CVPR22 | 人体姿态估计新框架开源!利用Transformer来学习3D人体姿态的多假设表示

极市导读
在本文中,来自北京大学、苏黎世联邦理工学院、阿里巴巴的研究者们提出了一种基于多假设Transformer的三维人体姿态估计新框架MHFormer,来减轻三维人体姿态估计中的歧义逆问题。性能超越PoseFormer 3%,并在Human3.6M和MPI-INF-3DHP数据集上都取得了当前最佳的性能。代码已开源! >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文:MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation 单位:北京大学、苏黎世联邦理工学院、阿里巴巴 地址: https://arxiv.org/pdf/2111.12707.pdf 代码: https://github.com/Vegetebird/MHFormer
任务介绍
三维人体姿态估计旨在利用计算机视觉技术,从图片或视频中估计出人体关键点在三维空间中的坐标。它可广泛用于虚拟现实、元宇宙、体育比赛中(冬奥运实时动捕、滑雪)。该任务通常被解耦成2个子任务:二维姿态估计和二维到三维姿态提升(2D-to-3D Pose Lifting)。尽管该方法目前已经取得了不错的性能,但是它还面临着许多挑战,例如二维到三维映射的深度模糊性与人体的自遮挡问题。
研究动机

先前的工作尝试使用时空图卷积或时空Transformer来利用时空约束来解决该问题。然而,该任务也是一个存在多个可行解(假设)的逆问题(inverse problem),具有巨大的歧义性。该问题的产生主要是由于相机成像过程中深度信息的丢失,造成多个三维姿态投影到二维空间可能存在相同的二维姿态。从而形成一对多的病态问题,并且在遮挡的情况下该问题会被进一步放大。这些工作大多忽略了该问题本质上是个逆问题,并且只假设存在一个解,这通常会导致估计出不满意的结果(见图1)。
目前,只有少量的工作提出基于生成多个假设的方法。他们通常依赖于一对多的映射,将多个输出头添加到具有共享特征提取器的现有架构中,而未能建立不同假设特征之间的联系。这是一个重要的缺点,因为这种能力对于提高模型的表现力和性能至关重要。鉴于三维人体姿态估计的歧义逆问题,本文认为先进行一对多的映射,然后再将生成的多个中间假设进行多对一的映射更为合理,因为这种方式可以丰富模型的特征并可以合成更精确的三维姿态。
模型方法
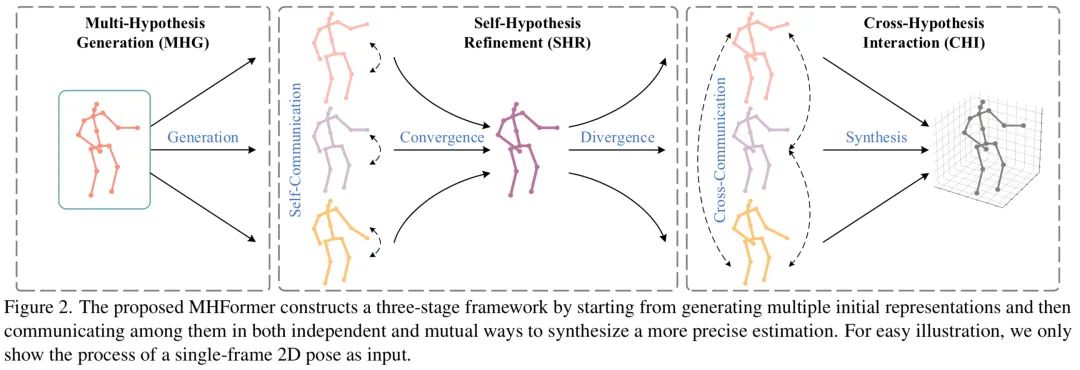
这篇文章的核心思想是通过学习多重姿态假设的时空表示来合成更准确的三维姿态。为了实现这一点,作者提出了一个三阶段框架,叫多假设Transformer(Multi-Hypothesis Transformer,MHFormer)。如图2所示,该框架从生成多个初始表示开始,逐渐在它们之间进行通信以合成更准确的估计。该框架可以有效地建模多假设的依赖,并在假设特征之间建立牢固的联系。
以下这张图是本文的具体网络结构。这张图很大,但还是挺好理解的。左上角的图a是MHFormer的整体框架。输入是二维姿态序列,输出是中间帧的三维姿态。MHFormer总共包括三个主要模块:多假设生成器(右上角图b),自假设修正器(左下角图c),交叉假设交互器(右下角图d)和2个辅助模块:时间嵌入,回归头。
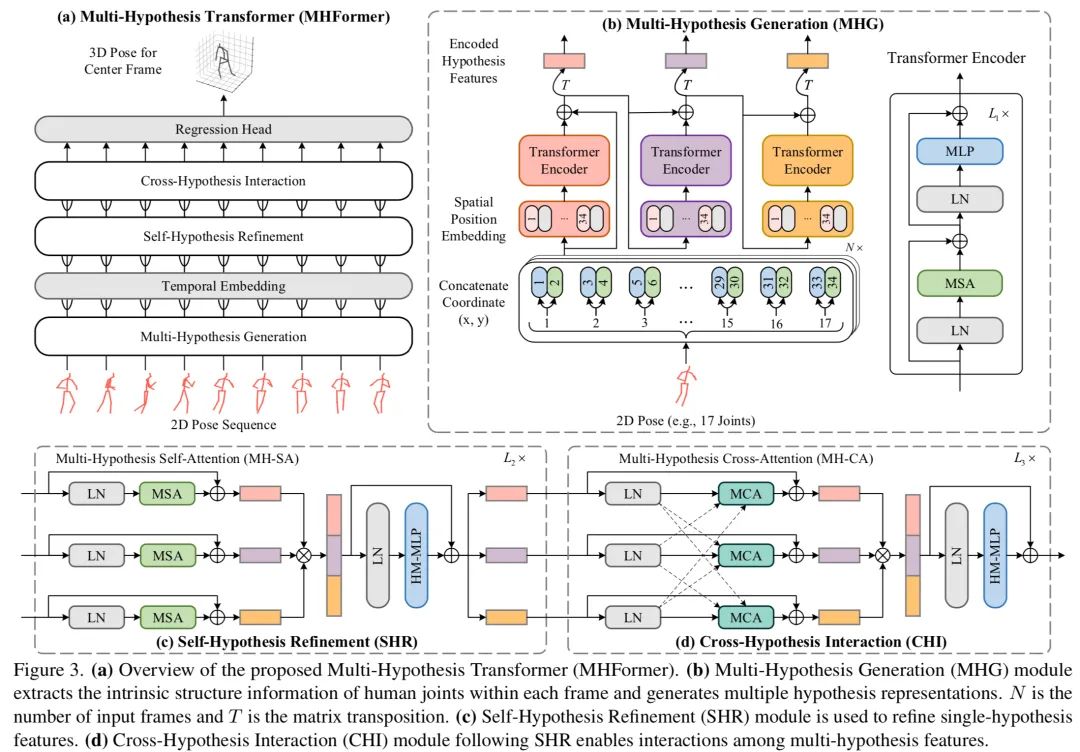
多假设生成
在空间域中,作者通过设计一个基于Transformer的级联架构来建模每帧人体关键点的内在结构信息,并在网络的不同层生成姿态假设的不同表示。该模块命名为多假设生成器(Multi-Hypothesis Generation,MHG),公式如下:
时间嵌入
MHG在空域将多级特征视作姿态假设的初始表示,然而他们的特征表达能力是比较有限的。考虑到这点,本文接下来对这些特征在时域进行捕获依赖性并建立特征之间的联系以进行信息增强。
那么要想利用时序信息,首先应将特征从空域转化到时域。因此,本文首先用了一个矩阵转置操作,来交换矩阵的维度,并对特征进行编码同时引入帧的位置信息。
自假设修正
