NeurIPS2021 | 华南理工提出SS-Conv:兼顾加速与SE(3)等变性,3D空间姿态估计突出
来自华南理工大学等机构的研究者提出了一个新颖的稀疏姿态可控卷积(SS-Conv),SS-Conv 不仅利用稀疏张量对姿态可控卷积进行极大地加速,还在特征学习中严格地保持 SE(3) 等变性。
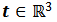 表示平移。
图 1(a) 进一步给出了解释,给定输入的一个 SE(3) 变换,特征向量所在位置均关于(r,t)进行刚性变换,而特征向量 ρ(r)
本身也关于进行旋转(
ρ
(r)
是旋转r的一个表征)。
SE(3) 等变的特性激活了特征空间的姿态可控性,例如,SE(3) 变换可通过对特征空间进行操控来直接实现,而无需变换输入。
为了生成姿态可控特征,ST-Conv 将特征域限定在 3D 体素数据的规则网格上,使其能通过 3D 卷积方便地实现。
对 3D 卷积的兼容简化了 ST-Conv 的实现,但也牺牲了对不规则且稀疏的 3D 数据(例如,点云)的高效处理,导致 ST-Conv 未能在更多 3D 语义分析领域中被广泛使用。
表示平移。
图 1(a) 进一步给出了解释,给定输入的一个 SE(3) 变换,特征向量所在位置均关于(r,t)进行刚性变换,而特征向量 ρ(r)
本身也关于进行旋转(
ρ
(r)
是旋转r的一个表征)。
SE(3) 等变的特性激活了特征空间的姿态可控性,例如,SE(3) 变换可通过对特征空间进行操控来直接实现,而无需变换输入。
为了生成姿态可控特征,ST-Conv 将特征域限定在 3D 体素数据的规则网格上,使其能通过 3D 卷积方便地实现。
对 3D 卷积的兼容简化了 ST-Conv 的实现,但也牺牲了对不规则且稀疏的 3D 数据(例如,点云)的高效处理,导致 ST-Conv 未能在更多 3D 语义分析领域中被广泛使用。

论文链接:https://arxiv.org/abs/2111.07383
代码链接:https://github.com/Gorilla-Lab-SCUT/SS-Conv
 ,则 SS-Conv 可定义为:
,则 SS-Conv 可定义为:

 表示位置x在特征空间
表示位置x在特征空间
 中的状态。
中的状态。
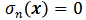 代表位置x未激活,特征
代表位置x未激活,特征
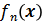 处于基态;
处于基态;
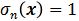 代表位置x已被激活,
代表位置x已被激活,
 处于激活态。
处于激活态。
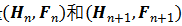 ,其中,
,其中,
 为哈希表,记录着激活位置的坐标,而
为哈希表,记录着激活位置的坐标,而
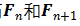 为特征矩阵。对于一个稀疏张量,其哈希表和特征矩阵行对行地相互对应。
为特征矩阵。对于一个稀疏张量,其哈希表和特征矩阵行对行地相互对应。
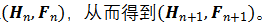 因此可分三个步骤进行实现 SS-Conv:i) 通过旋转可控卷积核的建立,获得卷积核k;ii)通过位置状态的定义,获得输出哈希表
因此可分三个步骤进行实现 SS-Conv:i) 通过旋转可控卷积核的建立,获得卷积核k;ii)通过位置状态的定义,获得输出哈希表
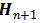 ;ii)通过稀疏卷积的操作,获得输出特征矩阵
;ii)通过稀疏卷积的操作,获得输出特征矩阵

 可以给出解答,基于球形谐波的基核的线性组合来生成旋转可控的卷积核。
可以给出解答,基于球形谐波的基核的线性组合来生成旋转可控的卷积核。
 可
以表示为基核
可
以表示为基核
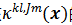 的线性组合:
的线性组合:

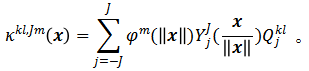
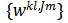 是一组可学习的系数,
是一组可学习的系数,
 是一个连续的高斯径向函数
是一个连续的高斯径向函数
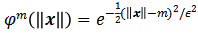 ,
,
 是一个 (2k+1)(2l+1)
大小的基变换矩阵。
是一个 (2k+1)(2l+1)
大小的基变换矩阵。
 ,则在x位置处整个旋转可控的卷积核k(x)可表示为:
,则在x位置处整个旋转可控的卷积核k(x)可表示为:
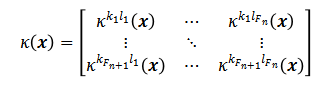
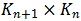 ,其中
,其中
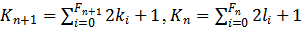 。
。

 。
。
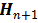 后,下一个目标为计算
后,下一个目标为计算
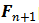 的值。特别地,
先被初始化为零矩阵,继而通过以下算法来更新其中特征向量:
的值。特别地,
先被初始化为零矩阵,继而通过以下算法来更新其中特征向量:
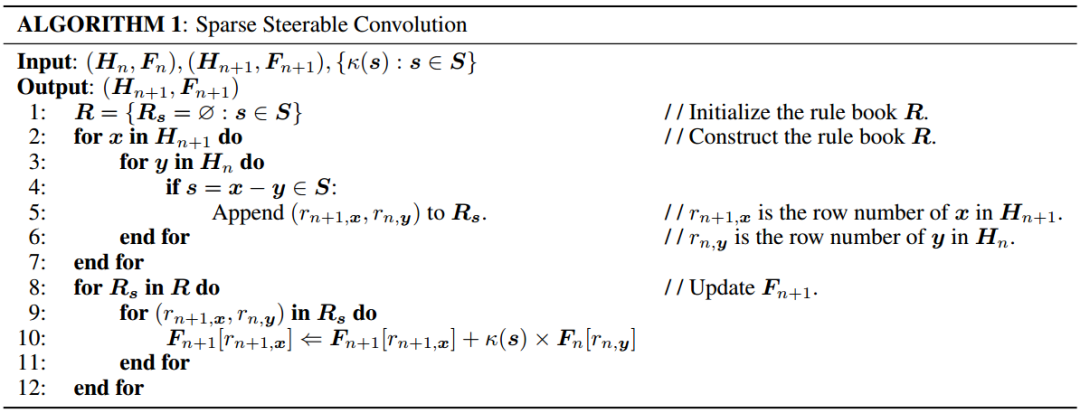
 来记录匹配的激活输入位置y和输出位置x, 第二步是根据R中的匹配关系来更新
来记录匹配的激活输入位置y和输出位置x, 第二步是根据R中的匹配关系来更新
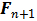 。在这个过程中,R的建立非常重要,使得第二步可以在 GPU 上利用矩阵加乘操作高效地实现。
。在这个过程中,R的建立非常重要,使得第二步可以在 GPU 上利用矩阵加乘操作高效地实现。





© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月17日



相关VIP内容
相关资讯