【深度】用可组合的构建块丰富用户界面?谷歌提出「可解释性」的最新诠释

原文:distill
作者:Chris Olah、Arvind Satyanarayan、Ian Johnson、Shan Carter、Ludwig Schubert、Katherine Ye、Alexander Mordvintsev
来源:雷克世界
随着在神经网络领域不断取得新的发展成果,有一个相对应的需求也亟待解决,即能够对其决策进行解释,包括建立它们在现实世界中行为方式的置信度、检测模型偏差以及科学好奇心。为了做到这一点,我们需要构建深度抽象,并在丰富的界面中对它们进行修饰(或实例化)。可以说,除了极少数例外,现有的研究在关于可解释性这一点上并没有多少建树。
机器学习社区主要致力于开发功能强大的方法,如特征可视化、归因和降维,用于对神经网络进行解释和理解。然而,这些技术被当作孤立的研究线索进行研究,并且有关对它们进行修饰的研究也被忽略了。另一方面,人机交社区已经开始探索神经网络丰富的用户界面,但他们还没有对这些抽象概念进行更深入的研究。就这些抽象概念的使用程度而言,它已经是以相当标准的方式进行的了。结果,我们留下了很多并不实用的界面(例如显著图(saliency maps)或相关的抽象神经元),而将以一些有价值的东西遗弃了。更糟糕的是,许多可解释性技术还没有完全应用到抽象中,因为没有这样一种压力存在从而使它们成为可推广的或可组合的。
在本文中,我们将现有的可解释性方法视为丰富用户界面的基础和可组合性构建块。我们发现,这些不同的技术现在汇聚在一个统一的语法中,在最终的界面中实现互补角色。而且,这个语法使得我们能够系统性地对可解释性界面空间进行探索,使我们能够评估它们是否与特定的目标相符合。我们将展示一些界面,它们显示了网络所检测到的信息,并解释了网络是如何对其理解进行开发的,同时保持人类规模的大量信息。例如,我们将看到一个注视着拉布拉多猎犬的网络是如何检测到它松软的耳朵,以及它是如何影响其分类的。
在本文中,我们使用图像分类模型—GoogLeNet对我们的界面概念进行演示,因为它的神经元在语义上看起来异乎寻常。虽然在本文中我们已经对任务和网络进行了特定的选择,但我们提出的基本抽象和对它们进行组合的模式仍然可以应用于其他领域的神经网络。
理解隐藏层
近期关于可解释性的大部分研究都涉及神经网络的输入和输出层。可以说,之所以会出现这样的结果主要是由于这些层具有明确的含义:在计算机视觉中,输入层代表输入图像中每个像素的红色、绿色和蓝色信道的值,而输出层由类标签和他们相关的概率组成。
