©PaperWeekly 原创 · 作者 |
邴立东、丁博生
单位 | 阿里达摩院语言智能实验室
在过去的几年里,有一个趋势是探索多语言任务型对话(ToD)系统的数据构造方法,让任务型对话系统可以服务于不同国家不同语言的用户。然而, 现有的多语言 ToD 数据集要么由于语言的覆盖范围有限,要么是数据构建成本高,或者是忽略了很多英语的实体并不存在于其他国家这一非常关键的实际情况。
为了解决这些局限,我们引入了一种新颖的数据生成方法并且构建了 GlobalWoZ 这个大规模的多语言 ToD 数据集。我们的方法首先翻译对话模板,然后用目标语言国家的实体来填充这些模版。此外,我们将覆盖范围扩大到 20 种目标语言。我们发布 GlobalWoZ 数据集的同时,提供了一组基线模型在该数据上的表现评测,以方便更多研究者参与进来,一起构建用于实际应用场景的多语言 ToD 系统。
论文标题:
GlobalWoZ: Globalizing MultiWoZ to Develop Multilingual Task-Oriented Dialogue Systems
ACL 2022
https://aclanthology.org/2022.acl-long.115.pdf
https://ntunlpsg.github.io/project/globalwoz/
![]()
任务型对话是学术界和工业界都非常关心的方向,它可以完成很多辅助人类的动作,比如闹钟设置、餐厅预定。近年来,由于深度学习的发展,任务型对话也是突飞猛进。然而,目前的任务型对话,往往集中在几个高资源语言,比如英语、中文等等。
目前现有方法主要有两条路径,第一条路径是从零开始用人工标注数据,这个路径质量最高,但是成本高昂。另外一条路径是利用翻译,把英语数据或者其他高资源语言的数据,翻译成目标语言,这个路径,成本比较低,但是有很大的局限性,就是没有考虑到每个语言每个国家都有自己本土化的实体。
直接翻译,其实往往会因为英语的实体并不存在目标语言使用人群所在的国家或地区,而导致得到的多语言对话系统很难发挥实际用途。如图 1 中所示,说英语的游客在伦敦旅行会询问伦敦当地的景点(图1 A),我们将这种场景称为 E&E,而中文游客在上海旅行的时候会询问上海本地的景点 (图1 B),我们将这种场景称为 F&F。
同时,在真实场景中,我们观察到了另外两种情况,即 Code-Mixed 的情况。具体而言,有两种情况,一种是目标语言的游客到英语国家玩 (如图1 C),我们称之为 F&E,另外一种情况是英语游客到非英语国家玩(如图1 D),我们称之为 E&F。
