移动端实时3D目标检测,谷歌开源出品,安卓下载就能用
作者:Adel Ahmadyan、Tingbo Hou
机器之心编译
机器之心编辑部
常规目标检测,已经不能满足移动端了,谷歌开源的 3D 实时目标检测了解一下?

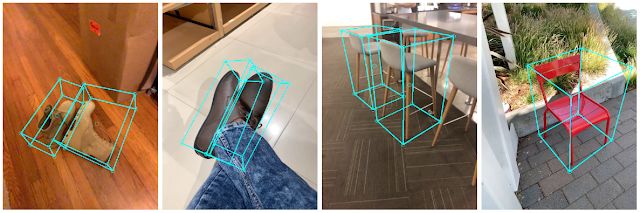


框架地址:https://github.com/google/mediapipe/
项目地址:https://github.com/google/mediapipe/blob/master/mediapipe/docs/objectron_mobile_gpu.md
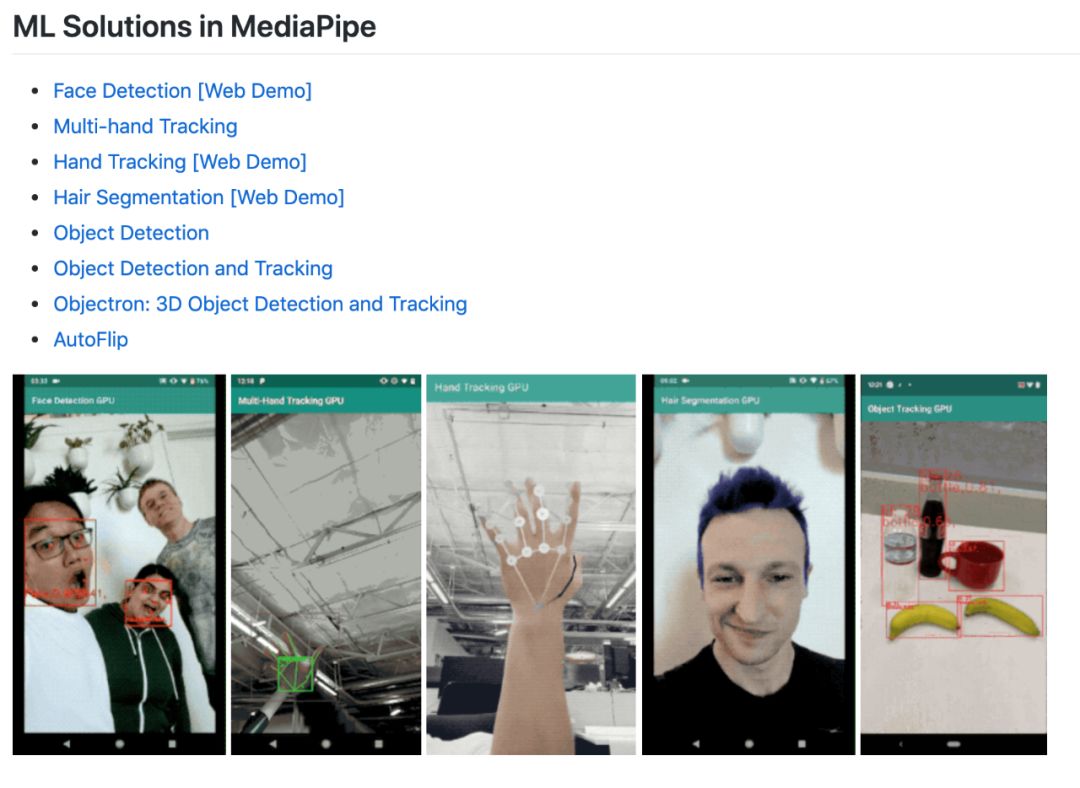
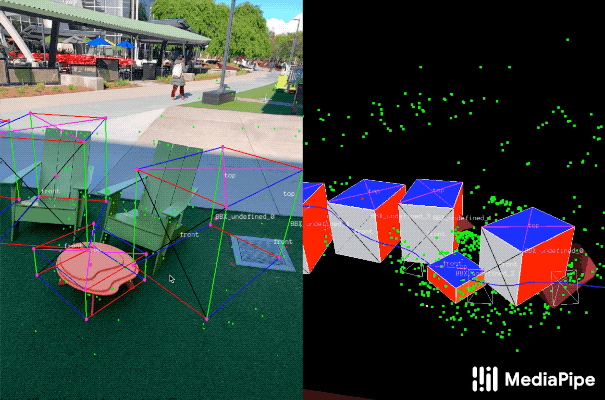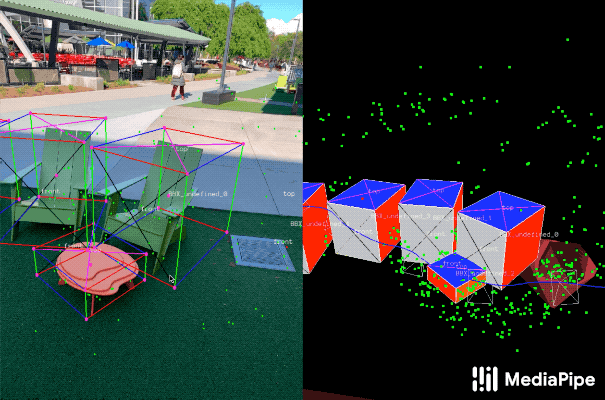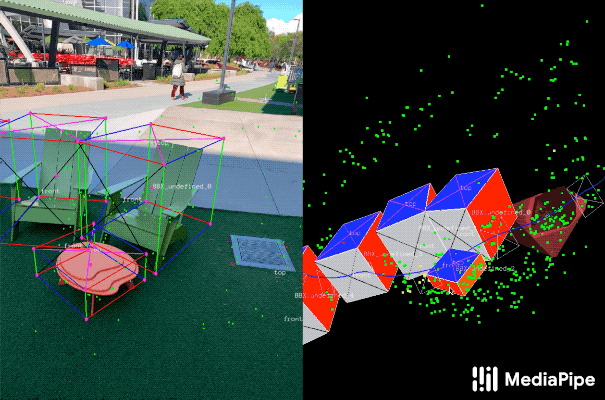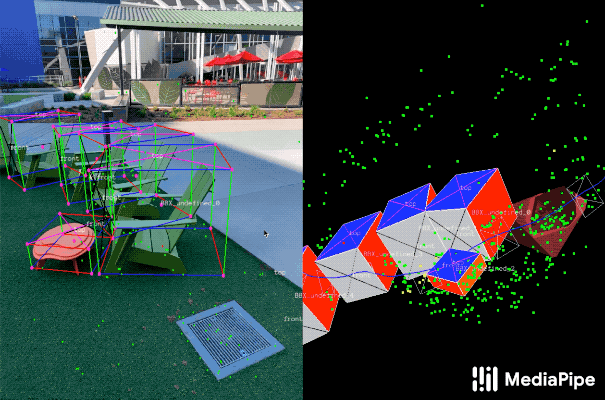

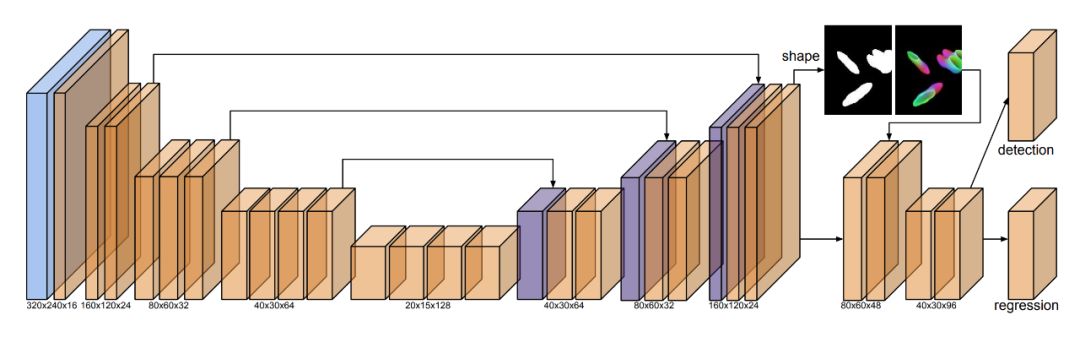
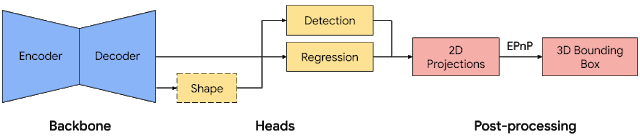


登录查看更多
相关内容
Arxiv
5+阅读 · 2019年9月26日
Arxiv
8+阅读 · 2018年2月21日
Arxiv
6+阅读 · 2018年1月28日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年9月26日
Arxiv
8+阅读 · 2018年2月21日
Arxiv
6+阅读 · 2018年1月28日