论坛回顾 | 业界大咖云集,强化学习与运筹优化前沿技术论坛报告总结与答疑

论坛简介
名 称
强化学习与运筹优化前沿技术论坛
时 间
2021 年 3 月 27 日
主 办 单 位
中国科学院自动化研究所
论 坛 主 席
徐波,中科院自动化所所长、研究员
论 坛 主 持
汪军,英国伦敦大学学院教授、华为诺亚方舟决策推理实验室顾问科学家
张海峰,中科院自动化所副研究员
报 告 嘉 宾
印卧涛,阿里巴巴(美国)达摩院决策智能实验室负责人
郝建业,华为诺亚方舟决策推理实验室主任
秦志伟,滴滴 AI Labs 首席研究员
叶德珩,腾讯绝悟 AI 技术负责人
王湘君,启元世界首席算法官
郭祥昊,字节跳动游戏 AI 团队负责人
报 告
总 结
1 整数规划在决策智能中的新应用
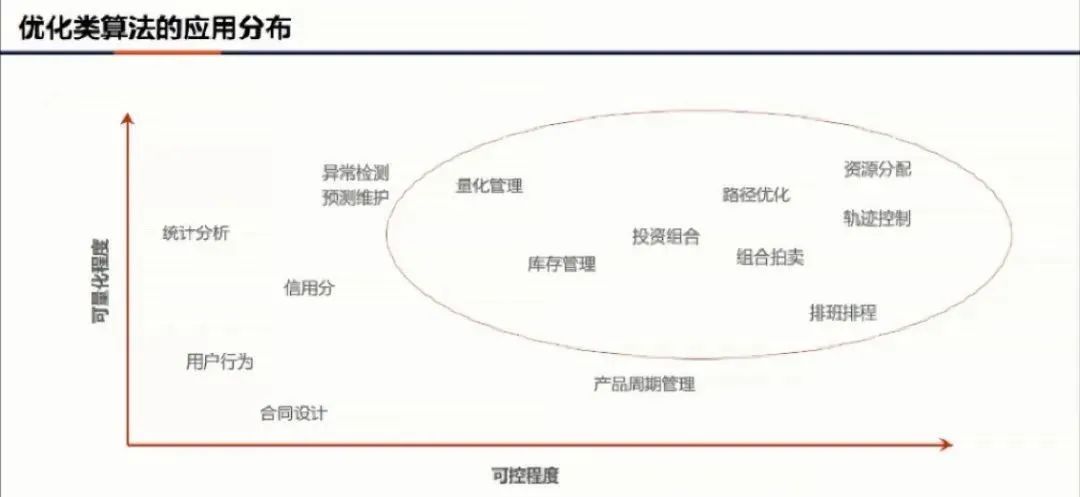

2 深度强化学习的挑战及落地