然而,神经网络的强大之处在于它们的隐藏层,在每一层,网络都会发现新的输入表示。在计算机视觉中,我们使用神经网络在图像中的每个位置运行相同的特征检测器。我们可以将每一层的已学习表示看作一个三维立方体。立方体中的每个单位都是一个激活,或者神经元的数量。x轴和y轴对应图像中的位置,z轴是正在运行的信道(或检测器)。
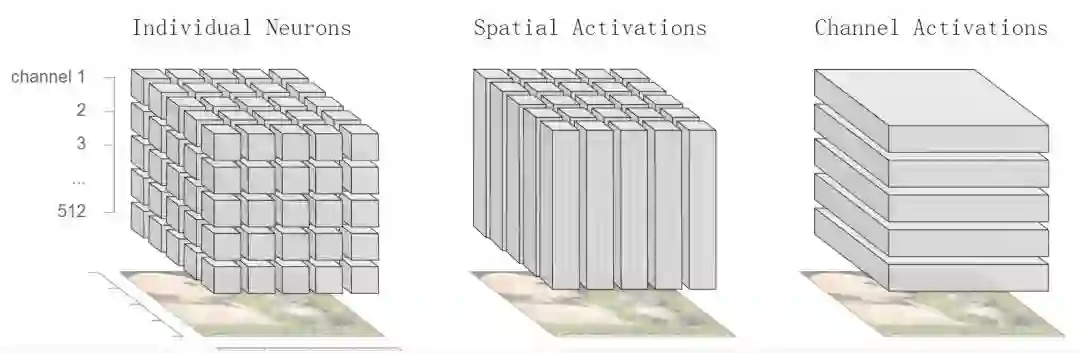
计算机视觉中神经网络每个隐藏层上所开发的的激活立方体,立方体的不同切片使得我们能够瞄准单个神经元、空间位置或信道的激活。
理解这些激活是很困难的,因为我们通常把它们当作抽象向量进行处理。
然而,通过特征可视化,我们可以将这个抽象向量转换成更有意义的“语义词典”(semantic dictionary)。
为了制作一个语义词典,我们将每个神经元激活与该神经元的可视化进行配对,并根据激活的大小对它们进行排序。激活与特征可视化的结合改变了我们与基础数学对象之间的关系。激活现在映射到图标的表示中,而不是抽象的索引中,其中很多表现形式类似于人类的创意,如“松软的耳朵”、“狗鼻子”或“皮毛”。
语义词典的强大之处不仅仅是在于它们摆脱了无意义的索引,还因为它们用典型的样本表达了神经网络的已学习抽象。通过图像分类,神经网络学习了一组视觉抽象,因此图像是用于表示它们的最为自然的符号。如果我们使用音频,那么更为自然的符号很可能是音频剪辑。这一点很重要,因为当神经元看起来符合人类的想法时,很容易将它们缩减为单词。但是,这样做是一项有损耗的操作,即使对于相似的抽象来说,网络也可能学到了更深层次的细微差别。例如,GoogLeNet中具有多个松软耳朵检测器,它们可以检测到耳朵的下垂度、长度和周围环境的细微差别。也有可能存在视觉上相似的抽象,但我们对其缺乏良好的自然语言描述:例如,在阳光打到水面时,拍摄特定的闪光灯柱。此外,网络可能会学习到对我们来说异乎寻常的新抽象概念,其中,自然语言会使我们完全失败!一般来说,相较于人类的语言来说,典型的样本是用来对神经网络所学习的外来抽象进行表示的一种更为自然的方式。
通过为隐藏层赋予意义,语义词典为我们现有的可解释性技术奠定了基础,使其成为可组合的构建块。就像它们的基础向量一样,我们可以对它们进行降维。在其他情况下,语义词典使得我们进一步推进这些技术的发展。例如,除了我们目前使用输入和输出层执行的单向归因(one-way attribution)外,语义词典还使得我们能够对特定的隐藏层进行属性转换。原则上,这项研究可以在没有语义词典的情况下完成,但是结果意味着什么还不清楚。
网络看到了什么?


