赛尔原创@AAAI 2021 | 纠结于联合学习中的建模方法?快来看看图网络显式建模!

论文名称:Co-GAT: A Co-Interactive Graph Attention Network for Dialog Act Recognition and Sentiment Classification 论文作者:覃立波、黎州扬、车万翔、倪旻恒、刘挺 原创作者:黎州扬 论文链接:https://arxiv.org/pdf/2010.00190.pdf 代码链接:https://github.com/RaleLee/Co-GAT 转载须标注出处:哈工大SCIR
1. 简介
1.1 研究背景与任务定义

图1 任务示例
1.2 研究动机

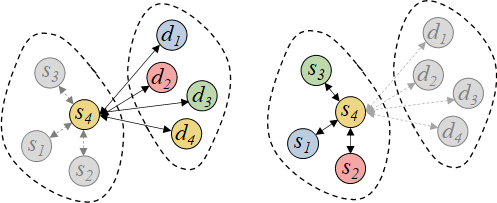
图3 前人工作示意
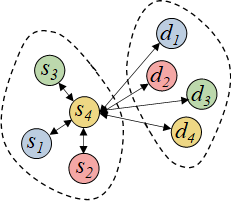
图4 Co-GAT示意
2. 模型
2.1 整体框架
2.2 Vanilla Graph Attention Network
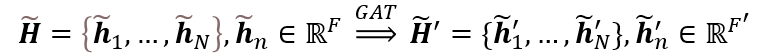
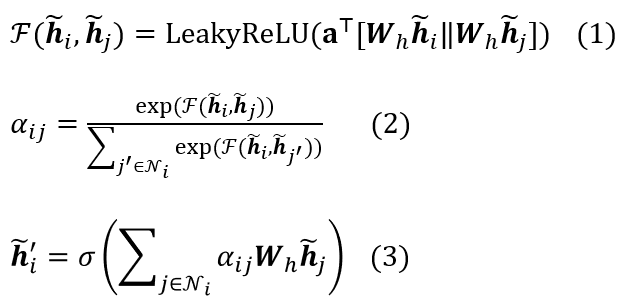
2.3 Hierarchical Speaker-Aware Encoder
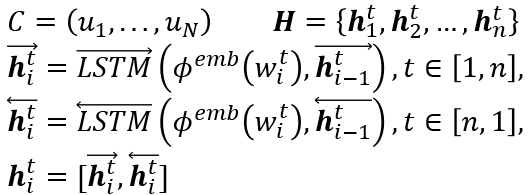
2.4 Co-Interactive Graph Layer
-
顶点:一共有2N个顶点,每个顶点对应一个句子表示。 -
N个顶点为情感分类任务的句子表示 -
N个顶点为对话行为识别任务的句子表示 -
边:一共有两种连接 -
跨语句连接。节点i连接上其同属一个任务的节点来获取上下文信息 -
跨任务连接。节点i连接上另一个任务的所有节点来获取相互交互信息
2.5 Decoder and Joint Training
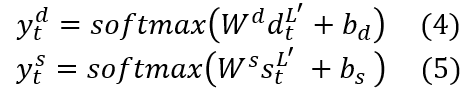
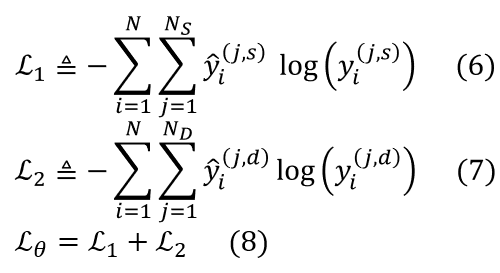
3. 实验
3.1 数据集
-
Dailydialog中, 训练集11,118个对话, 验证集1,000个对话,测试集1,000个对话 -
Mastodon中,训练集239个对话,测试集266个对话
3.2 主实验结果
表1 主实验结果
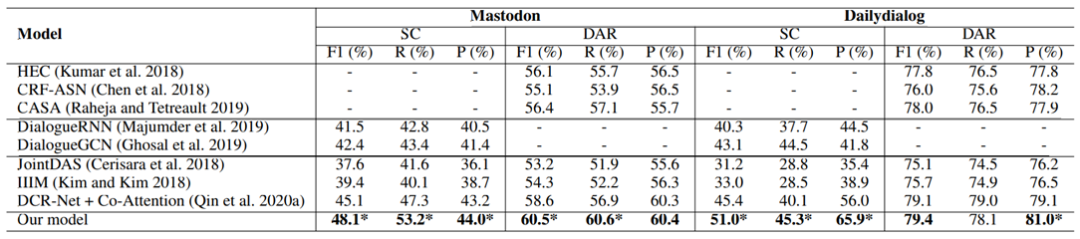
-
我们的实验结果在所有指标上超过了现有DAR和SC的单独建模的模型,这表明了我们联合建模中提取mutual interaction information的有效性。 -
我们的实验结果在所有指标上超过了现有的联合建模模型,这表明了将context information和mutual interaction information同时建模的有效性。
3.3 消融实验结果
表2 消融实验结果

-
without cross-tasks connection设置中,我们将cross-tasks connection去掉,来验证mutual interaction information的有效性。 -
without cross-utterances connection设置中,我们将cross-utterances connection去掉,来验证context information的有效性 -
separate modeling设置中,我们将co-interactive interaction layer去掉,使用两个单独的GAT建模两个任务,然后将两个模型的结果求和来表示交互,这表明了我们的co-interactive interaction layer能更好的同时获取两种信息。 -
co-attention mechanism设置中,我们用DCR-Net中的co-attention mechanism来替换我们的co-interactive interaction layer,表明了pipeline方法的劣势。 -
without speaker information设置中,我们去掉了hierarchical speaker-aware encoder中的speaker-aware graph,验证了合理的建模speaker的信息流可以帮助提高模型的效果。值得注意的是,在去掉该信息后,我们模型的结果依旧高于SOTA模型DCR-Net。
3.4 预训练模型探索实验
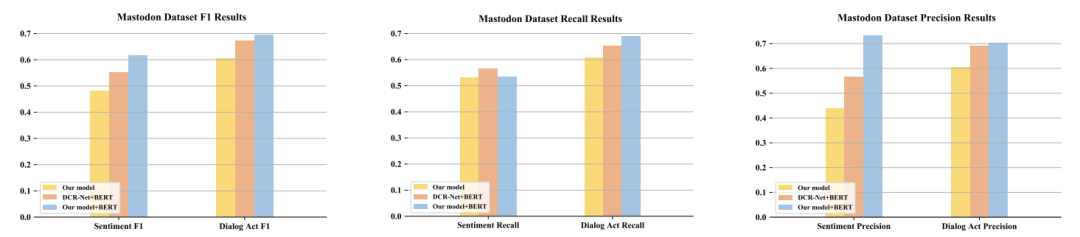
图6 BERT模型探索结果
表3 RoBERTa和XLNet探索结果
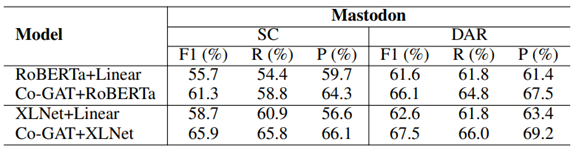
-
RoBERTa/XLNet+Linear是将RoBERTa/XLNet作为共享encoder,然后使用两个单独的线性层作为decoder获得预测结果。 -
Co-GAT+RoBERTa/XLNet是将RoBERTa/XLNet替换hierarchical speaker-aware encoder作为Encoder,保持我们的model剩余部分不变。
4.结论
-
我们首次尝试同时结合上下文信息和相互交互信息来进行联合对话行为识别和情感分类。 -
我们提出了一个协同交互的图注意力网络,该网络构造了交叉任务连接和交叉话语连接,并相互进行迭代更新,从而实现了同时结合上下文信息和交互信息的建模。 -
在两个公开数据集上进行的实验表明,我们的模型取得了实质性的改进,并实现了最佳的性能。此外,我们框架的贡献与预训练模型(BERT,Roberta,XLNet)是互补的。
参考文献
[1] Cerisara, C.; Jafaritazehjani, S.; Oluokun, A.; and Le, H. T. Multi-task dialog act and sentiment recognition on mastodon. In Proc. of COLING 2018.
[2] Kim, M.; and Kim, H. Integrated neural network model for identifying speech acts, predicators, and sentiments of dialogue utterances. Pattern Recognition Letters 2018.
[3] Libo Qin, Wanxiang Che, Yangming Li, Mingheng Ni, Ting Liu. DCR-Net: A Deep Co-Interactive Relation Network for Joint Dialog Act Recognition and Sentiment Classification. AAAI 2020.
[4] Veličković P, Cucurull G, Casanova A, et al. Graph attention networks. ICLR 2018.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