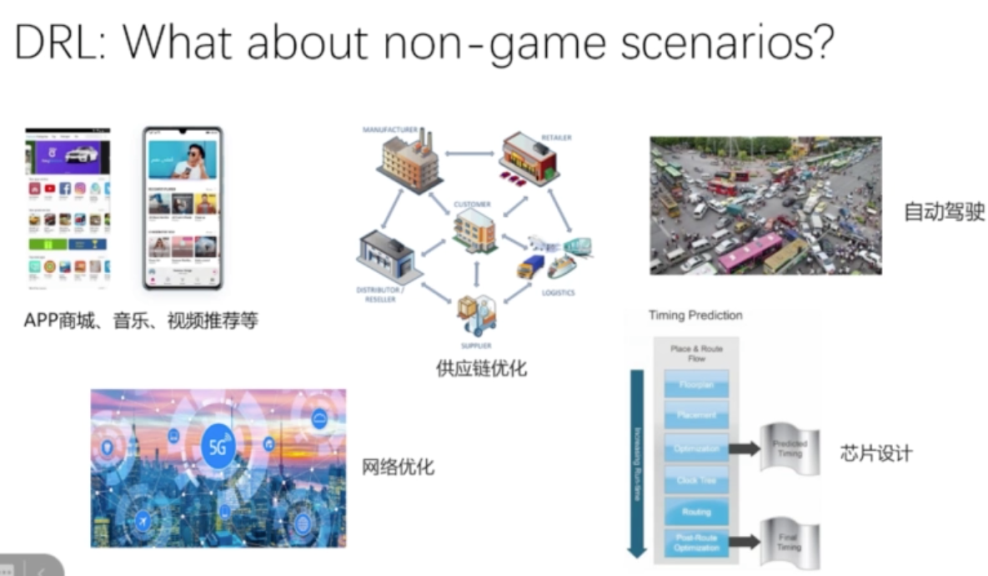
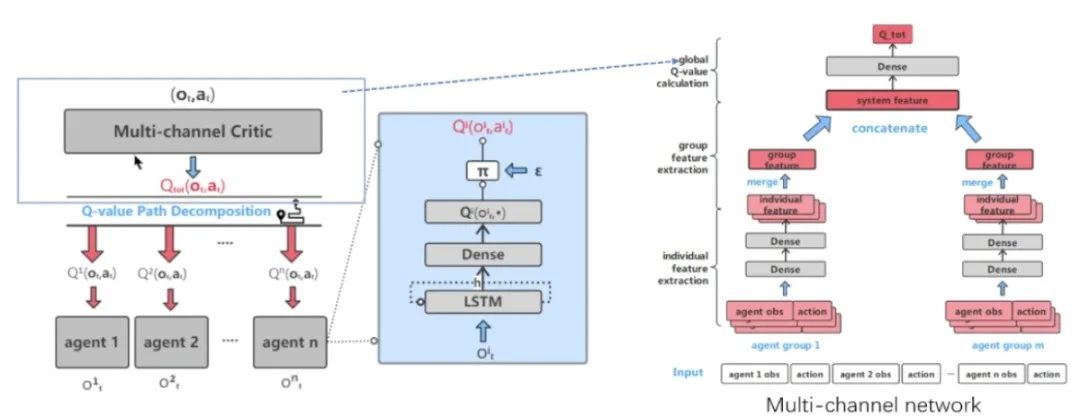
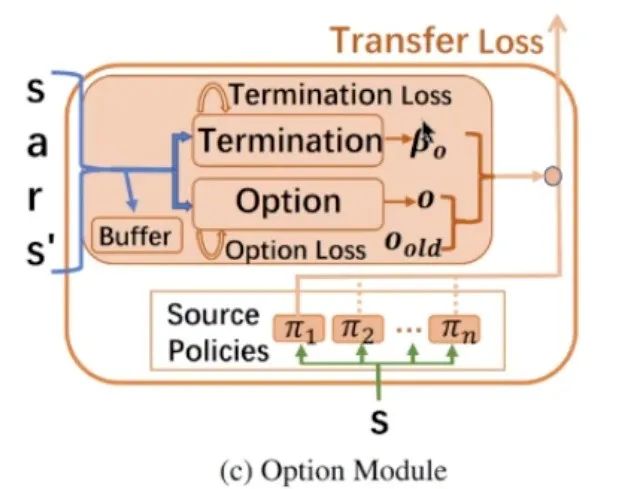
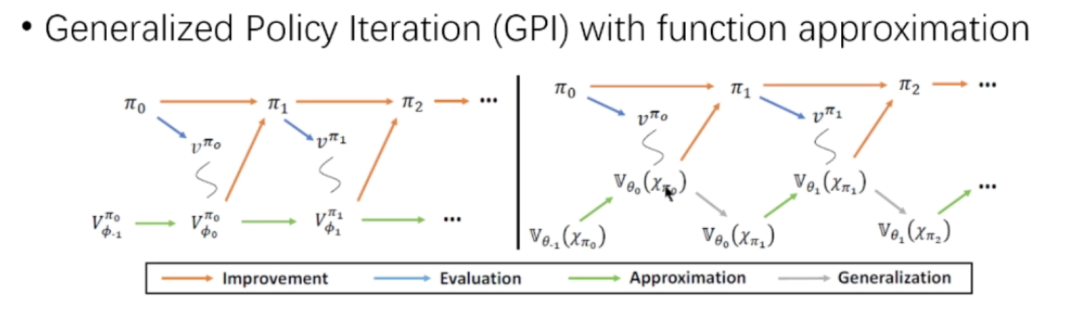
3. 强化学习的应用场景
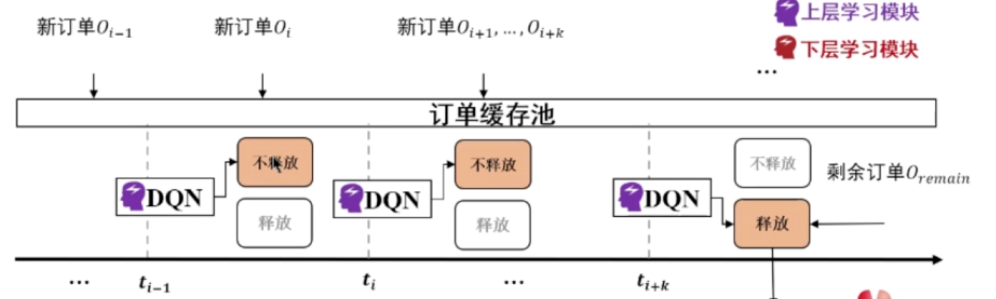