自假设修正器(Self-Hypothesis Refinement,SHR)对每个假设表示进行修正,其中每层包含一个多假设自注意力(multi-hypothesis self-attention,MH-SA)和一个假设混合MLP(hypothesis-mixing multi-layer perceptron)。
MH-SA包含多个并行的自注意力块,它独立地对单假设依赖进行建模,以形成自我假设通信:
假设混合MLP用来交换假设之间的信息,各个假设特征首先拼接起来通过MLP来提取特征,然后对其进行切块来得到修正后的每个假设表示:
交叉假设交互
交叉假设交互器(Cross-Hypothesis Interaction,CHI)对不同假设的信息进行交互建模,其中每层包含一个多假设交叉注意力(multi-hypothesis cross-attention,MH-CA)和一个假设混合MLP。
尽管SHR已经修正了表示,但在MH-SA中只传递每个假设的内部信息,因此不同假设之间的联系还不够牢固。因此,作者提出了个包含多个并行交叉注意力块的MH-CA来同时捕获多假设的依赖性,形成交叉假设通信:
随后使用假设混合MLP来交换假设之间的信息:
回归头
在回归头模块中,使用一个线性层来作用于CHI的输出,来回归得到最终的3D姿态。
实验结果
与SOTA方法的对比
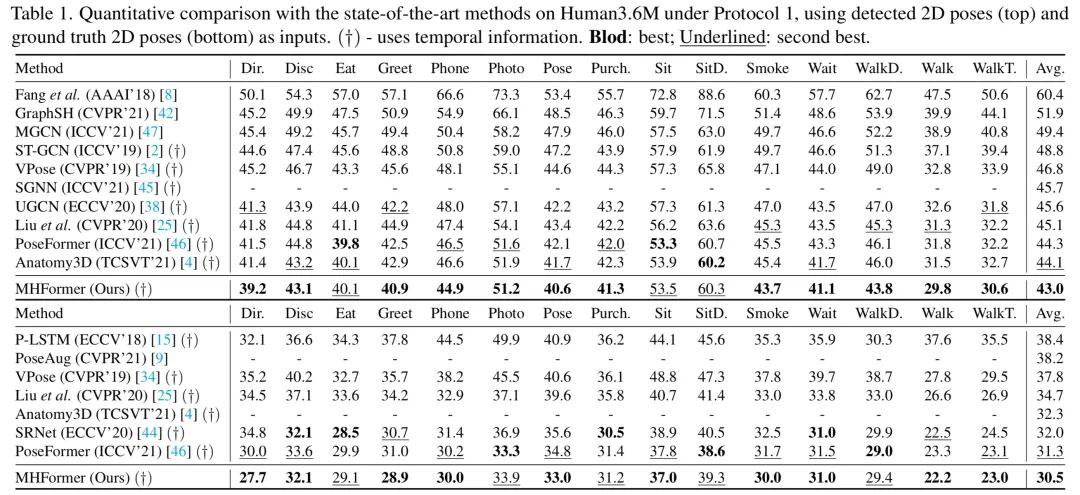
