们想要证明一个模型M满足()一个属性P。
M是要验证的对象,它可以是一个程序,也可以是一个复杂系统的抽象模型,例如,并发的、分布式的或反应性的系统。P是用某种离散逻辑表示的正确性属性。例如,M可能是使用锁进行同步的并发程序,而P可能是“无死锁”的。M 是无死锁的证明意味着
M 的任何用户都确信 M 永远不会达到死锁状态
。为了证明M满足P,我们使用了形式化的数学逻辑,这是当今可扩展和实用的验证工具的基础,如模型检验器、定理证明器和可满足模理论(SMT)求解器。
特别是当M是一个并发的、分布式或反应式的系统时,在传统的形式方法中,我们经常在验证任务的制定中明确添加系统环境 E 的规范:
例如,如果M是一个并行进程,那么E可能是另一个与M交互的进程(然后我们可以写成E || mp,其中||代表并行组合)。或者,如果M是设备驱动程序代码,则E可能是操作系统的模型。又或者,如果M是一个控制系统,E则可能是关闭控制回路的环境模型。编写E的规范是为了明确关于系统验证环境的假设。
对于验证人工智能系统,M可以解释为一个复杂的系统,例如自动驾驶汽车,其中包含一个机器学习模型的组件,比如计算机视觉系统。在这里,我们想要证明P,打个比方,在E(交通、道路、行人、建筑物等)的背景下,相对于M(汽车)的安全性或稳健性。我们可以把证明P看作是证明一个“系统级”属性。
Seshia等人用这个观点阐述了形式规范的挑战,其中深度神经网络可能是系统M的黑盒组件。
但是,对于机器学习模型我们能断言什么呢?比如,DNN是这个系统的关键组成部分?我们是否可以验证机器学习模型本身的稳健性或公平性?是否有白盒验证技术可以利用机器学习模型的结构?回答这些问题会带来新的验证挑战。
验证:机器学习模型M
。为了验证ML模型,我们重新解释了M和P,其中M代表机器学习模型。P代表可信的属性,例如安全性、稳健性、隐私性或公平性。
与传统的形式方法相比,验证人工智能系统提出更多的要求。这里有两个关键的区别:
机器学习模型固有的概率性质和数据的作用
。
M和P的固有的概率性质,因此需要概率推理()。ML模型M本身在语义和结构上都不同于典型的计算机程序。如前所述,它具有内在的概率性,从现实世界中获取输入,这些输入可能被数学建模为随机过程,并产生与概率相关的输出。在内部,模型本身是基于概率的;例如,在深度神经网络中,边缘上的标签是概率,节点根据这些概率计算函数。从结构上讲,因为机器生成了 ML 模型,所以 M 本身不一定是人类可读或可理解的;粗略地说,DNN是由if-then-else语句组成的复杂结构,人类不太可能编写这种语句。这种“中间代码”表示在程序分析中开辟了新的研究方向。
属性P本身可以在连续域而非(仅)离散域上表述,和/或使用来自概率和统计的表达式。深度神经网络的稳健性被描述为对连续变量的预测,而公平性的特征是关于相对于实数的损失函数的期望(具体参见Dwork等人的研究)。差分隐私是根据相对于(小)真实值的概率差异来定义的。请注意,就像可信计算的实用性等属性一样,可信 AI 系统的一些所需属性,例如透明度或道德感,尚未形式化或可能无法形式化。对于这些属性,一个考虑法律、政策、行为和社会规则和规范的框架可以提供一个环境,在这个环境中可以回答一个可形式化的问题。简而言之,人工智能系统的验证将仅限于可以形式化的内容。
形式验证是一种提供可证保证的方式,从而增加人们对系统将按预期运行的信任。
这些固有的概率模型M和相关的所需信任属性P需要可扩展的和/或新的验证技术,这些技术适用于实数、非线性函数、概率分布、随机过程等等。验证人工智能系统的一个垫脚石是信息物理系统社区使用的概率逻辑和混合逻辑(参见Alur等人,Kwiatkowska等人和Platzer)。另一种方法是将时间逻辑规范直接集成到强化学习算法中。更具挑战性的是,这些验证技术需要对机器生成的代码进行操作,尤其是本身可能无法确定生成的代码。
数据的作用。也许,传统形式验证和人工智能系统验证之间更重要的区别在于数据的作用,用于训练、测试和部署ML模型的数据。今天的ML模型是根据数据集D构建和使用的。为了验证ML模型,我们提出对该数据的明确假设,并将验证问题表述为:
数据分为可用数据和不可见数据,其中可用数据为手头数据,用于培训和测试M;而不可见数据是M需要(或期望)在之前没有见过的情况下对其进行操作的数据。构建M背后的整个想法是,基于训练和测试的数据,M能够对从未见过的数据做出预测,且这个预测通常在一定程度上是准确的。
明确数据的作用提出了新的规范和验证挑战,可大致分为以下几类,以及其相关的研究问题:
对于给定的属性P,需要多少数据才能建立一个模型M?深度学习的成功案例告诉我们,在准确性方面,数据越多,模型就越好,但其他属性呢?添加更多的数据来训练或测试M是否会使它更稳健、更公平?或者它对属性P没有影响?如果所需的属性不成立,需要收集哪些新数据?