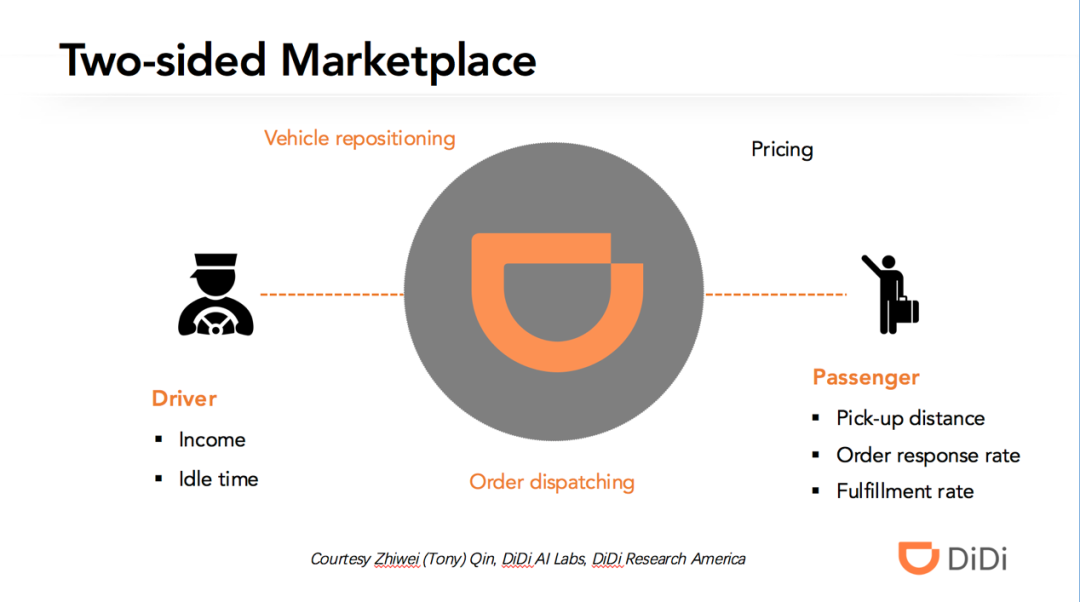
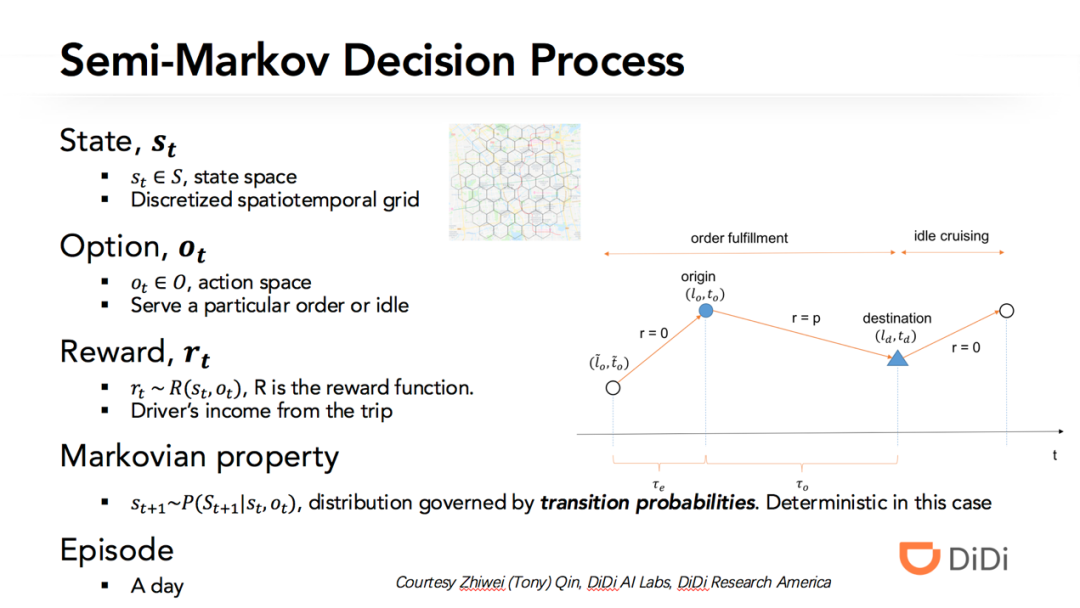
3 网约车交易市场优化中的深度强化学习方法
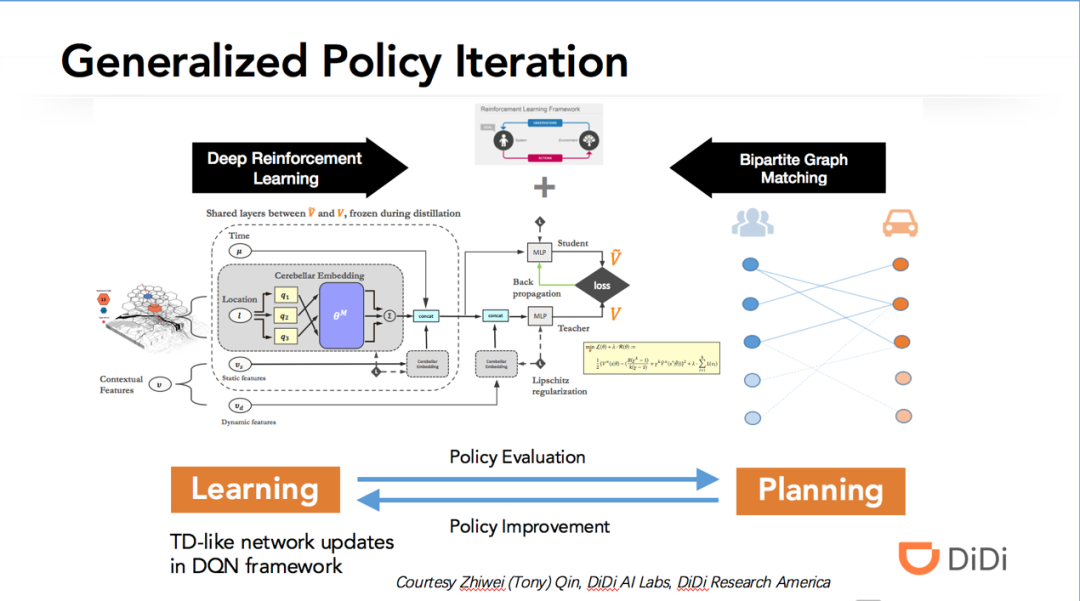

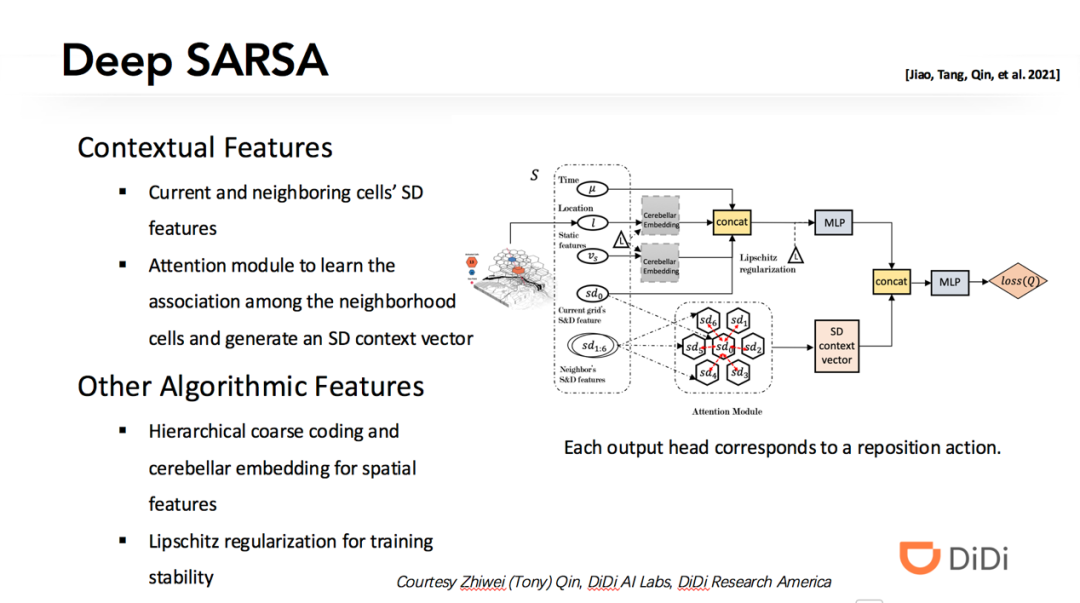

Q1:请问这个累积订单需求的这个时间窗如何确定?