本文主要针对后面三种场景提出了新的数据构建框架,从而能够在本土化和成本两个维度达到最优。
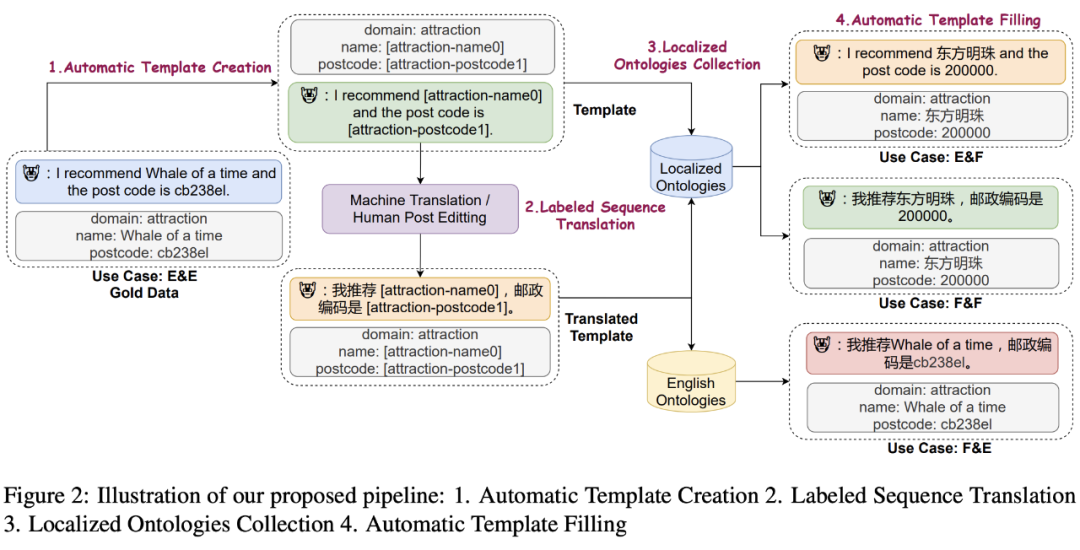
如图 2 所示。在我们的框架中,我们有以下几个步骤:第一步,通过有标数据的标签,标注数据替换称为带有占位符的模版。第二步,对带有占位符的模版进行机器翻译。如果要实现更高的精度可以对机器翻译后的结果进行人工校准。第三步,构造一个有本土化实体的数据库。第四步,将构建好的数据库,按照不同使用场景,还原到对应的模版中,从而得到了新的数据。
例如:I recommend Whale of a time and the post code is cb238el。可以替换成 I recommend [attraction-name0] and the post code is [attraction-postcode1]。然后通过模版翻译可以得到中文的模版:我推荐 [attraction-name0] 邮编是 [attraction-postcode1]。然后再从本土化的实体库里面找到对应的景点名称和邮编,例如东方明珠和 200000。最终即可合成中文的训练数据:我推荐东方明珠,邮编是 200000。
![]()
实验结果
本文在构建的数据集进行了 DST 的实验。主要是在 Transformer-DST 的模型上把 BERT encoder 换成 mBERT encoder 去进行实验的。
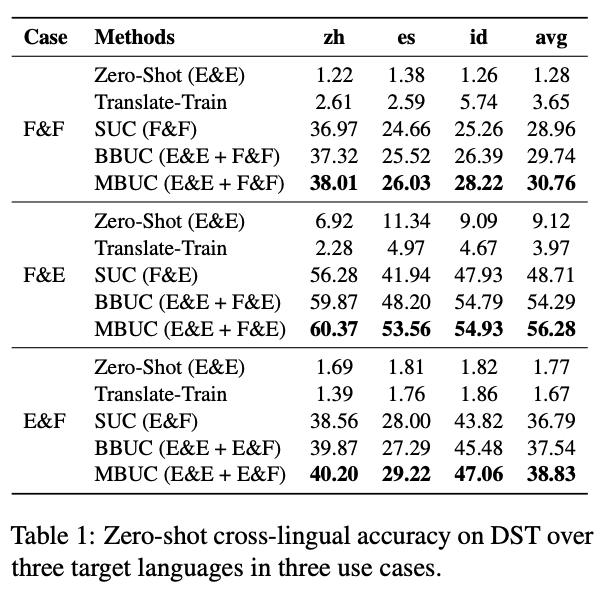
同时我们也准备了几个实验基准,包括:1. 用英语数据进行零样本迁移 (Zero-Shot);2. 翻译训练数据(Translate-Train);3. 用我们方法构造的单一场景训练数据(SUC);4. 用英语数据和构造的单一场景单语言训练数据进行混合(BBUC);5. 用英语数据和构造的单一场景多语言训练数据进行混合(MBUC);6. 用英语数据和构造的多场景多语言训练数据进行混合(MMUC)。
如图3所示,实验表明现阶段的零样本学习和翻译训练数据两种方法在新的数据集上表现比较糟糕。特别是翻译训练数据,并不能在我们提出的真实场景下起到理想的作用。而当训练数据中存在本土化实体(例如:SUC),模型的表现有较大的提升。除此之外,SUC、BBUC 到 MBUC 整体的表现是上升的,这也与之前的多语言 NLP 的发现相吻合。
如图4所示,MMUC 虽然不是在每一个场景下都达到最佳效果,但是在四个场景下达到了平均效果最佳,这也说明 One Model for All 存在其可能性。