从表中可见,提出的MHFormer在三维人体姿态估计最具有代表性的数据集Human3.6M上实现了SOTA的性能。作者跟大量的21年最新方法进行了对比,并在平均关键点误差(MPJPE)上超越PoseFormer(ICCV 2021) 1.3mm,3%的提升。
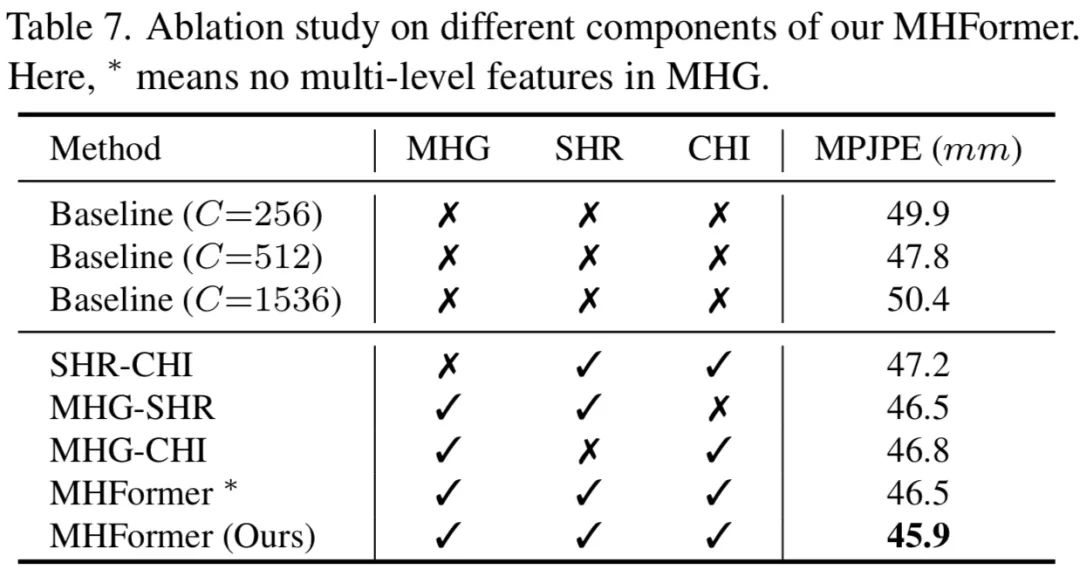
消融实验
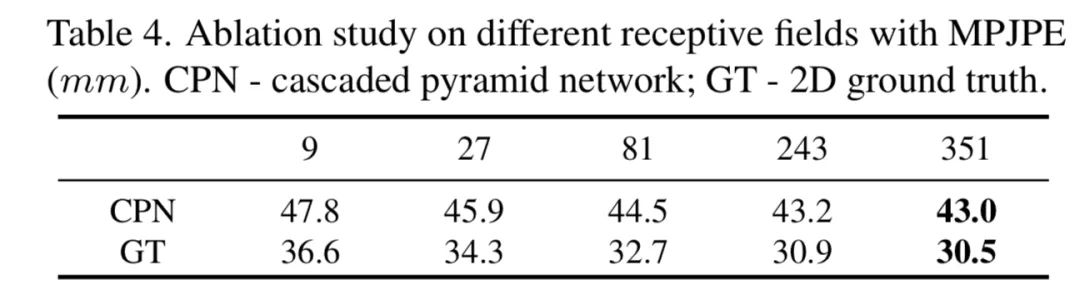
作者给出了在不同感受野,也就是不同的输入帧数下模型的结果。可以发现随着帧数增大,性能得到大幅度提升,但饱和在351帧上。
作者给出了不同模块对模型的影响。其中Baseline为标准的Transformer结构(ViT)。可以发现所提出的模块均可提升性能。这些结果表明,学习多假设时空表示对于三维人体姿态估计具有重要意义,并且应该以独立(SHR模块)和交互(CHI模块)的方式对不同的假设表示进行建模。
更详细的结果与分析见原文。
可视化结果
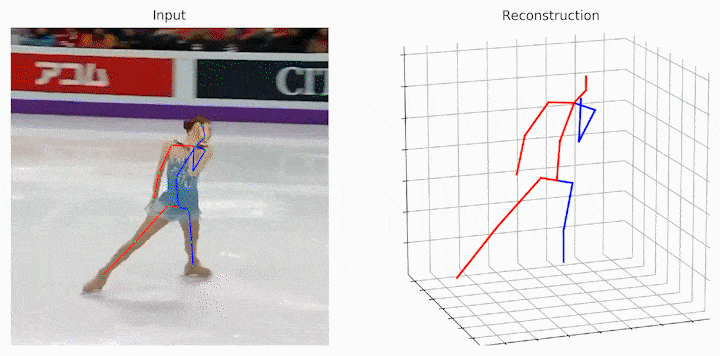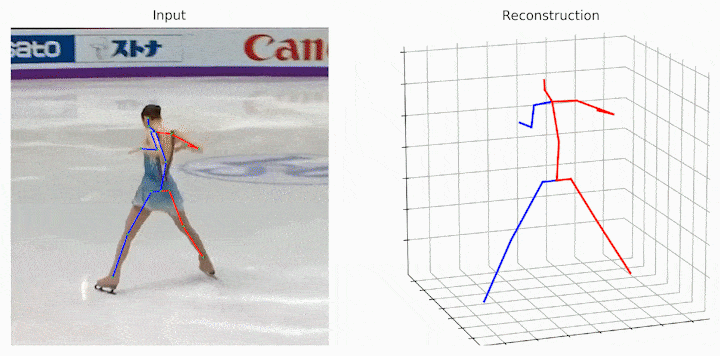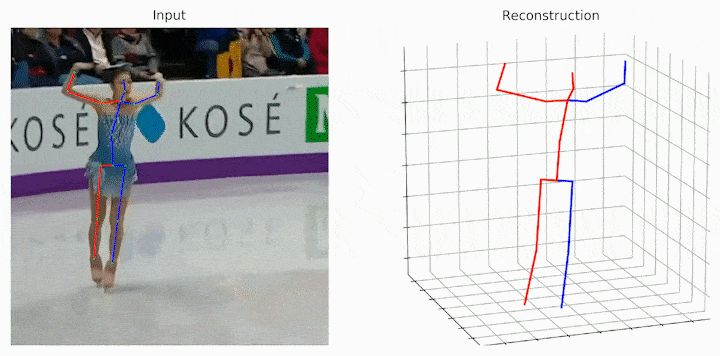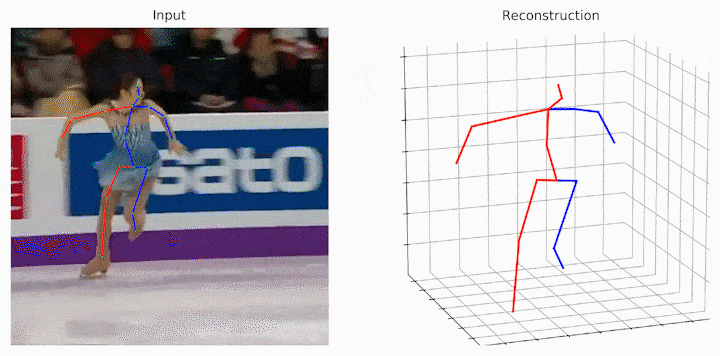
