【ACL2020-Google】BLEURT:一种基于迁移学习的自然语言生成度量

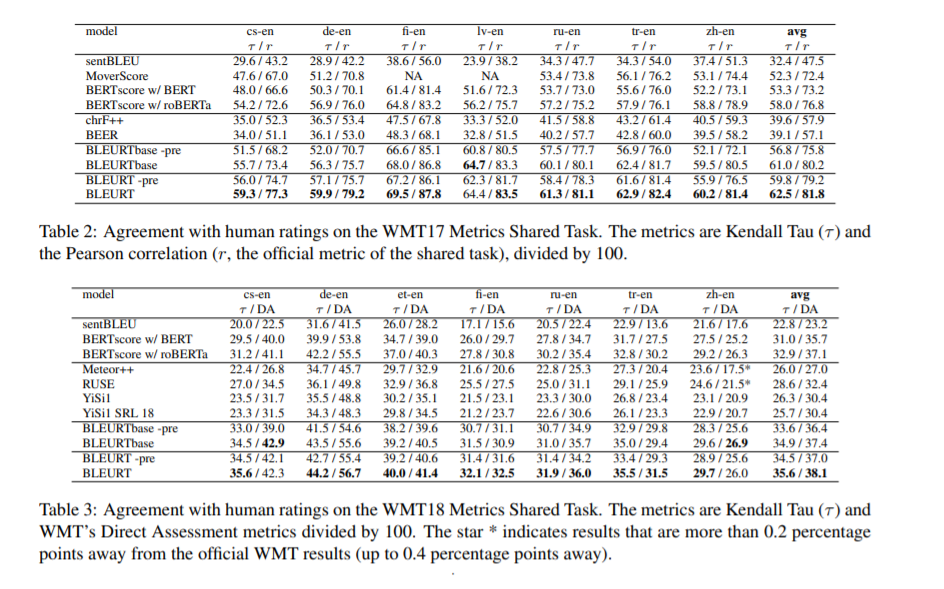
文本生成在过去几年中取得了重大进展。然而,评估指标却落后了,因为最流行的选择(如BLEU 和ROUGE)可能与人类的判断关系不大。我们提出了BLEURT,一种基于BERT的学习评价指标,它可以用几千个可能有偏见的训练例子来模拟人类的判断。我们的方法的一个关键方面是一个新的预训练方案,它使用了数百万的综合例子来帮助模型泛化。BLEURT提供了过去三年WMT指标共享任务和WebNLG竞赛数据集的最先进的结果。与基于普通BERT的方法相比,即使在训练数据稀少且分布不均匀的情况下,它也能产生更好的结果。
https://arxiv.org/abs/2004.04696
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“BLEURT” 可以获取《BLEURT:一种基于迁移学习的自然语言生成度量》专知下载链接索引



登录查看更多
相关内容
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
17+阅读 · 2020年4月10日
专知会员服务
28+阅读 · 2020年2月12日
Arxiv
20+阅读 · 2019年12月19日




相关VIP内容
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
17+阅读 · 2020年4月10日
专知会员服务
28+阅读 · 2020年2月12日
相关资讯
相关论文
Arxiv
20+阅读 · 2019年12月19日