WWW'22 | 图神经网络推荐系统的最新SOTA基准
关注我们,一起学习~
title:Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning
link:https://arxiv.53yu.com/pdf/2202.06200.pdf
code:https://github.com/RUCAIBox/NCL
from:WWW 2022
预备知识:图神经网络,序列推荐,k-means
1. 导读
本文利用对比学习缓解推荐系统中数据稀疏问题,并且利用图方法在对比学习中考虑邻域节点之间的关系。本文提出NCL方法,主要从两方面考虑对比关系,
-
一方面,考虑图结构上的用户-用户邻居,商品-商品邻居的对比关系 -
另一方面,从节点表征出发,聚类后,节点与聚类中心构成对比关系
想法还是有点意思的,熟悉GNN和推荐的小伙伴可以跳过第二节。
2. 基础
用户集合为 ,商品集合为 ,观察到的隐式反馈矩阵为 ,等于1说明存在交互。基于交互矩阵可以构建图 ,节点集合 ,边 表示用户节点和商品节点存在交互。一般协同过滤中的GNN过程可以包括两部分,信息传播和表征聚合,公式如下,
3. 方法
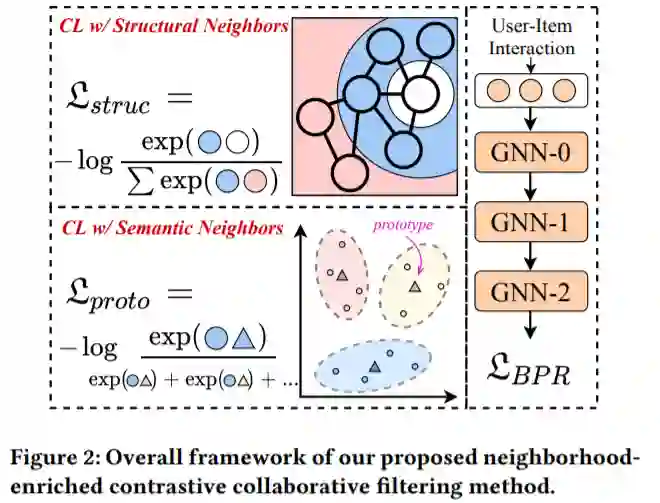
3.1 结构邻居的对比学习
现有的图协同过滤模型主要是通过观察到的交互(例如,用户-商品对)来训练的,而用户或商品之间的潜在关系不能通过从观察到的数据中学习来明确地捕获。本节提出将每个用户(或商品)与他的结构邻居进行对比,这些邻居的表征是通过 GNN 的层传播来聚合的。
以GNN为基模型的推荐模型,如LightGCN,初始embedding表示为 ,经过 层消息传播可以得到 ,最终的输出是将不同层的embedding进行加权求和。
交互图 G 是一个二分图,基于 GNN 的模型在图上的偶数次信息传播自然地聚合了同构结构邻居的信息,这便于提取用户或商品内的潜在邻居,如u-i-u,可以得到两个相邻的用户。通过这种方式,可以从 GNN 模型的偶数层(例如,2、4、6)输出中获得同质邻域的表征。通过这些表征,可以有效地建模用户/商品与其同质结构邻居之间的关系。将用户自己的embedding和偶数层 GNN 的相应输出的embedding视为正对。基于 InfoNCE,用户相关的目标函数如下所示,其中 是第k层的输出,k是偶数,τ是超参数,
同理可得商品相关的对比损失,如下所示
总损失为
3.2 语义邻居的对比学习
结构对比损失显式挖掘了由交互图定义的邻居。然而,结构对比损失平等地对待用户/商品的同质邻居,这不可避免地将噪声信息引入对比对。因此,通过结合语义邻居来扩展对比对,语义邻居是指图上无法到达但具有相似特征(商品节点)或偏好(用户节点)的节点。
这部分通过聚类,将相似embedding对应的节点划分的相同的簇,用簇中心代表这个簇,这个中心称为原型。由于该过程无法进行端到端优化(回顾k-means的过程),使用 EM 算法学习提出的原型对比目标。聚类中GNN模型的目标是最大化下式(用户相关),简单理解就是让用户embedding划分到某个簇,其中θ为可学习参数,R为交互矩阵,c是用户u的潜在原型。同理也可以得到商品相关的目标式。
和结构邻居类似,可以构建语义邻域的对比损失,公式如下,其中𝑐𝑖是用户𝑢的原型,它是通过使用𝐾-means算法对所有用户embedding进行聚类得到的,并且所有用户都有𝑘个簇。
总损失为
3.3 优化
本节使用 EM 算法优化提出的原型对比目标的整体损失。
3.3.1 总体训练目标
将提出的两个对比学习损失作为补充,并利用多任务学习策略来联合训练传统的排序损失和提出的对比损失,公式如下,
3.3.2 EM算法优化
通过 Jensen 不等式可以得到上面聚类目标函数的下界,如下所示,其中Q()表示在e条件下潜在变量c的分布,当估计Q()时,
E步
固定 ,通过k-means进行聚类得到不同用户embedding对应的中心,如果 属于中心 ,则 反之为0。白话:根据embedding计算每个簇的中心。
M步
在得到了中心后,目标函数重写为下式,
假设所有簇中用户分布都是高斯分布,则目标函数改写为下式,
若 , 经过标准化,则 ,假设不同簇的方差一样则可以简化为“语义近邻对比学习”中的 和 。因此,M步就是利用上一节的对比损失优化。白话:根据计算的中心和embedding计算优化L_p的对比损失。
4. 结果