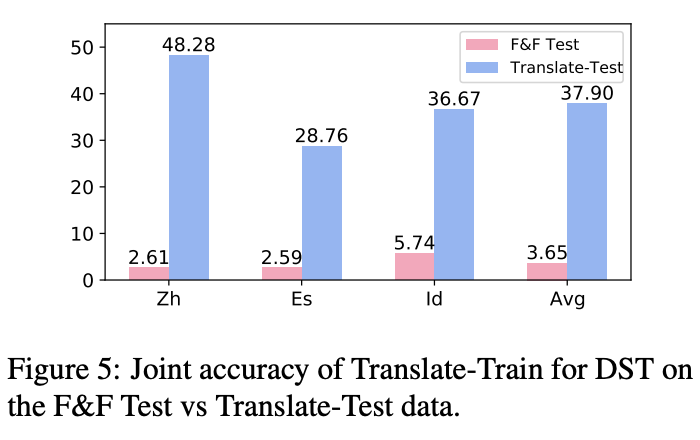
我们观察到一个比较重要的现象是 Translate-Train 其实并没有在实际应用场景中发挥作用。我们发现 Translate-Train 在我们构建的本土化数据集上的表现其实是比较差的。在以前的基于翻译方法的工作中,多语言 ToD 系统通常是基于翻译构建的英语训练数据(Translate-Train),并且是在没有任何本地实体的情况下对翻译的测试数据进行评估。
要验证这是否建立多语言 ToD 的过程是可靠的系统,我们还创建了一个带有翻译实体的测试数据集(Translate-Test),而不是目标语言的本地实体。如图5所示,我们发现 Translate-Train 模型在测试中表现良好 具有翻译实体的数据,但在具有真实本地实体的测试数据,表现则不尽如人意。这就说明过往的实验其实是高估了 Translate-Train 的表现。在实际应用中,Translate-Train 不是一个很实用的方法。
▲ 图5 Translate-Train在不同测试集上的表现
![]()
拓展到更多的语言
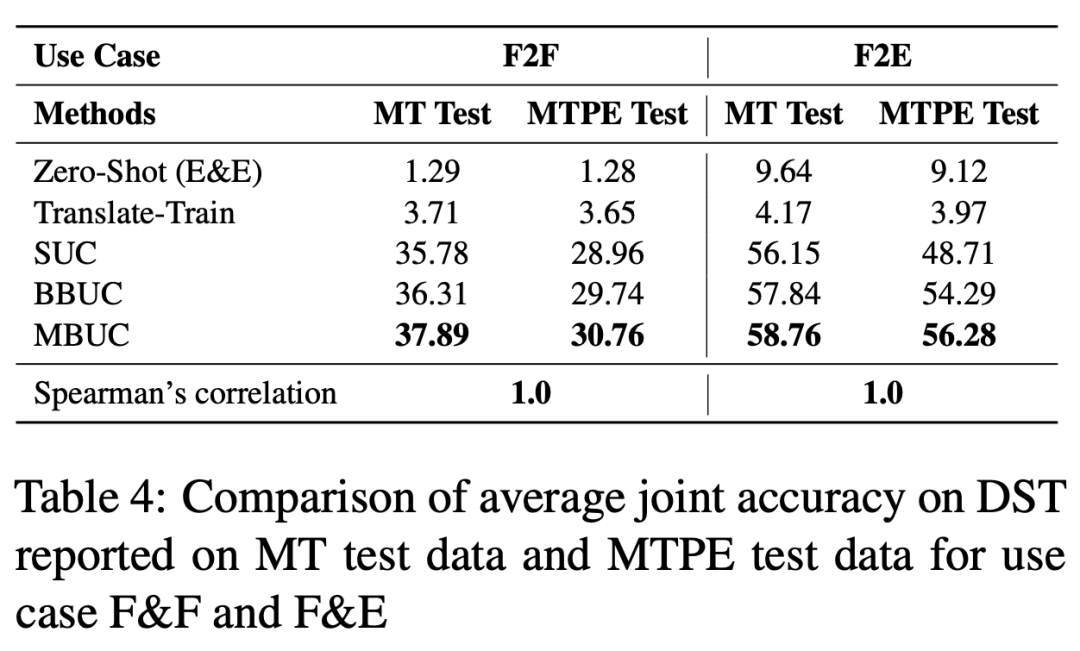
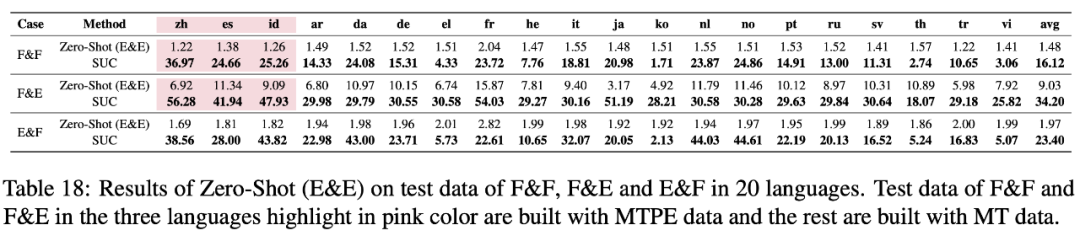
通过我们提出的数据构造方法,可以扩展数据集以涵盖更多语言。但这里有个关键问题,翻译数据有无人工编辑是否影响实验数据。因此我们做了一组对比实验,对比 MT 和 MTPE 两组测试数据:1)MT:测试数据翻译模板由机器翻译创建;2)MTPE : 测试数据模板首先由机器翻译,然后由专业翻译人员发布。
如图所示,在图 6 中,MT 测试数据总体的报告结果高于 MTPE 测试数据报告的结果,这是符合预期的,因为 MT 测试数据的分布更类似于 MT 训练数据。
尽管在个别语言上存在一些差异,但从两组数据上得出的大体结论是一致的。另外,我们还计算了两组结果之间的 Spearman’s Rank Correlation 系数。MTPE 测试数据和 MT 测试数据报告显示出统计学上的高度相关性。
基于这个发现,这为利用 MT 构建更多语言的数据提供了理论基础。因此,我们收集了 20 个语言的本地化实体,并且将英语模版翻译成 20 个语言。并且给出了一些基本的实验结果。以往的数据集,往往只聚焦于几种语言,我们在这个数据集上拓展到了 20 种语言,也是希望可以让更多人从 AI 的进步中获益。构建多语言任务型对话数据集,工程量相对较大,难免有疏漏之处。欢迎各位老师同学朋友们的批评指正,让我们一起推动多语言任务型对话的发展。