我们如何将可用(给定)数据集划分为训练集和测试集?在构建模型 M 时,我们可以根据所需的属性 P 对这种划分做出什么保证?如果我们同时针对多个属性训练模型,我们是否会以不同的方式拆分数据?如果我们愿意用一种属性交换另一种属性,我们会以不同的方式来拆分数据吗?
指定不可见数据:在形式化方法框架D中包含D,M P使我们有机会明确地陈述关于不可见数据的假设。
我们如何指定数据和/或描述数据的属性?例如,我们可以将D指定为一个随机过程,它产生需要验证ML模型的输入。或者我们可以把D定义为数据分布。对于常见的统计模型,例如正态分布,我们可以根据其参数(例如均值和方差)指定 D。概率编程语言,例如 Stan,可能是指定统计模型的起点。但是,如果真实世界的大型数据集不符合常见的统计模型,或者有成千上万的参数,又该怎么办呢?
根据定义,在指定不可见的数据时,我们需要对不可见数据做出某些假设。这些假设会不会和我们一开始建立模型M时所做的假设一样呢?更重要的是:我们如何信任D的规范?这种看似逻辑的僵局类似于传统验证中的问题,给定一个M,我们需要假设元素的规范E和MP中元素E和P的规范是“正确的”。那么在验证过程中,我们可能需要修改E和/或P(甚至M)。为了打破现有的循环推理,一种方法是使用不同的验证方法来检查 D 的规范;这种方法可以借鉴一系列统计工具。另一种方法是假设初始规范足够小或足够简单,可以通过(例如,手动)检查进行检查;然后我们使用这个规范引导一个迭代的细化过程。(我们从形式方法的反例引导抽象和细化方法中获得灵感。)这种细化过程可能需要修改D、M和/或P。
不可见数据的规范与M接受训练和测试的数据规范有何关联?
形式方法社区最近一直在探索人工智能系统的稳健性,特别是用于自动驾驶汽车的图像处理系统。
在传统的验证中,我们的目标是证明属性P,一个普遍量化的语句:例如,对于整型变量x的所有输入值,程序将返回一个正整数;或者对于所有执行序列x,系统不会死锁。
因此,证明ML模型M中的P的第一个问题是:在P中,我们量化了什么?对于要在现实世界中部署的ML模型,一个合理的答案是对数据分布进行量化。但是ML模型仅适用于由现实世界现象形成的特定分布,而不适用于任意分布。我们不想为所有的数据分布证明一个属性。对于我们在证明M的信任属性时所量化的内容和数据所代表的内容之间的差异,这种见解导致了这个新的规范问题:
对于给定的 M,我们如何指定 P 应该保持的分布类别?以稳健性和公平性作为两个例子:
对于鲁棒性
,在对抗性机器学习设置中,我们可能想证明M对所有范数有界的扰动D是稳健的。更有趣的是,我们可能想证明M对于手头任务的所有“语义”或“结构”扰动都是稳健的。例如,对于一些视觉任务,我们想要考虑旋转或使图像变暗,而不是仅仅改变任何旧像素。
对于公平性
,我们可能想证明ML模型在给定数据集和所有“相似”(对于“相似”的正式概念)的所有不可见数据集上是公平的。训练一种招聘工具,以决定在一个群体的申请者中面试谁,在未来的任何人群中都应该是公平的。我们如何指定这些相关的分布?