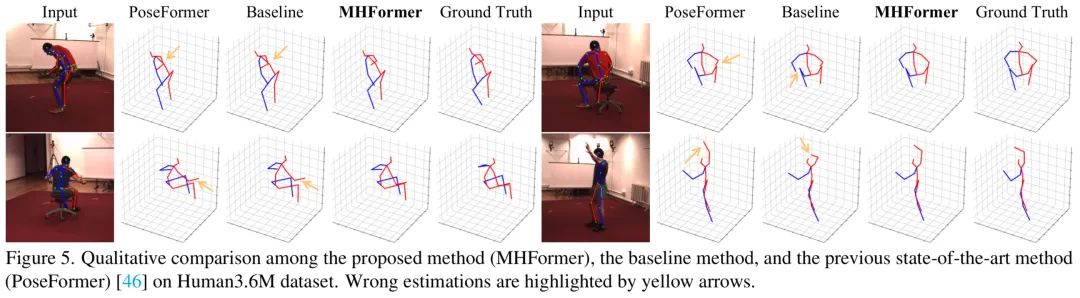
作者给出了跟之前的SOTA和Baselie的可视化结果对比,可见提出的MHFormer取得了更好的结果。
作者还给出了一些中间假设姿态可视化的结果。可见在一些具有深度模糊、自遮挡和 2D 检测器不确定性的歧义身体部位,MHFormer可以生成多个合理的3D姿态解,并通过聚合多假设信息合成的最终结果更加合理和精准。

代码运行
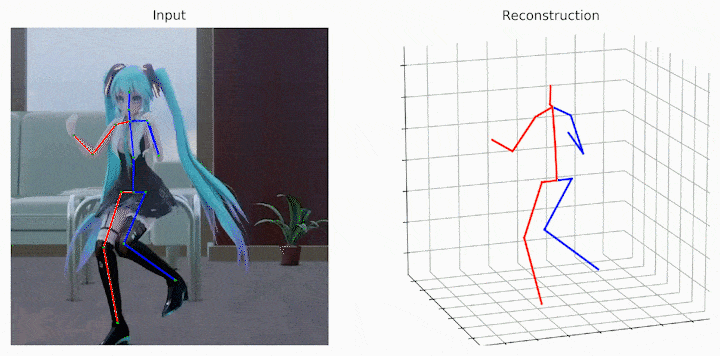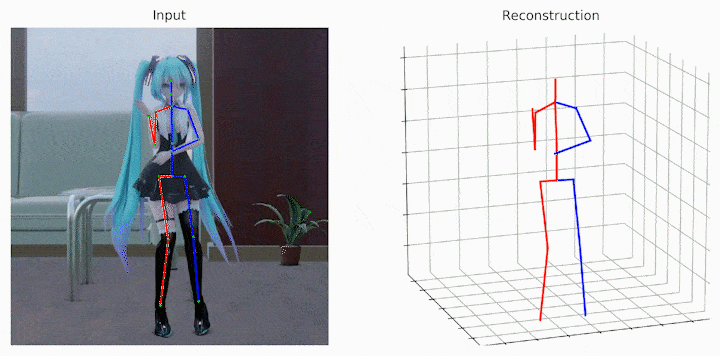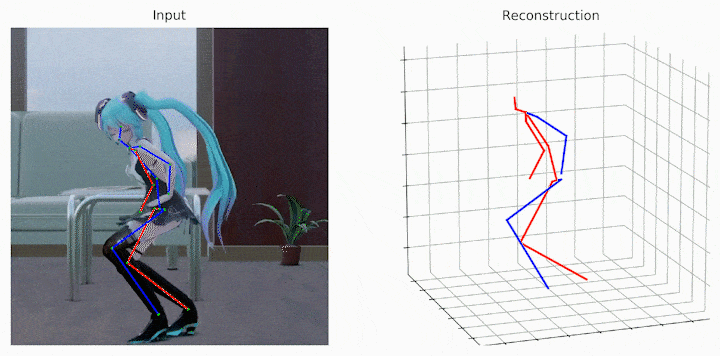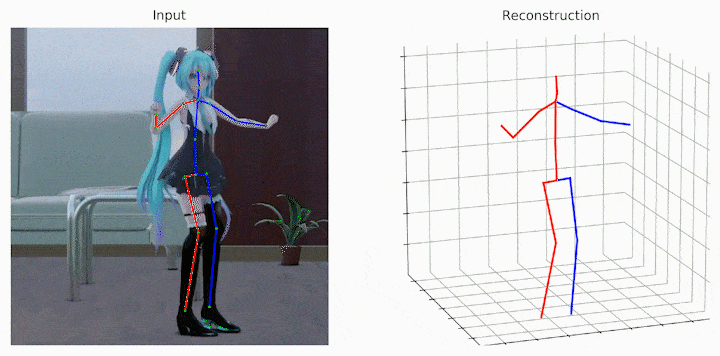
作者还给出了demo运行(https://github.com/Vegetebird/MHFormer),集成了YOLOv3人体检测器、HRNet二维姿态检测器、MHFormer二维到三维姿态提升器。只需下载作者提供的预训练模型,输入一小段带人的小视频,便可一行代码直接输出三维姿态估计demo。
python demo/vis.py --video sample_video.mp4
运行样例视频得到的结果:
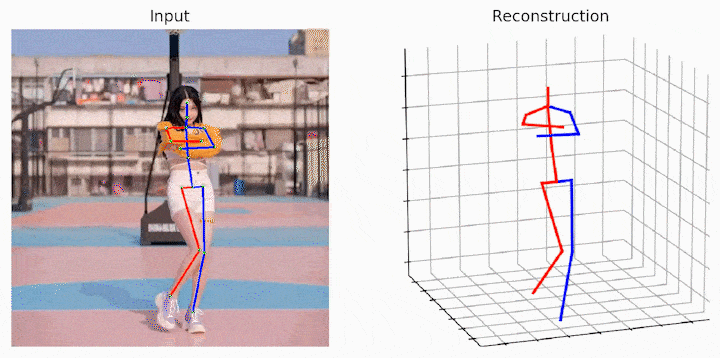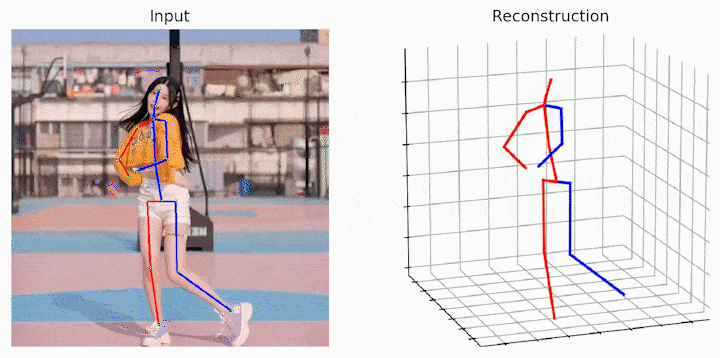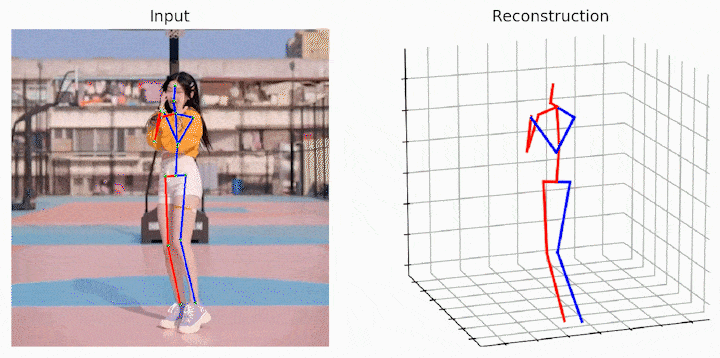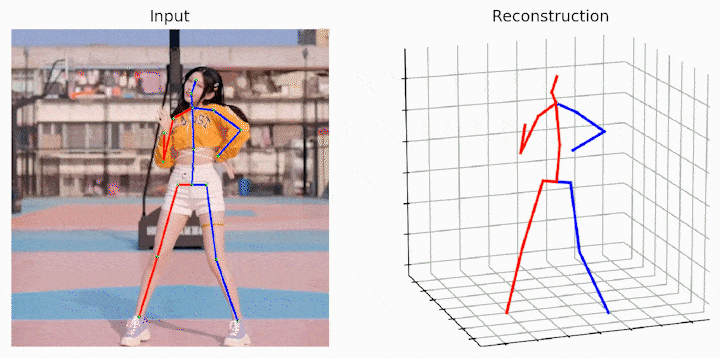
小结
本文针对三维人体姿态估计存在多个可行性解的逆问题,提出了一种来学习姿态假设多重表示的多假设Transformer的新方法。与大多数输出多个预测的方法不同,本文提出使用一对多对一的三阶段框架来有效地学习多假设的时空表示。它提高了每个假设的表示能力,同时也增强了多个假设之间的联系。大量实验表明,所提出的MHFormer与单假设Transformer相比具有巨大的提升,并在两个基准数据集上实现了最佳的性能。作者希望MHFormer能够促进2D到3D姿态姿态提升的进一步研究,同时考虑到各种歧义性。
公众号后台回复“CVPR2022”获取论文分类合集下载~
CV算法项目实践
极市打榜是极市平台推出的一种算法项目合作模式。参与打榜除可获得定额奖励外,还有机会与平台签约合作,持续获得算法的订单分成收益。平台支持已标注数据集+免费算力+群内技术答疑!
如果你想要获得真实的企业项目实践经验,或是希望获得一笔丰厚的副业收入,欢迎扫码了解&报名:


扫码查看(报名)40+算法打榜
备注“打榜”
进入打榜技术交流群



