结巴中文分词原理分析4
作者:白宁超,工学硕士,现工作于四川省计算机研究院,著有《自然语言处理理论与实战》一书,点击阅读原文可直达原文链接,作者公众号:机器学习和自然语言处理(公众号ID:datathinks)
安装结巴分词
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
通过 import jieba 来引用
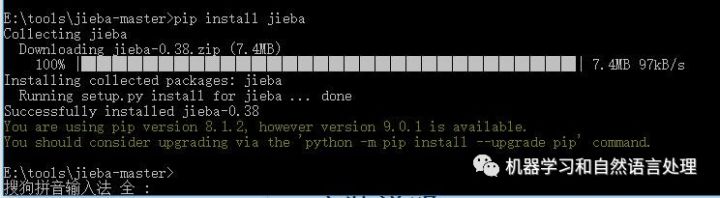
本机是win10 64位,已经安装了pip工具,关于pip下载安装(here),然后win+R,输入pip install jieba,效果如下:
本机是win10 64位,已经安装了pip工具,关于pip下载安装(here),然后win+R,输入pip install jieba,效果如下:
结巴几种模式下的分词操作:(以下默认已导入:import jieba)
(1)全模式分词:
|
结果分析:显然我的名字:白宁超,没有正确分词,这是因为全模式把句子中所有可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
(2)精确模式分词
|
结果分析:首先默认模式就是精确模式,即cut_all=False。这里很好的将“白宁超”划分为一个词。与全模式分词是有区别的。精确模式适合文本分析。
(3)默认精确模式分词
|
结果分析:此处杭研并没有在词典中,但是也被Viterbi算法识别出来了。实际上是基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法可以发现新词。也可以在自定义字典去收集新词。
(4)搜索引擎模式分词
|
结果分析:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
(5)繁体分词
|
(6)jieba.lcut全模式、精准模式、搜索引擎模式
>>> seg_list=jieba.lcut(str,cut_all=True,HMM=True)<br>>>> type(seg_list)<br><class 'list'><br>>>> seg_list<br>['我', '是', '白', '宁', '超', '来自', '博客', '博客园']<br>>>> print("Full Mode: " + "/ ".join(seg_list)) # 全模式隐马<br>Full Mode: 我/ 是/ 白/ 宁/ 超/ 来自/ 博客/ 博客园<br>>>> type("/ ".join(seg_list))<br><class 'str'> |
结果分析:显然调用jieba.lcut返回list类型,"/ ".join(seg_list)是将list转化为string类型。
(7)自定义分词器
|
结果分析:
首先对一段话分词处理:
|
此处“李小福“和“李铁军”都是人名,结果却分词“李小福”和“李铁”,而“军是”当做一个词处理,显然不对。我们可以将“李铁军”当着一个词加入自定义文本中:
|
结果显然经过自定义分词有所好转。而石墨/烯分词错误。
| 李小福/和/李铁军/是/创新办/主任/也/是/云计算/方面/的/专家/;/ /什么/是/八一双鹿/ /例如/我/输入/一个/带/“/韩玉赏鉴/”/的/标题/,/在/自定义词/库中/也/增加/了/此/词为/N/类/ /「/台中/」/正確/應該/不會/被/切開/。/mac/上/可/分出/「/石墨烯/」/;/此時/又/可以/分出/來/凱特琳/了/。 |
(8)词性标注
# 结果 ======================================== 李小福 / nr , 和 / c , 李铁军 / x , 是 / v , 创新办 / i , 主任 / b , 也 / d , 是 / v , 云计算 / x , 方面 / n , 的 / uj , 专家 / n , ; / x , / x , 什么 / r , 是 / v , 八一双鹿 / nz , / x , 例如 / v , 我 / r , 输入 / v , 一个 / m , 带 / v , “ / x , 韩玉赏鉴 / nz , ” / x , 的 / uj , 标题 / n , , / x , 在 / p , 自定义词 / n , 库中 / nrt , 也 / d , 增加 / v , 了 / ul , 此 / r , 词 / n , 为 / p , N / eng , 类 / q , / x , 「 / x , 台中 / s , 」 / x , 正確 / ad , 應該 / v , 不 / d , 會 / v , 被 / p , 切開 / ad , 。/ x , mac / eng , 上 / f , 可 / v , 分出 / v , 「 / x , 石墨烯 / x , 」 / x , ;/ x , 此時 / c , 又 / d , 可以 / c , 分出 / v , 來 / zg , 凱特琳 / x , 了 / ul , 。/ x , ======================================== easy_install/ /is/ /great python/ /的/正则表达式/是/好用/的 ======================================== |
结果分析:李小福 / nr , 李铁军 / x 都是名字,属于名词,而李铁军 / x显然词性不对,这是由于刚刚jieba.add_word('李铁军')时候,没有进行词性参数输入,我们看看jieba.add_word('李铁军')源码:
def add_word(self, word, freq=None, tag=None) |
运行结果:
======================================== 李小福 / nr , 和 / c , 李铁军 / nr , 是 / v , 创新办 / i , 主任 / b , 也 / d , 是 / v , 云计算 / x , 方面 / n , 的 / uj , 专家 / n , ; / x , / x , 什么 / r , 是 / v , 八一双鹿 / nz , / x , 例如 / v , 我 / r , 输入 / v , 一个 / m , 带 / v , “ / x , 韩玉赏鉴 / nz , ” / x , 的 / uj , 标题 / n , , / x , 在 / p , 自定义词 / n , 库中 / nrt , 也 / d , 增加 / v , 了 / ul , 此 / r , 词 / n , 为 / p , N / eng , 类 / q , / x , 「 / x , 台中 / s , 」 / x , 正確 / ad , 應該 / v , 不 / d , 會 / v , 被 / p , 切開 / ad , 。/ x , mac / eng , 上 / f , 可 / v , 分出 / v , 「 / x , 石墨烯 / x , 」 / x , ;/ x , 此時 / c , 又 / d , 可以 / c , 分出 / v , 來 / zg , 凱特琳 / x , 了 / ul , 。/ x , ======================================== |
(9) 自定义调整词典
|
结果分析:列表中的每一条数据如('今天天气不错', ('今天', '天气')),其中('今天', '天气')调整分词颗粒精度的。如第三句正常分词:我们/中/出/了/一个/叛徒。我们假设某些情况下一和个分别分词,可以做如上处理。
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
(10) 自定义调节词典解决歧义分词问题
|
总结:jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型。jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode)。
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
用法示例
|
原理和用法
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升。基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows。
用法:
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
jieba.disable_parallel() # 关闭并行分词模式
例子:https://github.com/fxsjy/jieba/blob/master/test/parallel/test_file.py
|
实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
注意:并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。
中文分词之HMM模型详解
HMM相关文章
结巴分词GitHub源码
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。
作者博客官网:
https://bainingchao.github.io/
作者公众号,欢迎关注:






