机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文是CVPR 2020 公布的各奖项获奖论文,包括最佳论文和最佳学生论文等。
目录:
Knowledge Distillation: A Survey
Description Based Text Classification with Reinforcement Learning
Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
BSP-Net: Generating Compact Meshes via Binary Space Partitioning
Generative Pretraining from Pixels
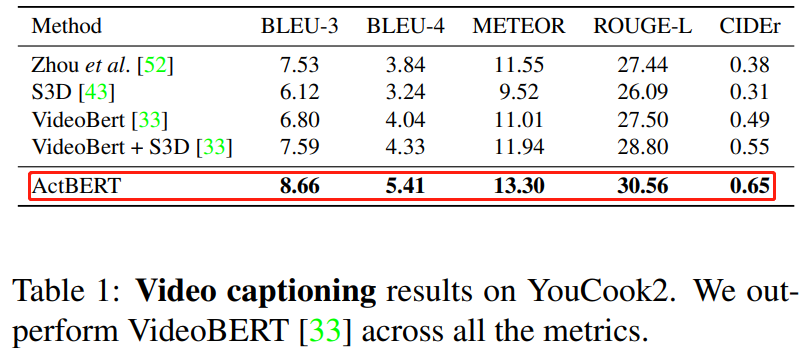
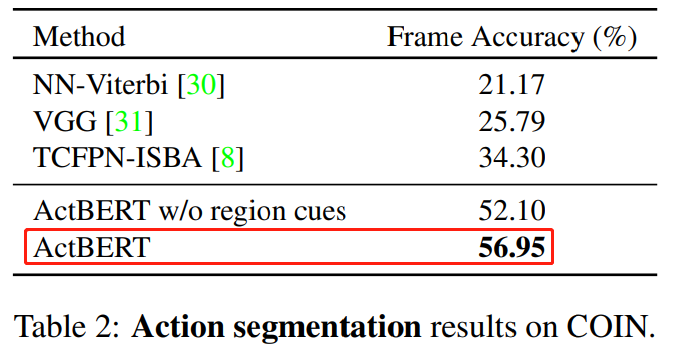
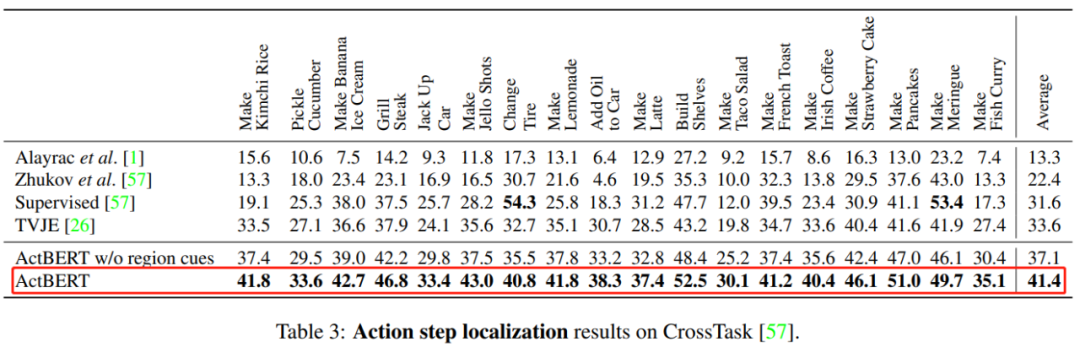
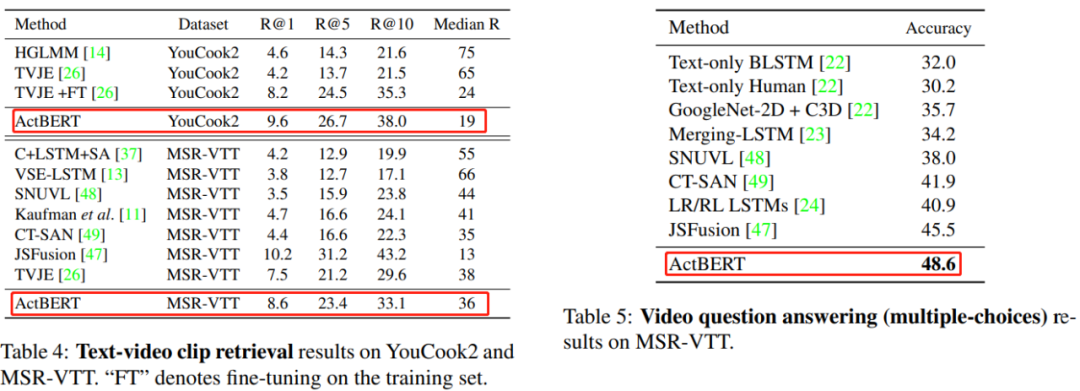
ActBERT: Learning Global-Local Video-Text Representations
A Survey on Dynamic Network Embedding
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
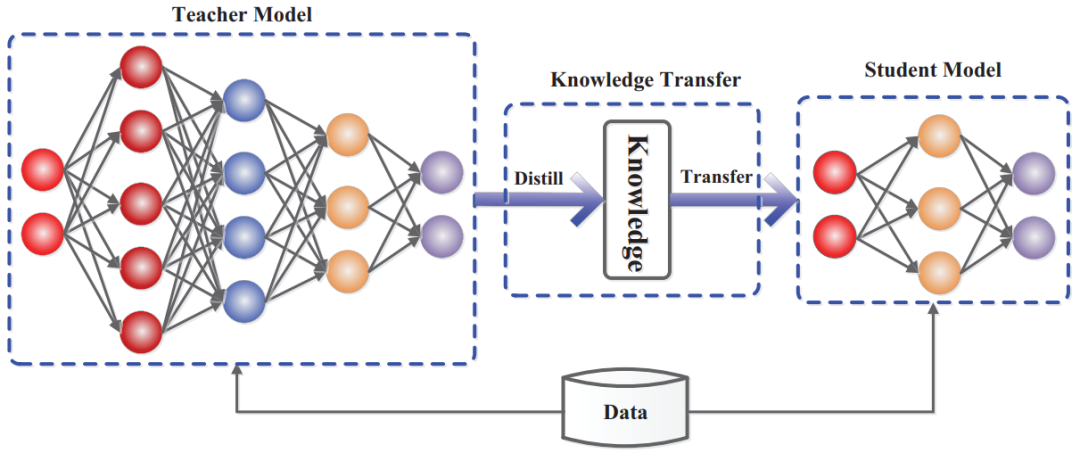
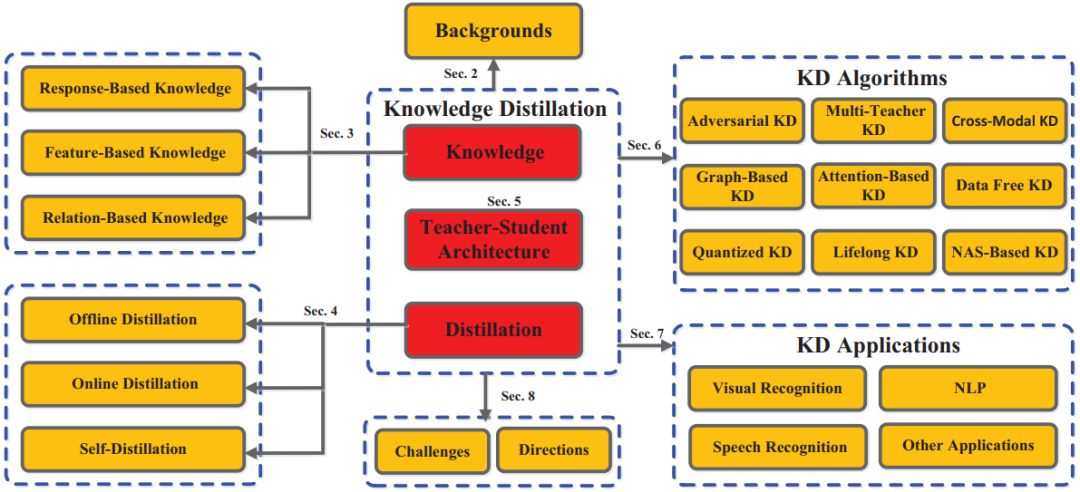
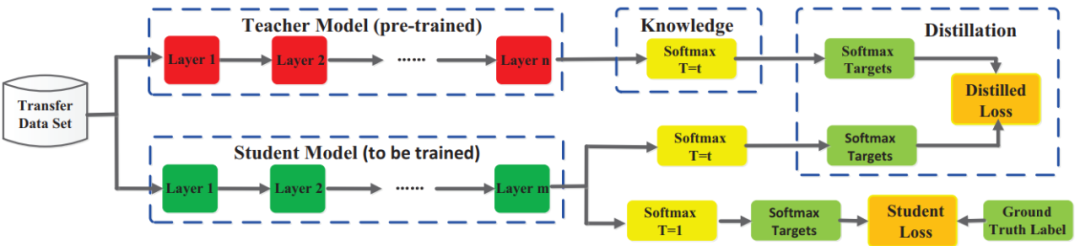
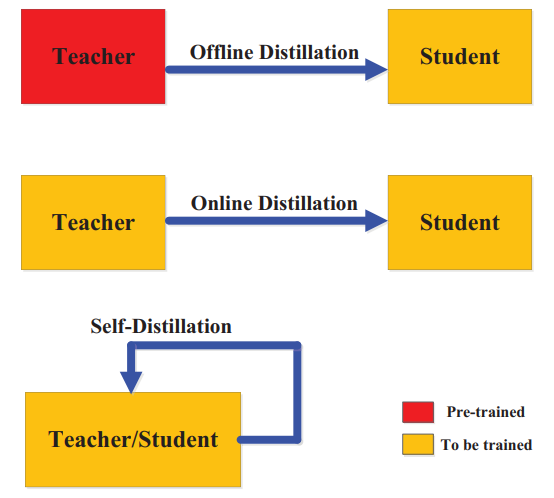
论文 1:Knowledge Distillation: A Survey
摘要:
近年来,深度神经网络在业界和学术界均取得了巨大成功,特别是在视觉识别和神经语言处理方面的应用。深度学习的巨大成功主要归功于自身强大的可扩展性,既有大规模的数据样本,也有数十亿的模型参数。但同时也应看到,在移动电话和嵌入式等资源有限的设备上部署这些笨重的深度模型也带来了巨大挑战,这不仅是因为计算量大,而且所需的存储空间也非常大。为了解决这些问题,研究人员开发了各种模型压缩和加速技术,如剪枝、量化和神经结构搜索。
知识蒸馏就是一种典型的模型压缩和加速方法,旨在从大教师模型中学习小学生模型,因而吸引了越来越多研究人员的关注。在本文中,
来自悉尼大学和伦敦大学伯贝克学院的研究者从知识分类、训练方案、知识提取算法以及应用等方面对知识蒸馏进行了综述
。此外,他们还简要回顾了知识蒸馏领域面临的挑战,并对未来的研究课题提供了一些见解。
![]()
![]()
![]()
![]()
推荐:
本文通讯作者为悉尼大学计算机科学教授陶大程(Dacheng Tao)。
论文 2:Description Based Text Classification with Reinforcement Learning
摘要:
文本分类任务通常分为两个阶段:文本特征提取和分类。在这种标准的规范化设置下,类别仅仅表示为标签词汇的索引,并且模型缺少对分类对象的显式说明。
因此,在当前通常将 NLP 问题形式化表示为问答任务的趋势启发下,
来自香侬科技和浙江大学的研究者提出了一种新颖的文本分类框架,其中每个类别标签与类别描述相互关联
。文本描述可以通过手动模板(handcrafted template)或者使用强化学习摘要式 / 提取式模型来生成。描述和文本的级联被馈入到分类器,以决定当前标签是否应该分类给文本。
研究者发现在单标签分类、多标签分类和多角度情感分析等一系列文本分类任务上,强基线方法的性能出现了大幅度提升。
![]()
通过不同策略建构的描述类型。文本来自 20news 数据集。
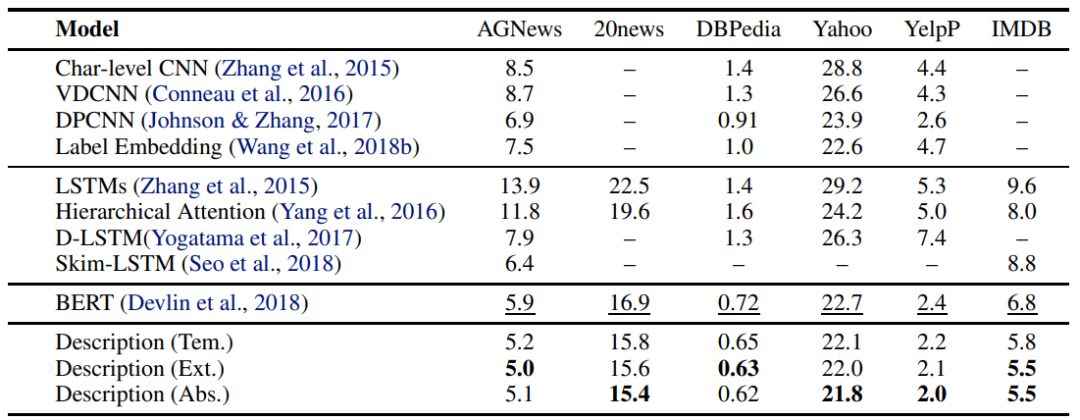
![]()
AGNews、20news、DBPedia、Yahoo、Yelp P 和 IMDB 数据集上单标签分类的测试误差率。
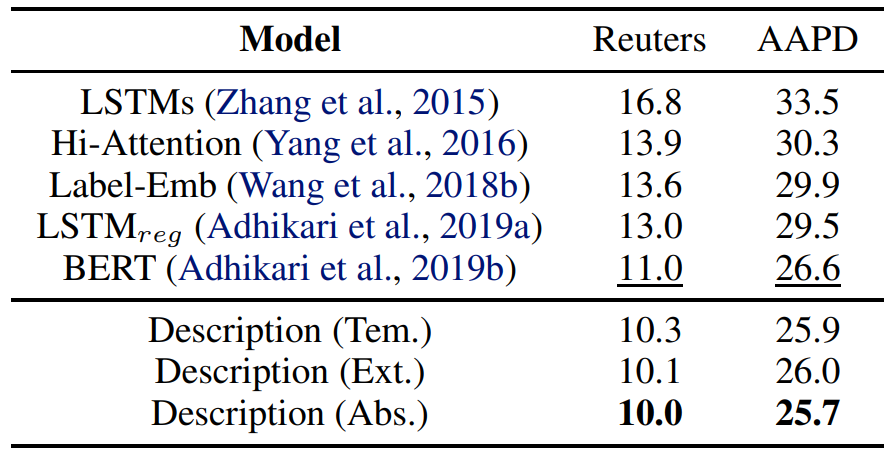
![]()
Reuters 和 AAPD 数据集上多标签分类的测试误差率。
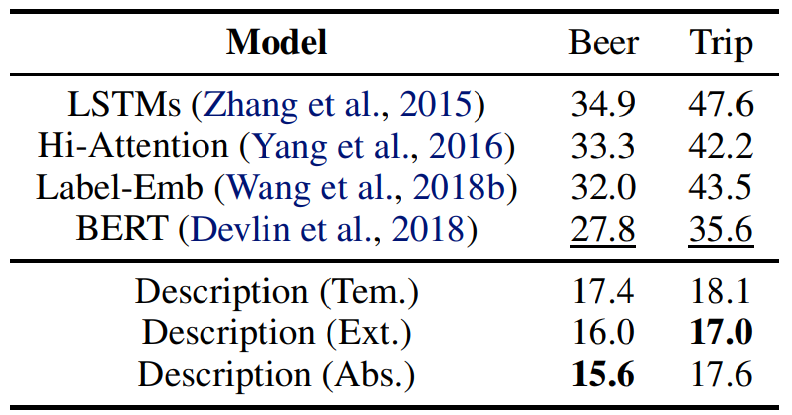
![]()
BeerAdvocate(Beer) 和 TripAdvisor(Trip) 数据集上多角度情感分类的测试误差率。
推荐:
本研究提出的策略使得模型与标签描述最相关的文本,可以视作注意力的硬版本(hard version),从而实现更佳性能。
论文 3:Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
摘要:
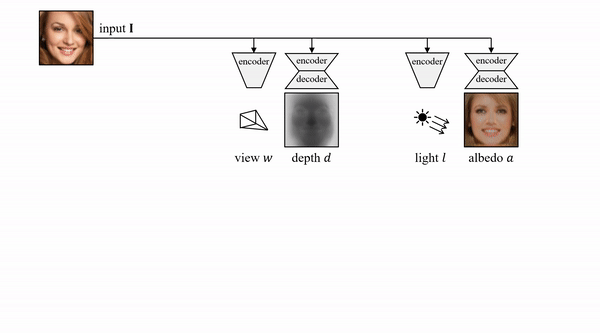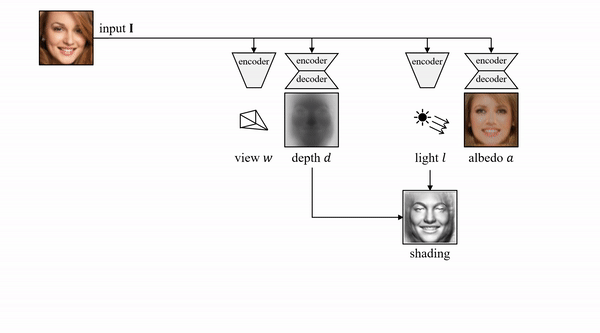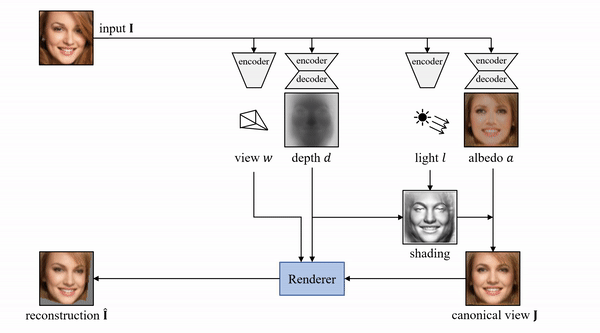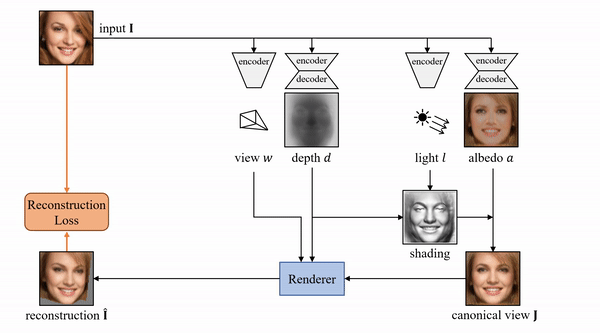
在这项研究中,
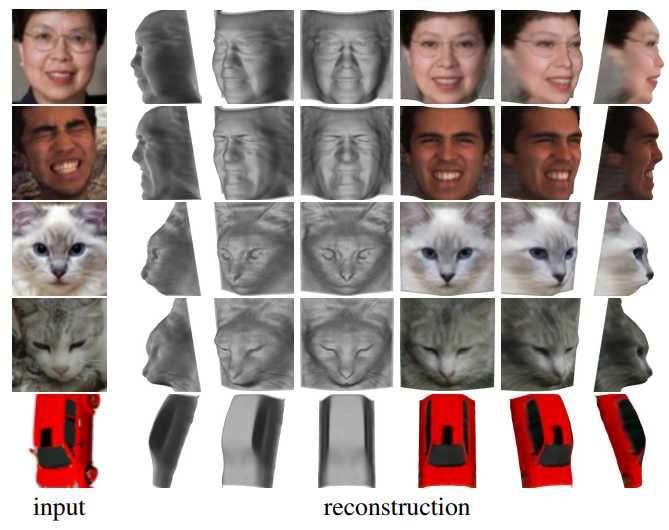
来自牛津大学的研究者提出了一种基于原始单目图像学习 3D 可变形物体类别的新方法,且无需外部监督
。该方法基于一个自编码器,它将每张输入图像分解为深度、反射率、视点和光照(将这四个组件结合起来即可重建输入图像)。该模型在训练过程中仅利用重建损失,未使用任何外部监督。为了在不使用监督信号的前提下将这些组件分解开,研究人员利用了很多物体类别所具备的属性——对称结构。
该研究表明,对光照进行推理可以帮助我们利用物体的底层对称性,即便由于阴影等因素造成物体外观看起来并不对称也没有关系。此外,该研究还使用模型其他组件以端到端的方式学得对称概率图,并借助对该概率图的预测对可能并不对称的物体进行建模。实验表明,该方法可以准确恢复单目图像中人脸、猫脸和车辆的 3D 形状,且无需任何监督或先验形状模型。相比于利用 2D 图像对应监督的另一种方法,该方法在基准数据集上的性能更加优越。
![]()
论文一作为吴尚哲(Shangzhe Wu),现为牛津大学博士二年级学生。
![]()
![]()
![]()
推荐:
本文获得了 CVPR 2020 最佳论文奖。
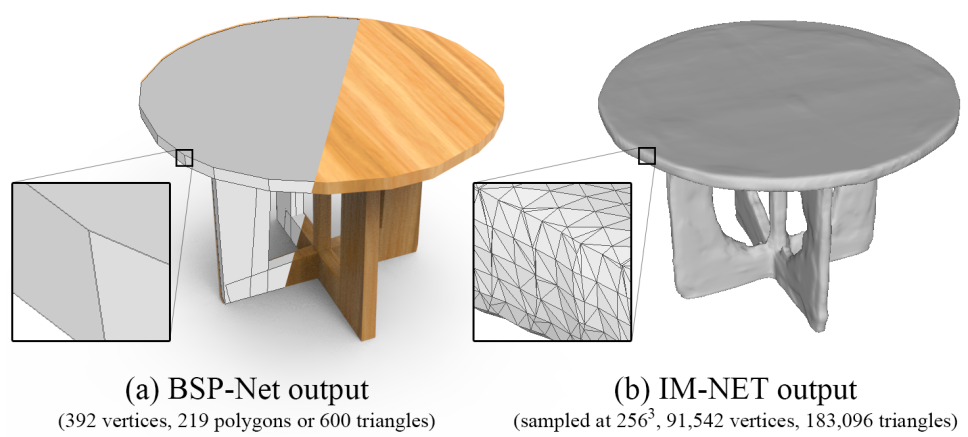
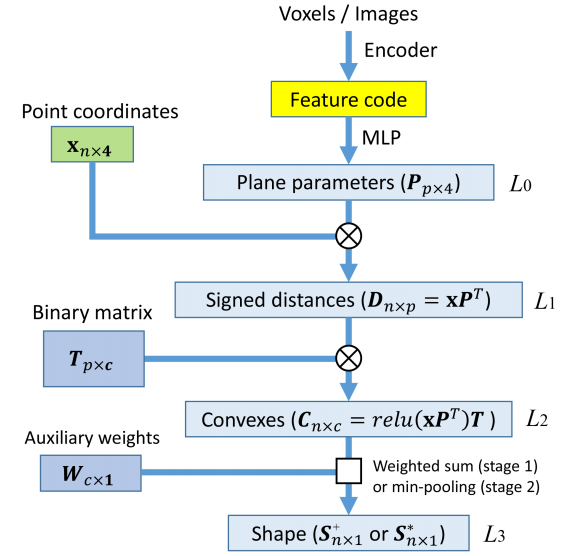
论文 4:BSP-Net: Generating Compact Meshes via Binary Space Partitioning
摘要:
多边形网格在数字 3D 领域中无处不在,但它们在深度学习革命中仅扮演了次要角色。学习形状生成模型的领先方法依赖于隐函数,并且只能在经过昂贵的等值曲面处理过程后才能生成网格。为了克服这些挑战,
来自西蒙弗雷泽大学和谷歌研究院的研究者受计算机图形学中经典空间数据结构 Binary Space Partitioning(BSP)的启发,来促进 3D 学习
。BSP 的核心部分是对空间进行递归细分以获得凸集。
利用这一属性,研究者设计了 BSP-Net,该网络可以通过凸分解来学习表示 3D 形状。重要的是,BSPNet 以无监督方式学得,因为训练过程中不需要凸形分解。该网络的训练目的是,为使用基于一组平面构建的 BSPtree 获得的一组凸面重构形状。经过 BSPNet 推断的凸面可被轻松提取以形成多边形网格,而无需进行等值曲面处理。生成的网格是紧凑的(即低多边形),非常适合表示尖锐的几何形状。此外,它们一定是水密网格,并且可以轻松参数化。
该研究还表明,BSP-Net 的重构质量和 SOTA 方法相比具备竞争力,且它使用的原语要少得多。
![]()
论文一作 Zhiqin Chen,现为西蒙弗雷泽大学博士一年级学生。
![]()
BSP-Net 与当前 SOTA 方法(IM-NET)的生成效果对比。
![]()
![]()
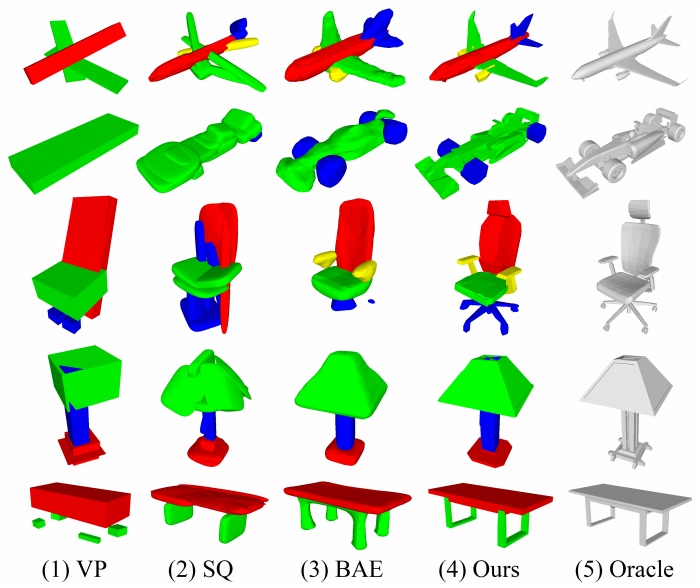
BSP-Net 与其他几种方法的分割和重建定性结果对比。
推荐:
本文获得了 CVPR 2020 最佳学生论文奖。
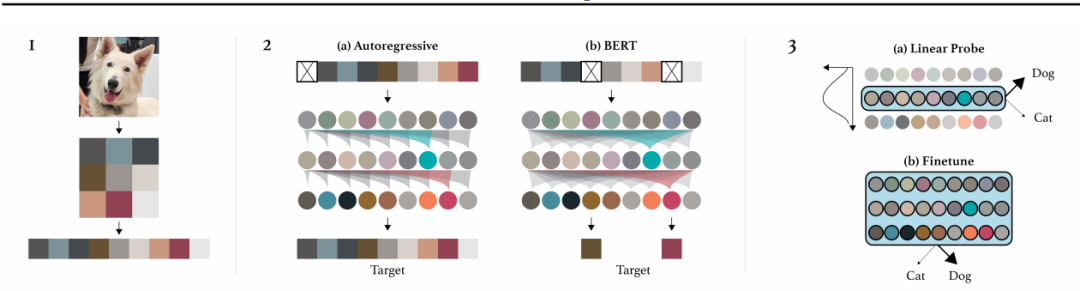
论文 5:Generative Pretraining from Pixels
摘要:
近日,
OpenAI 发布了一项新研究,旨在探索在图像上训练 GPT-2 的性能以及无监督准确率表现
。研究者表示,BERT 和 GPT-2 等 Transformer 模型是域不可知的,这意味着它们可以直接应用于任何形式的 1D 序列。OpenAI 研究者在图像上训练 GPT-2(这些图像被分解为长像素序列),他们称该模型称为 iGPT。结果发现这种模型似乎能够理解物体外观和类别等 2D 图像特征。iGPT 生成的各种一致性图像样本可以证明这一点,即使没有人为标签的指导。
iGPT 缘何能够成功呢?这是因为,在下一像素预测(next pixel prediction)上训练的足够大的 transformer 模型最终可能学会生成具有清晰可识别物体的样本。一旦学会了生成此类样本,那么通过「合成分析」,iGPT 将知道目标类别。实验表明,iGPT 模型的特征在大量的分类数据集上实现了当前 SOTA 性能,以及在 ImageNet 数据集上实现了接近 SOTA 的无监督准确率。
![]()
![]()
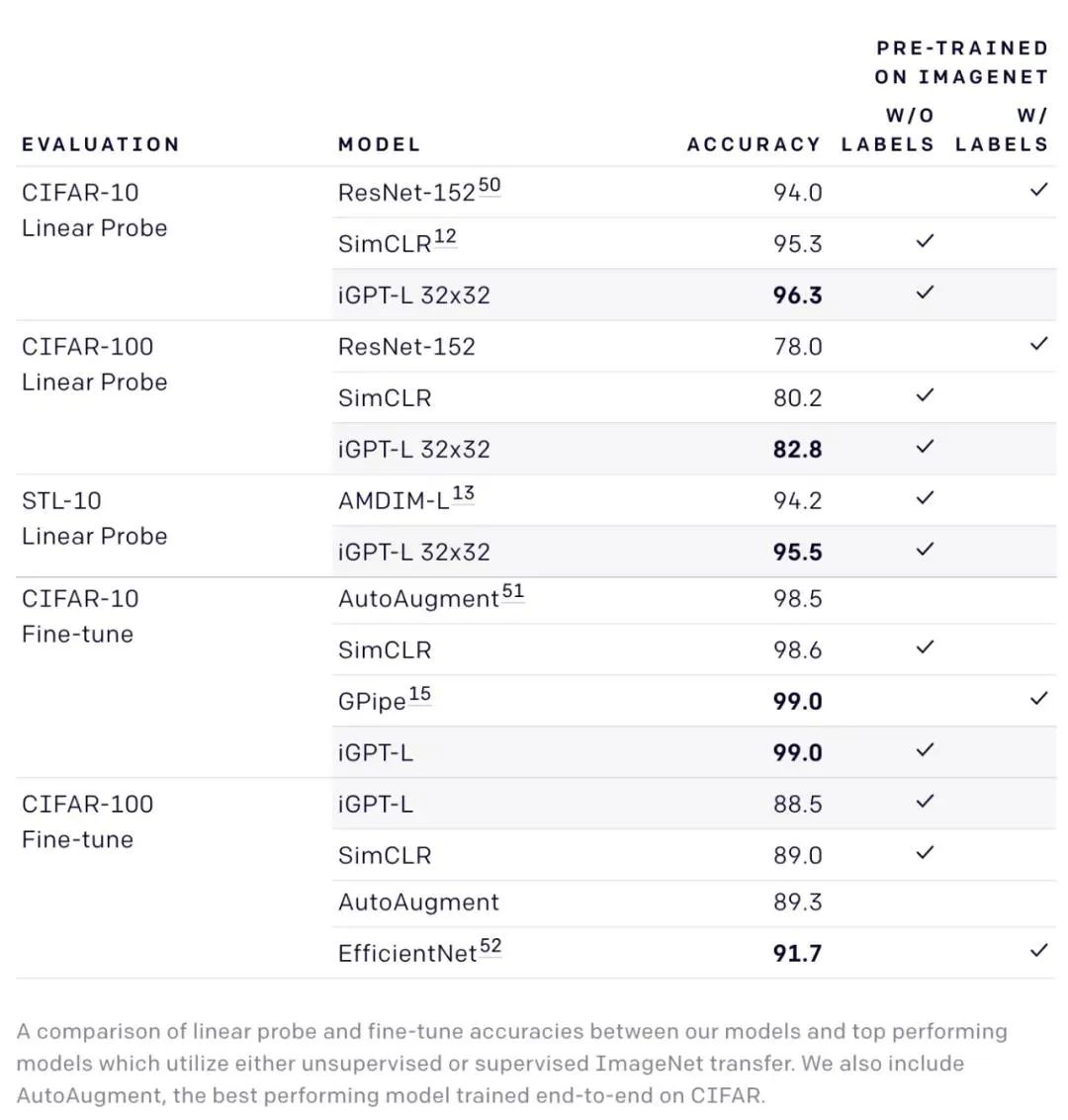
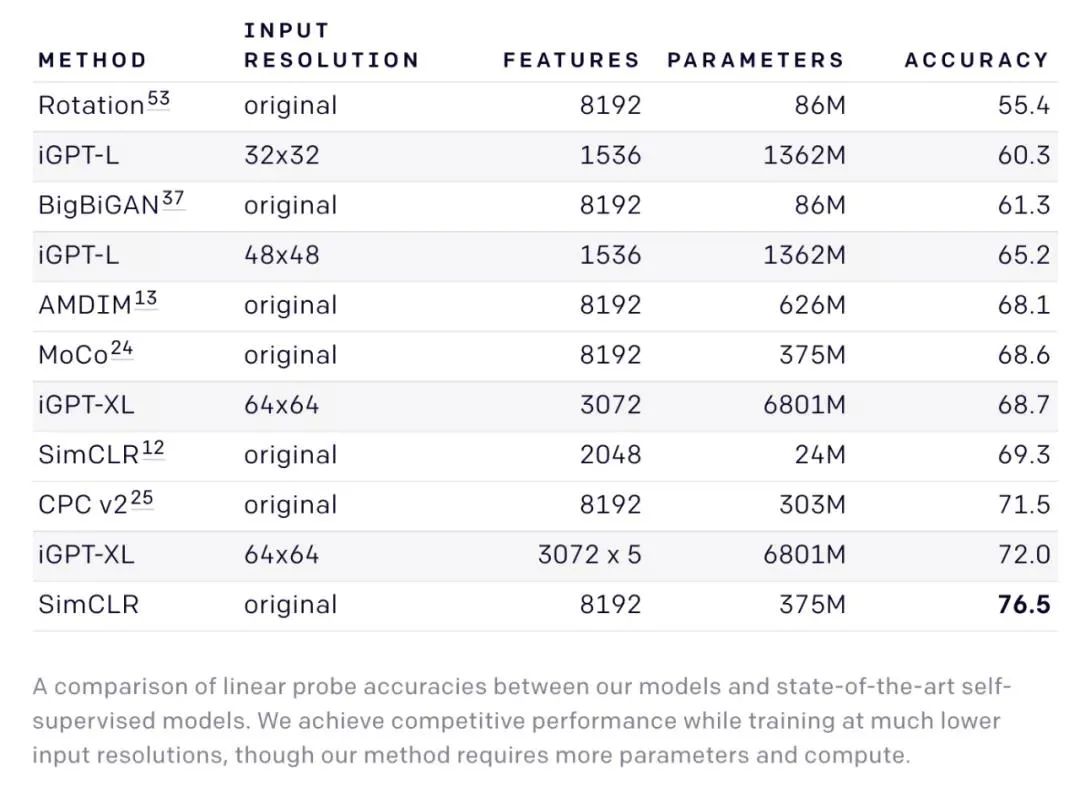
研究者评估了不同模型使用 linear probe 在 CIFAR-10、CIFAR-100 和 STL-10 数据集上的性能,发现该研究提出的方法优于其他监督和无监督迁移算法。甚至在完全微调的设置下,iGPT 的性能仍具备竞争力。
![]()
iGPT 和当前最优自监督模型的 linear probe 准确率对比情况。
![]()
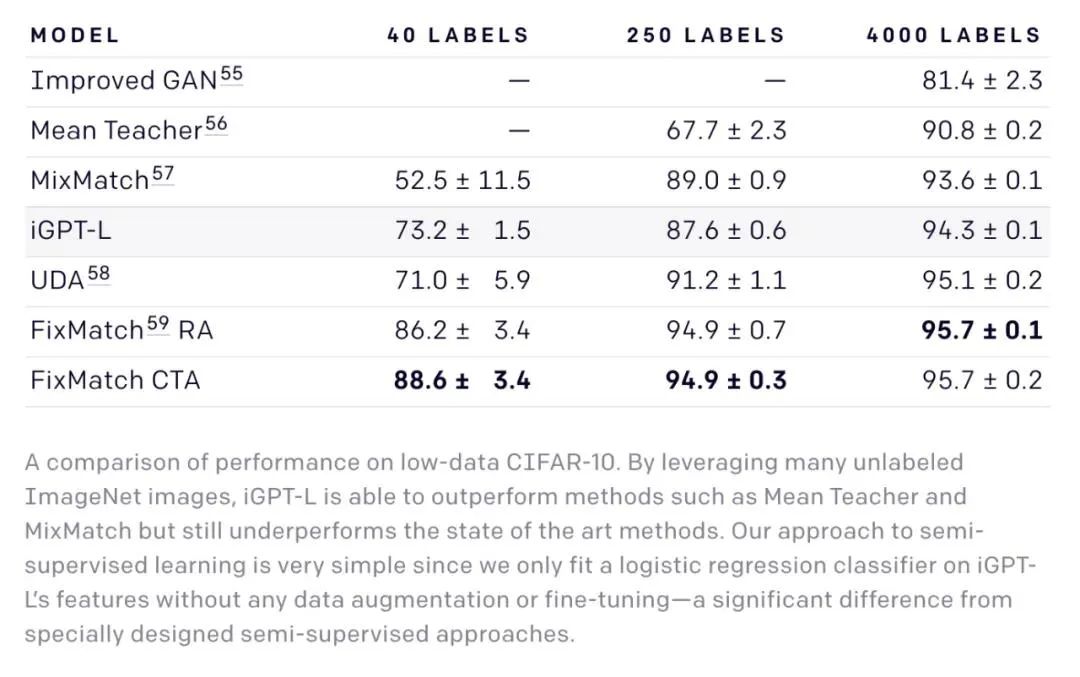
研究者在低数据 CIFAR-10 数据集上对 iGPT-L 进行了评估,结果发现基于非增强图像特征的简单 linear probe 表现优于 Mean Teacher 和 MixMatch,但弱于 FixMatch。
论文 6:ActBERT: Learning Global-Local Video-Text Representations
摘要:
在本文中,
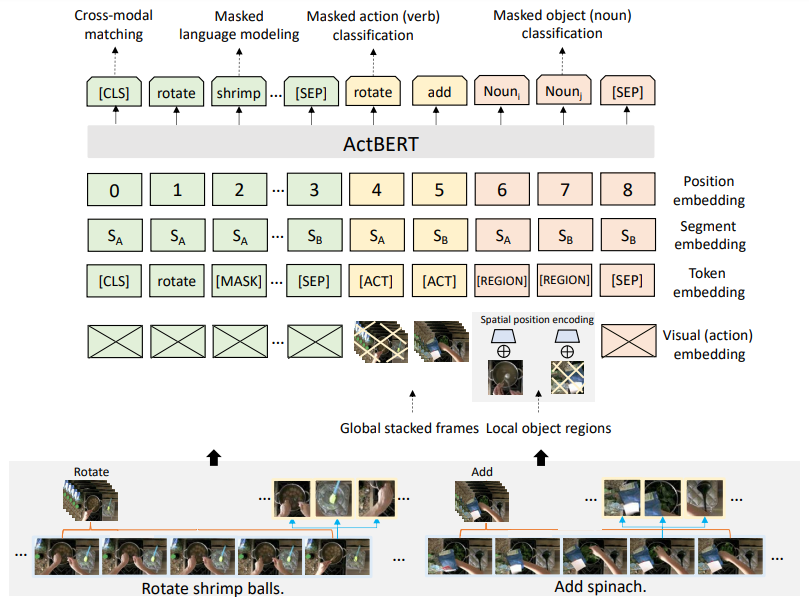
来自百度研究院和悉尼科技大学的研究者提出 ActBERT 从配对视频序列中挖掘全局和局部视觉线索和文字描述,它利用丰富的上下文信息和细粒度的关系进行视频 - 文本联合建模
,其贡献有以下三点:
首先,ActBERT 整合了全局动作,局部区域与文本描述。诸如「剪切」、「切片」之类的动作对于各种视频相关的下游任务是有益处的。除了全局动作信息,结合本地区域信息以提供细粒度的视觉提示,区域提供有关整个场景的详细视觉线索,包括区域对象特征,对象的位置。语言模型可以从区域信息中受益以获得更好的语言和视觉一致性;
其次,纠缠编码器模块对来自三个要素进行编码,即全局动作,局部区域和语言描述。新的纠缠编码模块从三个来源进行多模态特征学习,以增强两个视觉提示和语言之间的互动功能。在全局动作信息的指导下,对语言模型注入了视觉信息,并将语言信息整合到视觉模型中。纠缠编码器动态选择合适的上下文以促进目标预测;
最后,提出四个训练任务来学习 ActBERT。预训练后的 ActBERT 被转移到五个与视频相关的下游任务,并定量地显示 ActBERT 达到了最先进的性能。
![]()
![]()
![]()
![]()
![]()