用于检测松软的耳朵、狗鼻子、猫头、毛茸茸的腿和草的检测器。尽管有草地检测器,但效果不是很好。
语义词典为我们提供了一个关于激活的细粒度观察:每个单个神经元能够检测到什么?在这种表示的基础上,我们也可以将激活向量作为一个整体进行考虑。我们可以对给定空间位置处发射的神经元组合进行可视化,而不是对单个神经元进行可视化。(具体来说,我们对图像进行优化,以最大化激活点与原始激活向量的点积。)
将这种技术应用于所有的激活向量,使我们不仅可以看到网络在每个位置所检测到的内容,而且还可以了解网络对整个输入图像的理解程度。

而且,通过跨越层进行研究(例如“mixed3a”、“mixed4d”),我们可以观察网络的理解是如何演变的:从检测早期层中的边缘,到后者中更复杂的形状和对象部分。

MIXED3A
MIXED4A
然而,这些可视化忽略了一个关键信息:激活的大小。通过按照激活向量的大小对每个单位的面积进行缩放,我们可以指出网络在该位置所检测到的特征强度:

MIXED3A

MIXED4A
如何组装概念?
特征可视化有助于我们回答网络所检测到的内容是什么,但它并不能回答网络是如何对这些单独的片段进行组合以做出最后的决策,或者为什么做出这些决策。
归因(Attribution)是一组通过解释神经元之间的关系来回答这些问题的技术。有很多种归因方法,但到目前为止,似乎没有一个明确的正确答案。事实上,我们有理由认为我们目前的所有答案都不是完全正确的。我们认为有很多关于归因方法的重要研究,但就本文而言,关于归因的精确方法并不重要。我们使用一种相当简单的方法,关系的线性近似(linearly approximating the relationship),可以很容易地用任何其他技术替代。未来对归因的技术改进,理所当然地会对基于它们所构建的界面进行相应改善。
具有显著图的空间归因
最常见的归因界面称为显著图(saliency map,一种简单的热图,对引起输出分类的输入图像的像素进行突出显示。我们发现目前这种方法存在两个缺陷。
首先,不清楚单一像素是否是归因的基本单位。每个像素的含义与其他像素纠缠在一起,对于简单的可视转换(例如,亮度、对比度等)不具有鲁棒性,并且与输出类等高级概念有很大的距离。其次,传统的显著图是一种非常有限的界面类型,它们一次只显示一个类的归因,并且不允许你对单个点进行更深入地探究。由于它们没有明确处理隐藏层,因此很难全面探索其设计空间。
信道归因(channel attribution)
通过将归因应用于隐藏层的空间位置,显著图对我们的激活立方体进行彻底切割。。
切割立方体的另一种方法是通过信道而不是空间位置。这样做可以让我们执行信道归因:每个检测器对最终输出的贡献有多大?(这种方法类似于Kim等人所做的同时期研究工作,他们将归因与已学习的信道组合结合在一起)。
可解释性界面的空间
本文所介绍的界面思想将诸如特征可视化和归因等构建块结合在一起。将这些片段结合在一起不是一个任意的过程,而是遵循基于界面目标的结构。例如,如果界面强调网络所能识别的内容,则优先考虑它的理解如何进行发展的,或者专注于如何让事情按照人类规模进行发展。为了评估这些目标,并理解这种权衡,我们需要能够对可能的替代方案进行系统地考虑。
我们可以将界面视为各个元素的联合。
这些界面的可信度如何?
为了可解释性界面更加具有有效性,我们必须相信它们所告诉我们的故事。我们认为目前所使用的一系列构建模块存在两个问题。首先,在不同的输入图像中,神经元是否具有相对一致的含义,并且是否通过特征可视化进行准确地表示了呢?语义词典以及建立在它们之上的界面,都是以这个问题的真实性为前提的。其次,归因是否有意义,我们是否能够相信目前拥有的任何归因方法?
模型行为是非常复杂的,我们目前的构建模块只能使我们展示它的特定方面。未来可解释性研究的一个重要方向是开发能更广泛地覆盖模型行为的技术。但是,即使有了这些改进,我们也认为可靠性的关键标志将是不会误导的界面。与展示的显示信息交互不应导致用户隐含地绘制关于模型的不正确评估。毫无疑问,我们在这篇文章中所介绍的界面在这方面仍然有很大的改进空间。在机器学习和人机交互的交叉研究中,解决这些问题是很有必要的。
总结
存在着一个丰富的设计空间用于与枚举算法进行交互,而且我们相信与神经网络进行交互的空间也同样丰富。我们还有很多研究工作要做,以建立强大和值得信赖的可解释性界面。如果我们取得了成功,可解释性将成为一个强有力的工具,使我们能够实现有意义的人类监督,并建立公平、安全和一致的人工智能系统。
原文链接:https://distill.pub/2018/building-blocks/
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】综述论文:对抗攻击的12种攻击方法和15种防御方法
☞【学界】精准防御对抗性攻击,清华大学提出对抗正则化训练方法DeepDefense
☞【深度】Ian Goodfellow 强推:GAN 进展跟踪 10 大论文(附下载)
☞【学界】斯坦福联合DeepMind提出将「强化学习和模仿学习」相结合,可实现多样化机器人操作技能的学习