答:时间窗需要综合用户体验,匹配最优性,等多种因素。
Q2:多智能体强化学习面对状态空间爆炸时怎么处理?
答:对于状态空间大的问题,一方面可以用价值函数逼近的方法通过回归来学习价值;另一方面可以运用例如 mean-field MARL 这样的近似方法,使得智能体之间的关系变成和一个抽象邻居的关系。
Q3:派单问题的 reward 是什么?
答:在基本建模中是司机收入。
Q4:之前看这篇paper的时候想把问题从 one-to-one matching 拓展到ride-sharing matching,如果我只是简单地修改条件为:只要车上还有空余位置就再次把车放进时空网格里匹配,请问您觉得这样能训练出合适的 ride-sharing 策略吗? 这篇文章会开源代码吗?
答:对于多乘客 ridesharing 的 RL 建模,不只是简单的匹配条件修改,还需要仔细刻画车上已负载的订单行程状态。可以参考 RL 文献中关于 carpool 的论文。
4 启元世界强化学习智能体的研究和应用
来自启元公司的王湘君进行了其公司有关强化学习方向的研究和产品的介绍。本次王湘君的主要展示内容分为三大部分,分别是星际争霸游戏 AI,机器人 AI 以及游戏智能体在 AI 虚拟玩家方向的应用和工作。
Q1:针对一个很复杂的大型任务,从零开始训练到 work 起来涉及到网络结构、reward 设计、算法选择与参数调整等一系列的问题,请问老师有没有什么强化学习工程上的经验可以分享帮助快速定位强化学习算法表现不佳的瓶颈位置?
答:先 breakdown problems,比如在模仿学习上验证网络结构,在小数据集或者相对简单的场景上验证 reward 设计,算法选择和超参数等,做实验对比的时候小步迭代快速验证。
Q2:对于没有联赛进行训练的问题,有什么比较好的训练方法吗?
答:Self-play 也有不同的机制, fictitious self-play (FSP), priority fictitious self-play (PFSP), Policy Space Response Oracles (PSRO) 等等。
Q3:当在 full game 中随着更多单位的出现,感觉动作空间也在一直变化,是如何设计 agent 的动作空间呢?
答:动作空间是支持所有单位的 full action space,invalid 的 action space 可以做 masking,也可以从数据里面自动学出概率,具体设计可以参考 paper 细节。
Q4:最终 reward 是设计为 1 还是 10 还是多少?
答:胜为 1,负为 -1。
Q5:请问老师 statistics Z 是如何发挥作用的,作为辅助奖励函数吗?
答:一方面作为输入变量控制打法风格,另一方面作为奖励进一步强化引导风格。
Q6:联赛的机制对于 moba AI 有无价值?
答:对有多种策略的游戏的多样性和鲁棒性都会有帮助。
Q7:我想提一个问题,SCC 通过哪些方法证策略的多样性(避免局部最优)?
具体在解决策略探索和避免 overfit 方面有什么好的方法?
答:主要是通过模仿学习,联赛机制,Z statistics, KL constraint 等。
Q8:RL 控制的机器人的优势和问题是什么?
答:作为通用技术方法,可以在不同动态复杂问题场景上能够自学习自主决策,传统方法需要较多人工定制;另外 RL 做底层控制能够在低成本,精度不高的硬件上能够自适应,取得更好的控制效果。
5 基于强化学习的游戏参数设计

欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。