为了构建一个既稳健又公平的分类器,Mandal等人展示了如何调整在线学习算法,以找到对一类输入分布公平的分类器。
验证任务
:一旦我们有了D和P的规范,给定一个M,我们就需要验证M满足P,给定我们对D中可用和不可见数据的任何假设,使用我们手头上的任何逻辑框架。
我们如何检查可用的数据以获得所需的属性?比如说,如果我们想要检测一个数据集是否公平,我们应该检查数据集的哪些方面?
如果我们发现属性不存在,我们如何修复模型、修改属性,或者决定收集哪些新数据来重新训练模型?在传统的验证中,生成一个反例,例如,一个不满足P的执行路径,有助于工程师调试他们的系统和/或设计。在ML模型的验证中,“反例”的等效物是什么?我们如何使用它?
我们如何利用不可见数据的显式规范来帮助验证任务?就像在验证任务E, M P中明确环境规范E一样,我们如何利用明确的D规范?
我们如何扩展标准验证技术来操作数据分布,也许可以利用我们形式上指定不可见数据的方式?
这两个关键的区别——M的固有概率性质和数据D的作用——为形式方法社区提供了研究机会,以推进人工智能系统的规范和验证技术。
相关工作
。形式方法社区最近一直在探索人工智能系统的稳健性,特别是用于自动驾驶汽车的图像处理系统。最先进的VerifAI系统探索了自动驾驶汽车稳健性的验证,依靠模拟来识别执行轨迹,其中网络物理系统(例如,自动驾驶汽车)的控制依赖于嵌入式 ML 模型可能出错。ReluVal和Neurify等工具研究了DNN的稳健性,特别是应用于自动驾驶汽车的安全性,包括自动驾驶汽车和飞机防撞系统。这些工具依靠区间分析来减少状态探索,同时仍然提供强有力的保证。在F1/10赛车平台上,使用Verisig验证基于DNN的控制器的安全性的案例研究为比较不同的DNN配置和输入数据的大小提供了基准,并识别了模拟和验证之间的当前差距。
FairSquare2使用概率验证来验证ML模型的公平性。LightDP60将概率性程序转换为非概率性程序,然后进行类型推断以自动验证不同隐私的隐私预算。
这些工具都体现了可信AI的精神,但每一个工具都只关注一个属性。将他们的底层验证技术扩展到工业规模的系统仍然是一个挑战。
额外的形式方法机会
。今天的人工智能系统是为了执行特定任务而开发的,例如识别人脸或下围棋。我们如何考虑已部署的ML模型在规范和验证问题中要执行的任务?例如,考虑显示进行图像分析的ML模型M的稳健性:对于识别道路上的汽车的任务,我们希望M对任何一侧有凹痕的汽车图像都是稳健的;但对于汽车生产线的质量控制任务,我们就不会这么做。
之前,我们主要关注形式方法中的验证任务。
但形式方法的机制最近也成功地用于程序合成
。与其对模型 M 进行事后验证,我们能否首先开发一种“构建正确”的方法来构建 M?例如,我们是否可以在训练和测试M时添加所需的可信属性P作为约束,以保证P在部署时成立(可能适用于给定的数据集或一类分布)?这种方法的一种变体是通过在每个步骤检查算法不会不满足不希望行为来指导 ML 算法设计过程。类似地,安全强化学习解决决策过程中的学习策略,其中安全性作为优化的一个因素或探索的外部约束。
本文开头列举的有关可信AI的一系列属性并不实用,但每个属性对于建立信任都至关重要。摆在研究界面前的一项任务是制定出这些属性的共性,然后可以在一个共同的逻辑框架中指定这些共性,类似于使用时间逻辑来指定安全性(“没有坏事发生”)和活跃性(“最终有好事发生”)用来推理并发和分布式系统的正确性属性。
组合推理使我们能够对大型复杂系统进行验证。如何验证AI系统的属性“提升”组件以显示该属性适用于系统?相反地,我们该如何将AI系统分解成多个部分,根据给定属性验证每个部分,并断言这个属性对于整体成立?哪些属性是全局的(避免组合),哪些是局部的?数十年来,对组合规范和验证的形式化方法的研究为我们提供了一个很好的起点,即
