Jiagu:中文深度学习自然语言处理工具
推荐一个新的开源中文深度学习自然语言处理工具:Jiagu, 包括中文分词、词性标注、命名实体识别、情感分析、新词发现、关键词、文本摘要等。贡献者包括 Yener、zengbin93、dirtdust,感兴趣的同学可以试用,Github地址,点击文末阅读原文可直达:
https://github.com/ownthink/Jiagu
Jiagu自然语言处理工具
Jiagu以BiLSTM等模型为基础,使用大规模语料训练而成。将提供中文分词、词性标注、命名实体识别、关键词抽取、文本摘要、新词发现等常用自然语言处理功能。参考了各大工具优缺点制作,将Jiagu回馈给大家。
目录
安装方式
使用方式
评价标准
附录说明
提供的功能有:
中文分词
词性标注
命名实体识别
情感分析 todo
关键词提取
文本摘要
新词发现
等等。。。。
安装方式
pip安装
pip install jiagu
源码安装
git clone https://github.com/ownthink/Jiagucd Jiagu
python3 setup.py install
使用方式
快速上手:分词、词性标注、命名实体识别
import jiagu#jiagu.init() # 可手动初始化,也可以动态初始化text = '厦门明天会不会下雨'words = jiagu.seg(text) # 分词print(words) pos = jiagu.pos(words) # 词性标注print(pos) ner = jiagu.ner(text) # 命名实体识别print(ner)
中文分词
分词各种模式使用方式
import jiagu text = '汉服和服装'words = jiagu.seg(text) # 默认分词print(words) words = jiagu.seg([text, text, text], input='batch') # 批量分词,加快速度。print(words) words = jiagu.seg(text, model='mmseg') # 使用mmseg算法进行分词print(words)
自定义分词模型(将单独提供msr、pku、cnc等分词标准)
import jiagu# 独立标准模型路径# msr:test/extra_data/model/msr.model# pku:test/extra_data/model/pku.model# cnc:test/extra_data/model/cnc.modeljiagu.load_model('test/extra_data/model/cnc.model') # 使用国家语委分词标准words = jiagu.seg('结婚的和尚未结婚的')print(words)
关键词提取
import jiagu text = '''该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管中国和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。考虑到人口过多的国家一般存在对土地过度利用的问题,这个发现令人吃惊。”NASA埃姆斯研究中心的科学家拉玛·内曼尼(Rama Nemani)说,“这一长期数据能让我们深入分析地表绿化背后的影响因素。我们一开始以为,植被增加是由于更多二氧化碳排放,导致气候更加温暖、潮湿,适宜生长。”“MODIS的数据让我们能在非常小的尺度上理解这一现象,我们发现人类活动也作出了贡献。”NASA文章介绍,在中国为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。据观察者网过往报道,2017年我国全国共完成造林736.2万公顷、森林抚育830.2万公顷。其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。京津风沙源治理工程完成造林18.5万公顷。三北及长江流域等重点防护林体系工程完成造林99.1万公顷。完成国家储备林建设任务68万公顷。''' keywords = jiagu.keywords(text, 5) # 关键词print(keywords)
文本摘要
fin = open('input.txt', 'r') text = fin.read() fin.clone() summarize = jiagu.summarize(text, 3) # 摘要print(summarize)
新词发现
import jiagu jiagu.findword('input.txt', 'output.txt') # 根据文本,利用信息熵做新词发现。
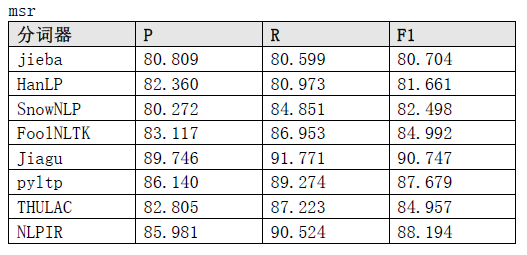
评价标准
msr测试结果
附录
词性标注说明
n 普通名词
nt 时间名词
nd 方位名词
nl 处所名词
nh 人名
nhf 姓
nhs 名
ns 地名
nn 族名
ni 机构名
nz 其他专名
v 动词
vd 趋向动词
vl 联系动词
vu 能愿动词
a 形容词
f 区别词
m 数词
q 量词
d 副词
r 代词
p 介词
c 连词
u 助词
e 叹词
o 拟声词
i 习用语
j 缩略语
h 前接成分
k 后接成分
g 语素字
x 非语素字
w 标点符号
ws 非汉字字符串
wu 其他未知的符号命名实体说明(采用BIO标记方式)
B-PER、I-PER 人名
B-LOC、I-LOC 地名
B-ORG、I-ORG 机构名
登录查看更多
相关内容

Arxiv
17+阅读 · 2020年6月2日
Arxiv
16+阅读 · 2019年12月16日
Arxiv
7+阅读 · 2019年2月3日



相关VIP内容
相关资讯
相关论文
Arxiv
17+阅读 · 2020年6月2日
Arxiv
16+阅读 · 2019年12月16日
Arxiv
7+阅读 · 2019年2月3日