随着物联网、大数据应用和智能计算应用的发展,当前计算机的处理、通信和存储能力已经无法匹配海量数据和信息处理复杂性的快速增长,针对应用需求的硬件加速得到蓬勃发展。另一方面,随着器件特征尺寸缩小到其物理极限,电路性能对参数偏差和噪声更加敏感,计算机的能效提升遇到瓶颈,这些问题促进了异构、三维集成、非易失性存储器等新型结构、工艺和器件的大量探索。计算机体系结构技术研究面临许多新的机遇和挑战。面向上述背景,本刊拟开辟“计算机体系结构前沿技术”系列专题,并于今年出版“计算机体系结构前沿技术(一)”专辑。本专辑出版8篇文章,集中讨论面向不同应用背景的智能和近似计算的计算机体系结构技术,以及基于新型工艺和器件的存储器和处理器技术。
特约编辑:
刘志勇 研究员(中科院计算所)
窦 勇 教授(国防科学技术大学)
李华伟 研究员(中科院计算所)
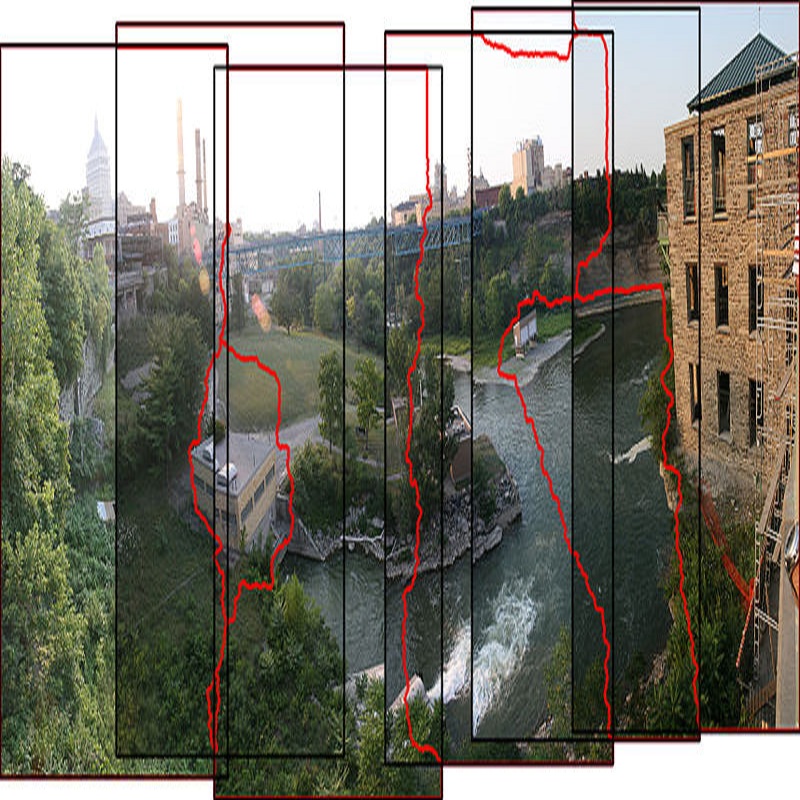
1——GPU加速与L-ORB特征提取的全景视频实时拼接
全景视频是在同一视点拍摄记录全方位场景的视频.随着虚拟现实(VR)技术和视频直播技术的发展,全景视频的采集设备受到广泛关注.然而制作全景视频要求CPU和GPU都具有很强的处理能力,传统的全景产品往往依赖于庞大的设备和后期处理,导致高功耗、低稳定性、没有实时性且不利于信息安全.为了解决这些问题,首先提出了L-ORB特征点提取算法,该算法优化了分割视频图像的特征检测区域以及简化ORB算法对尺度和旋转不变性的支持;然后利用局部敏感Hash(Multi-Probe LSH)算法对特征点进行匹配,用改进的样本一致性(progressive sample consensus, PROSAC)算法消除误匹配,得到帧图像拼接映射关系,并采用多频带融合算法消除视频间的接缝.此外,使用整合了ARM A57 CPU和Maxwell GPU的Nvidia Jetson TX1异构嵌入式系统,利用其Teraflops的浮点计算能力和内建的视频采集、存储、无线传输模块,实现了多摄像头视频信息的实时全景拼接系统,有效地利用GPU指令的块、线程、流并行策略对图像拼接算法进行加速.实验结果表明,算法在图像拼接的特征提取、特征匹配等各个阶段均有很好的性能提升,其算法速度是传统ORB算法的11倍、传统SIFT算法的639倍;系统较传统的嵌入式系统性能提升了29倍,但其功耗低至10W.