在本文中,我们对面向多语言任务型对话系统的应用场景进行了分析。我们提出了一个新的数据构造方式,利用机器翻译和目标语言的本地实体创建一个新的多语言 ToD 数据集 GlobalWoZ。我们提出了一系列强大的基线方法,并在 GlobalWoZ 上进行了广泛的实验,以鼓励研究多语言 ToD 系统。此外,我们将覆盖范围扩大到 20 种目标语言,朝着为全世界用户构建全球化多语言 ToD 系统迈进。
本文由阿里达摩院语言智能实验室邴立东、阿里-NTU 联培博士生丁博生等共同整理。PaperWeekly 的编辑进行了校对和排版。
[1] Linlin Liu, Bosheng Ding, Lidong Bing, Shafiq Joty, Luo Si, and Chunyan Miao. 2021. MulDA: A multilingual data augmentation framework for lowresource cross-lingual NER. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP), Volume 1: Long Papers, pages 5834– 5846
[2] Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašic. 2018. MultiWOZ - a large-scale multi-domain Wizard-of-Oz dataset for task-oriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5016– 5026
[3] Xiaoxue Zang, Abhinav Rastogi, Srinivas Sunkara, Raghav Gupta, Jianguo Zhang, and Jindong Chen. 2020. MultiWOZ 2.2 : A dialogue dataset with additional annotation corrections and state tracking baselines. In Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI, pages 109–117
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
![]()