左:YouCook2 和 MSR-VTT 数据集上的文本 - 视频片段检索结果;右:MSR-VTT 数据集上的视频问答(多选择)结果。
推荐:
该框架刷新五项 SOTA,充分展示了其在视频文本表示方面的学习能力。
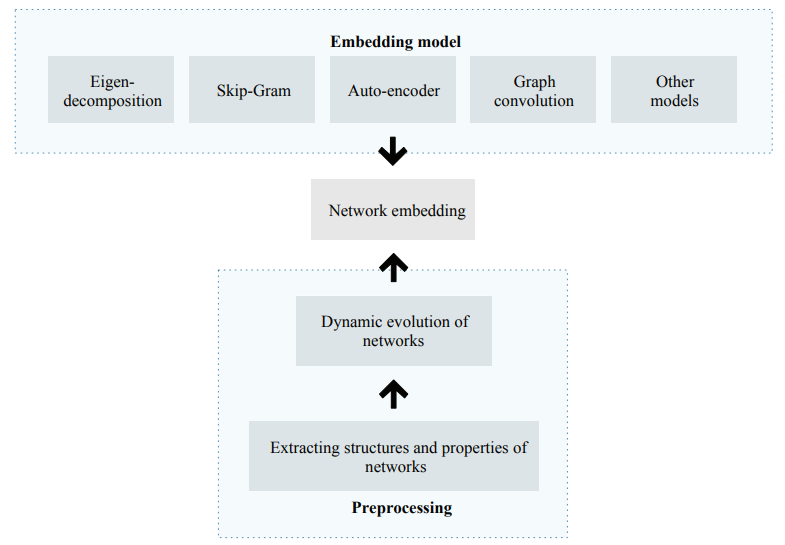
论文 7:A Survey on Dynamic Network Embedding
摘要:在本文中,
来自西安电子科技大学的研究者对动态网络嵌入问题进行了系统的研究,其中重点介绍了动态网络嵌入的基本概念,并首次对现有动态网络嵌入技术进行了分类,包括基于矩阵分解、基于跳字模型、基于自编码器以及基于神经网络等嵌入方法
。
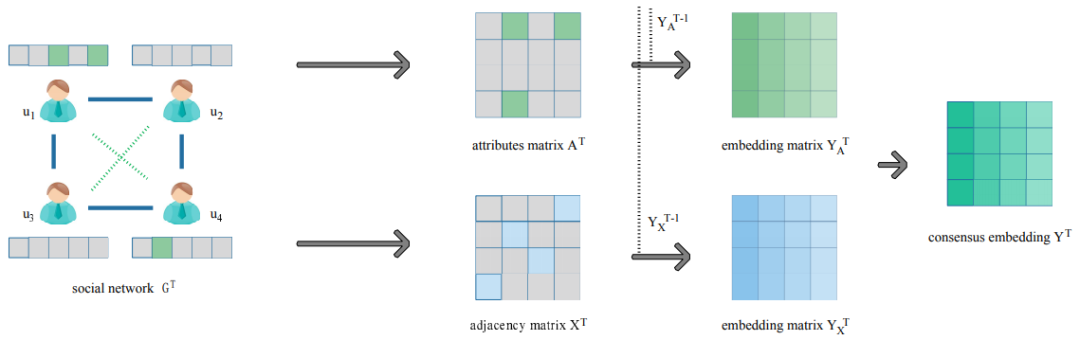
此外,研究者详细汇总了一些常用的数据集以及动态网络嵌入可以发挥积极作用的后续任务。在此基础上,他们提出了现有算法面临的一些挑战,并列举了可能促进未来研究的发展方向,如动态嵌入模型、大规模动态网络、异构动态
![]()
动态网络嵌入由两部分组成,分别是嵌入模型和预处理流程。
![]()
![]()
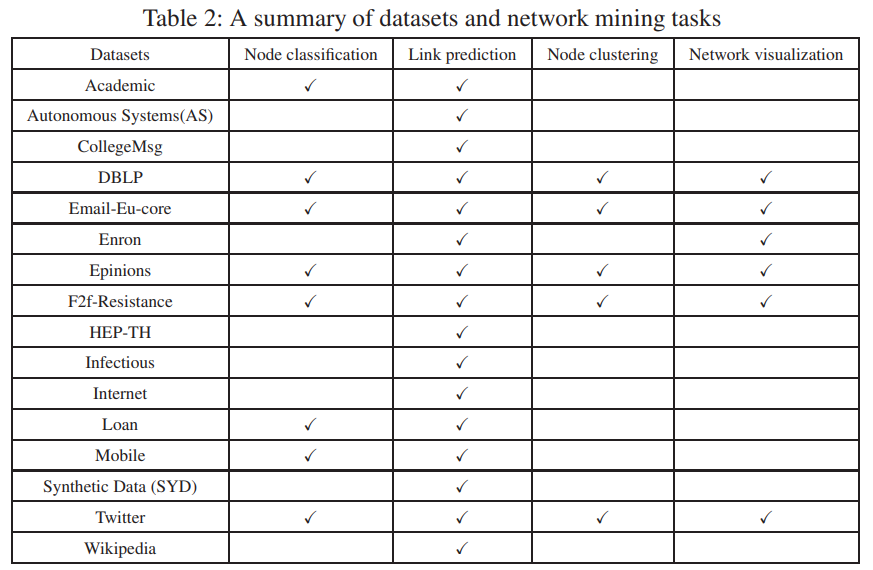
在动态网络嵌入实验中执行各种网络挖掘任务的数据集。
推荐:
本文的亮点在于,研究者提出了 6 个有趣且有前景的未来研究方向。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Octet: Online Catalog Taxonomy Enrichment with Self-Supervision. (from Yuning Mao, Tong Zhao, Andrey Kan, Chenwei Zhang, Xin Luna Dong, Christos Faloutsos, Jiawei Han)
2. On the Learnability of Concepts: With Applications to Comparing Word Embedding Algorithms. (from Adam Sutton, Nello Cristianini)
3. The Role of Verb Semantics in Hungarian Verb-Object Order. (from Dorottya Demszky, László Kálmán, Dan Jurafsky, Beth Levin)
4. Building Low-Resource NER Models Using Non-Speaker Annotation. (from Tatiana Tsygankova, Francesca Marini, Stephen Mayhew, Dan Roth)
5. Multi-branch Attentive Transformer. (from Yang Fan, Shufang Xie, Yingce Xia, Lijun Wu, Tao Qin, Xiang-Yang Li, Tie-Yan Liu)
6. Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation. (from Jungo Kasai, Nikolaos Pappas, Hao Peng, James Cross, Noah A. Smith)
7. AMALGUM -- A Free, Balanced, Multilayer English Web Corpus. (from Luke Gessler, Siyao Peng, Yang Liu, Yilun Zhu, Shabnam Behzad, Amir Zeldes)
8. Communicative need modulates competition in language change. (from Andres Karjus, Richard A. Blythe, Simon Kirby, Kenny Smith)
9. Modeling Graph Structure via Relative Position for Better Text Generation from Knowledge Graphs. (from Martin Schmitt, Leonardo F. R. Ribeiro, Philipp Dufter, Iryna Gurevych, Hinrich Schütze)
10. How to Probe Sentence Embeddings in Low-Resource Languages: On Structural Design Choices for Probing Task Evaluation. (from Steffen Eger, Johannes Daxenberger, Iryna Gurevych)
1. LSD-C: Linearly Separable Deep Clusters. (from Sylvestre-Alvise Rebuffi, Sebastien Ehrhardt, Kai Han, Andrea Vedaldi, Andrew Zisserman)
2. Rethinking Sampling in 3D Point Cloud Generative Adversarial Networks. (from He Wang, Zetian Jiang, Li Yi, Kaichun Mo, Hao Su, Leonidas J. Guibas)
3. Diverse Image Generation via Self-Conditioned GANs. (from Steven Liu, Tongzhou Wang, David Bau, Jun-Yan Zhu, Antonio Torralba)