词汇和框架
。
统计学在模型检查和模型评估方面有着丰富的历史,使用的工具包括敏感性分析、预测评分、预测检查、残差分析和模型批评等。为了验证ML模型满足所需属性,这些统计方法可以补充形式验证方法,就像测试和模拟补充计算系统的验证一样。更相关的是,正如前面提到的“数据的作用”中所述,它们可以帮助评估用于指定D,M P问题中不可见数据D的任何统计模型。形式方法社区的一个机会是将这些统计技术与传统的验证技术相结合(有关这种组合的早期工作,请参考 Younes 等人的研究)。
正如可信计算一样,形式方法只是确保增加人工智能系统信任的一种方法。社区需要探索多种方法,尤其是组合方法,以实现可信AI。其他方法包括测试、模拟、运行时监视、威胁建模、漏洞分析,以及对代码和数据进行等效的设计和代码审查。此外,除了技术挑战,还有社会、政策、法律和伦理方面的挑战。
2019年10月30日至11月1日,
哥伦比亚大学数据科学研究所
主办了由 DSI 行业附属机构 Capital One 赞助的关于可信AI的首届研讨会。它汇集了来自形式方法、安全和隐私、公平和机器学习的研究人员。来自业界的发言者对学术界正在追求的各种问题和方法进行了现实检验。与会者确定了研究面临的挑战领域,包括:
-
-
-
-
审核考虑可解释性、透明度和责任等属性的人工智能系统的流程;
-
检测偏差和去偏差数据的方法、机器学习算法及其输出;
-
-
-
理解社会因素,包括社会福利、社会规范、道德、伦理和法律。
许多推动机器学习和人工智能前沿的科技公司并没有坐以待毙。他们意识到可信AI对他们的客户、业务和社会福利的重要性,主要关注的是公平性。IBM的AI Fairness 360提供了一个开源工具包,用于检查数据集和机器学习模型中不必要的偏见。谷歌的TensorFlow工具包提供了“公平性指标”,用于评估二元和多类分类器的公平性。微软的 Fairlearn 是一个开源包,供机器学习开发人员评估其系统的公平性并减轻观察到的不公平。在2018年的F8大会上,Facebook宣布了其Fairness Flow 工具,旨在“
衡量对特定群体的潜在偏见
”。本着行业和政府合作的精神,亚马逊和美国国家科学基金会自 2019 年开始合作资助“人工智能公平”计划。
2016年,
美国国防部高级研究计划局
(DARPA)通过启动可解释人工智能 (XAI) 计划,专注于可解释性。该计划的目标是开发新的机器学习系统,可以“
解释其基本原理、描述其优势和劣势,并传达其对未来表现的理解
。”有了可解释性,终端用户就会更加相信并采纳系统的结果。
通过安全可信的网络空间计划(Secure and Trustworthy Cyberspace Program),国家科学基金会资助了一个由宾夕法尼亚州立大学领导的可信赖机器学习中心,来自斯坦福大学、加州大学伯克利分校、加州大学圣地亚哥分校、弗吉尼亚大学和威斯康星大学的研究人员也参与其中。他们的主要重点是解决对抗性机器学习,补充之前概述的形式方法。(为了充分披露,本文作者是该中心顾问委员会成员。)2019年10月,美国国家科学基金会宣布了一项资助国家人工智能研究所的新计划。它命名的六个主题之一是“可信AI”,强调可靠性、可解释性、隐私性和公平性等属性。
NITRD关于人工智能和网络安全的报告明确呼吁对人工智能系统的规范和验证以及可信的人工智能决策进行研究。最后,在2020年12月,白宫签署了一项关于可信AI的行政命令,为美国联邦机构在其服务中采用人工智能提供指导,并促进公众对人工智能的信任。
正如可信计算一样,政府、学术界和产业界正在共同推动可信AI的新研究议程。我们正加大对这一圣杯的赌注!
https://cacm.acm.org/magazines/2021/10/255716-trustworthy-ai/fulltext