2——一种基于裸闪存的Key-Value数据库优化方法
近年来,非关系型的key-value数据库得到越来越广泛的应用.然而,目前主流的key-value数据库或者是基于磁盘设计的,或者是传统的基于文件系统和闪存转换层FTL来构建的,难以发挥闪存存储设备的特性,限制了I/O的并发性能,且垃圾回收过程复杂.设计并实现了一种基于裸闪存的key-value数据管理架构Flashkv,通过用户态下的管理单元进行空间管理和垃圾回收,充分利用了闪存设备内部的并发特性,并简化了垃圾回收过程,去除了传统文件系统和FTL中的冗余功能,缩短了I/O路径.提出了基于闪存特点的I/O调度技术,优化了闪存的读写延迟,提高了吞吐率;提出了用户态缓存管理技术,降低了数据写入量和频繁系统调用所带来的开销.测试结果表明,Flashkv性能是levelDB的1.9~2.2倍,写入量减少60%~65%.
近年来,以神经网络为代表的机器学习算法发展迅速并被广泛应用在图像识别、数据搜索乃至金融趋势分析等领域.而随着问题规模的扩大和数据维度的增长,算法能耗问题日益突出,由于机器学习算法自身拥有的近似特性,近似计算这种牺牲结果的少量精确度降低能耗的技术,被许多研究者用来解决学习算法的能耗问题.我们发现,目前的工作大多专注于利用特定算法的近似特性而忽视了不同算法近似特性的差别对能耗优化带来的影响,而为了分类任务使用近似计算时能够做出能耗最优的选择,了解算法“可近似性”上的差异对近似计算优化能耗至关重要.因此,选取了支持向量机(SVM)、随机森林(RF)和神经网络(NN) 3类常用的监督型机器学习算法,评估了针对不同类型能耗时不同算法的可近似性,并建立了存储污染敏感度、访存污染敏感度和能耗差异度等指标来表征算法可近似性的差距,评估得到的结论将有助于机器学习算法在使用近似计算技术时达到最优化能耗的目的.
深度卷积神经网络在多个领域展现了不凡的性能,并被广泛应用.随着网络深度的增加和网络结构不断复杂化,计算资源和存储资源的需求也在不断攀升.专用硬件可以很好地解决对计算和存储的双重需求,在低功耗同时满足较高的计算性能,从而应用在一些无法使用通用CPU和GPU的场景中.在专用硬件设计过程中仍存在着很多亟待解决的问题,例如选择何种数据表示方法、如何平衡数据表示精度与硬件实现代价等.为解决上述问题,针对定点数和浮点数建立误差分析模型,从理论角度分析如何选择表示精度及选择结果对网络准确率的影响,并通过实验探究不同数据表示方法对硬件实现代价的影响.通过理论分析和实验验证可知,在一般情况下,满足同等精度要求时浮点表示方法在硬件实现开销上占有一定优势.除此之外,还根据浮点表示特征对神经网络中卷积操作进行了硬件实现,与定点数相比在功耗和面积上分别降低92.9%和77.2%.