4. AVLnet: Learning Audio-Visual Language Representations from Instructional Videos. (from Andrew Rouditchenko, Angie Boggust, David Harwath, Dhiraj Joshi, Samuel Thomas, Kartik Audhkhasi, Rogerio Feris, Brian Kingsbury, Michael Picheny, Antonio Torralba, James Glass)
5. Self-supervised Knowledge Distillation for Few-shot Learning. (from Jathushan Rajasegaran, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Mubarak Shah)
6. Learning Visual Commonsense for Robust Scene Graph Generation. (from Alireza Zareian, Haoxuan You, Zhecan Wang, Shih-Fu Chang)
7. Branch-Cooperative OSNet for Person Re-Identification. (from Lei Zhang, Xiaofu Wu, Suofei Zhang, Zirui Yin)
8. Rethinking Pre-training and Self-training. (from Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin D. Cubuk, Quoc V. Le)
9. Progressive Skeletonization: Trimming more fat from a network at initialization. (from Pau de Jorge, Amartya Sanyal, Harkirat S. Behl, Philip H.S. Torr, Gregory Rogez, Puneet K. Dokania)
10. Neural Graphics Pipeline for Controllable Image Generation. (from Xuelin Chen, Daniel Cohen-Or, Baoquan Chen, Niloy J. Mitra)
1. Algorithmic recourse under imperfect causal knowledge: a probabilistic approach. (from Amir-Hossein Karimi, Julius von Kügelgen, Bernhard Schölkopf, Isabel Valera)
2. A Study of Compositional Generalization in Neural Models. (from Tim Klinger, Dhaval Adjodah, Vincent Marois, Josh Joseph, Matthew Riemer, Alex 'Sandy' Pentland, Murray Campbell)