5——采用流水化伪随机编码算法的相变存储器寿命延长方法
相变存储器(phase change memory, PCM)是一种颇具前景的新型存储器件,具有非易失性、静态功耗低和存储密度高的优点.然而,该类器件的低写入寿命是其在实用化中亟待克服的关键问题之一.一般来说,通过每次写入时仅写入相异位的策略,可以减少产生的平均写入量,从而延长PCM的写入寿命.然而,应用这一差异式的写入策略通常又会以降低读写速度为代价.为此,提出了一种兼具高效和快速特点的写入量减少方法FEBRE(a fast and efficient bit-flipping reduction technique to extend PCM lifetime).该方法在差分写入阶段前,设计并使用了一种快速的一对多映射,将待写入的数据并行映射为多个编码向量,从而增加了从其中找到一个与已有数据最近的向量的可能性.此外,还提出了一种流水化的伪随机编码算法,用以加速一对多映射中的编码过程,从而降低写入开销.实验表明,与目前领先的PRES(pseudo-random encoding scheme)方法相比,FEBRE方法在写入操作中,平均减少了5%以上的写入量,提升了2倍以上的编码速度;在读取操作中,减少了45%以上的解码操作次数.
6——基于忆阻器的PIM结构实现深度卷积神经网络近似计算
忆阻器(memristor)能够将存储和计算的特性融合,可用于构建存储计算一体化的PIM(processing-in-memory)结构.但是,由于计算阵列以及结构映射方法的限制,基于忆阻器阵列的深度神经网络计算需要频繁的AD/DA转换以及大量的中间存储,导致了显著的能量和面积开销.提出了一种新型的基于忆阻器的深度卷积神经网络近似计算PIM结构,利用模拟忆阻器大大增加数据密度,并将卷积过程分解到不同形式的忆阻器阵列中分别计算,增加了数据并行性,减少了数据转换次数并消除了中间存储,从而实现了加速和节能.针对该结构中可能存在的精度损失,给出了相应的优化策略.对不同规模和深度的神经网络计算进行仿真实验评估,结果表明,在相同计算精度下,该结构可以最多降低90%以上的能耗,同时计算性能提升约90%.
基于固态硬盘(solid-state drive, SSD)和硬盘(hard disk drive, HDD)混合存储的数据中心已经成为大数据计算领域的高性能载体,数据中心负载应该可将不同特性的数据按需持久化到SSD或HDD,以提升系统整体性能.Spark是目前产业界广泛使用的高效大数据计算框架,尤其适用于多次迭代计算的应用领域,其原因在于Spark可以将中间数据持久化在内存或硬盘中,且持久化数据到硬盘打破了内存容量不足对数据集规模的限制.然而,当前的Spark实现并未专门提供显式的面向SSD的持久化接口,尽管可根据配置信息将数据按比例分布到不同的存储介质中,但是用户无法根据数据特征按需指定RDD的持久化存储介质,针对性和灵活性不足.这不仅成为进一步提升Spark性能的瓶颈,而且严重影响了混合存储系统性能的发挥.有鉴于此,首次提出面向SSD的数据持久化策略.探索了Spark数据持久化原理,基于混合存储系统优化了Spark的持久化架构,最终通过提供特定的持久化API实现用户可显式、灵活指定RDD的持久化介质.基于SparkBench的实验结果表明,经本方案优化后的Spark与原生版本相比,其性能平均提升14.02%.
8——三值光学处理器的MSD数据正/负值判断器设计与实现
数值正/负或零判断器是计算机比较数据大小的必备器件,随着三值光学处理器中采用三态光信号表示信息的MSD(modified signed-digit)数并行加法器的出现,研究三态光信号所表达数值的正/负或零值判断器成为完善三值光学处理器的重要一环.根据MSD数的特点,通过对三态光信号的变化规律与MSD数据的对应关系的研究,提出了从一组三态光信号来判断其表达的多位MSD数据正/负特性或零值的方法.将这一方法用于2个不定长MSD数据的差运算结果,实现了判别2个MSD数据的大小或相等.依据上述理论,建立了以偏振片、液晶和半反半透镜为主要器件构造的MSD数据判断器结构,加以FPGA作为控制电路,实现了光电混合模式的3位MSD数据判断器.通过实验证明了该判断器的有效性,进而证明了其基本理论的正确性和结构设计的可行性.
本专题刊登在《计算机研究与发展》2017年第6期,敬请关注,点击文末“阅读全文”可免费下载。