3. Bandit-PAM: Almost Linear Time $k$-Medoids Clustering via Multi-Armed Bandits. (from Mo Tiwari, Martin Jinye Zhang, James Mayclin, Sebastian Thrun, Chris Piech, Ilan Shomorony)
4. Structured and Localized Image Restoration. (from Thomas Eboli, Alex Nowak-Vila, Jian Sun, Francis Bach, Jean Ponce, Alessandro Rudi)
5. Measuring Model Complexity of Neural Networks with Curve Activation Functions. (from Xia Hu, Weiqing Liu, Jiang Bian, Jian Pei)
6. Fully Test-time Adaptation by Entropy Minimization. (from Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, Trevor Darrell)
7. Learning to Track Dynamic Targets in Partially Known Environments. (from Heejin Jeong, Hamed Hassani, Manfred Morari, Daniel D. Lee, George J. Pappas)
8. Communication-Efficient Robust Federated Learning Over Heterogeneous Datasets. (from Yanjie Dong, Georgios B. Giannakis, Tianyi Chen, Julian Cheng, Md. Jahangir Hossain, Victor C. M. Leung)
9. The Clever Hans Effect in Anomaly Detection. (from Jacob Kauffmann, Lukas Ruff, Grégoire Montavon, Klaus-Robert Müller)
10. How Much Can I Trust You? -- Quantifying Uncertainties in Explaining Neural Networks. (from Kirill Bykov, Marina M.-C. Höhne, Klaus-Robert Müller, Shinichi Nakajima, Marius Kloft)
![]()