学界 | 弱监督视频物体识别新方法:香港科技大学联合CMU提出TD-Graph LSTM
选自arXiv
机器之心编译
参与:李泽南、路雪
在图像识别任务中,模型的训练一直非常依赖于标注数据,同时训练结果难以泛化。香港科技大学与卡耐基梅隆大学的研究者们最近发表的研究提出时间动态图 TD-Graph LSTM 试图解决这些问题,他们的新方法也刷新了视频目标检测的业内最佳水平。该论文已入选即将在 10 月底举行的 ICCV2017 大会。
随着数据驱动方式在图像识别上的不断发展,人们对于扩大目标检测系统规模的兴趣越来越大。然而,与分类任务不同,用不同的类与边界框完整标注对象实例的方法几乎是不可扩展的。因此,人们加大对无监督和弱监督的目标检测方法的探索力度,但现在,完全无监督、无标注的方法在类似任务中的性能表现很差,而常规弱监督方法则需要使用静态图像来训练检测器。这些目标检测器无法在转移域的情形下将良好表现泛化到视频处理中。一种替代方案是使用这些弱监督的方法,但是使用视频的帧来训练。然而,目前的方法在很大程度上依赖于图像级别标记的准确性,并且容易出现标记缺失(如图 1 所示)。
在香港科技大学与卡耐基梅隆大学共同发表的新论文中,研究人员探索了一种新的弱监督视频目标检测方式,它使用人类动作标签作为目标检测的监督学习内容。如下图所示,多个帧中粗略的人类动作标签(如看笔记本电脑或坐在椅子上)有助于指出有关的具体识别对象(如笔记本和椅子)。与之前的各类研究相比,新的方法有两个主要优点:1)通过视频的文字动作描述收集标签比通过文本标记、搜索查询和动作识别数据集 [32, 10, 36] 容易得多;2)视频固有的时间相干性为模型提供了更多线索,利于识别每个对象实例,并帮助克服标签丢失的问题。
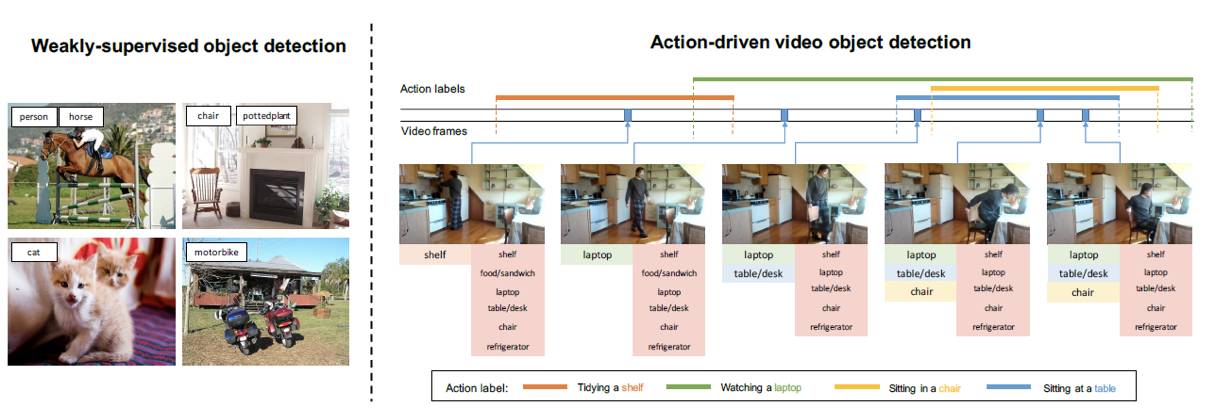
图 1. 左侧显示了传统的弱监督目标检测设置,每个训练图像都有关于对象类别的准确图像级标注;右侧是动作驱动弱监督视频目标检测设置。每个视频里都会出现视频级的动作标签,表明动作内容及其在视频中发生的时段(开始和结束)。对于每一帧,其左下方的对象类别是动作标签中的参与对象,而右下方的对象类别则是每一帧中的所有对象。
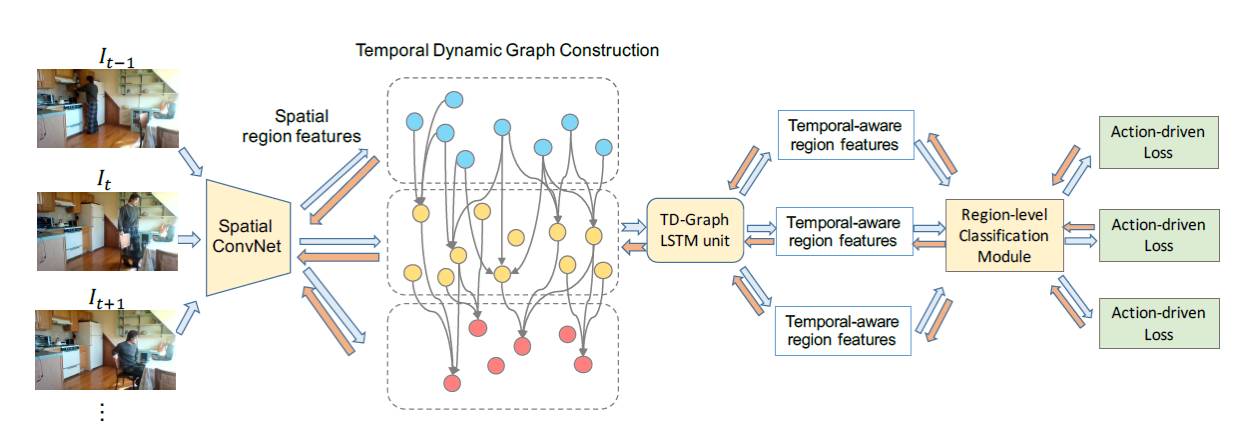
图 2. TD-Graph LSTM 架构。
每帧首先传递到空间卷积神经网络中以提取区域级的特征。随后通过两个连续帧中区域之间的动态边缘连接构建时间图结构。TD-Graph LSTM 随后在更新后的图上循环增加信息,以生成所有区域的时间特征表示。区域级别的分类模块可以生成每帧中所有区域的类别可信度,随后进行聚合以获得帧级动作预测。每帧的最终动作驱动损失函数用于向整个模型反馈信号。在每次梯度更新后,时间图会基于新的视觉特征进行动态更新。为清晰起见,图中省去了一些边缘。
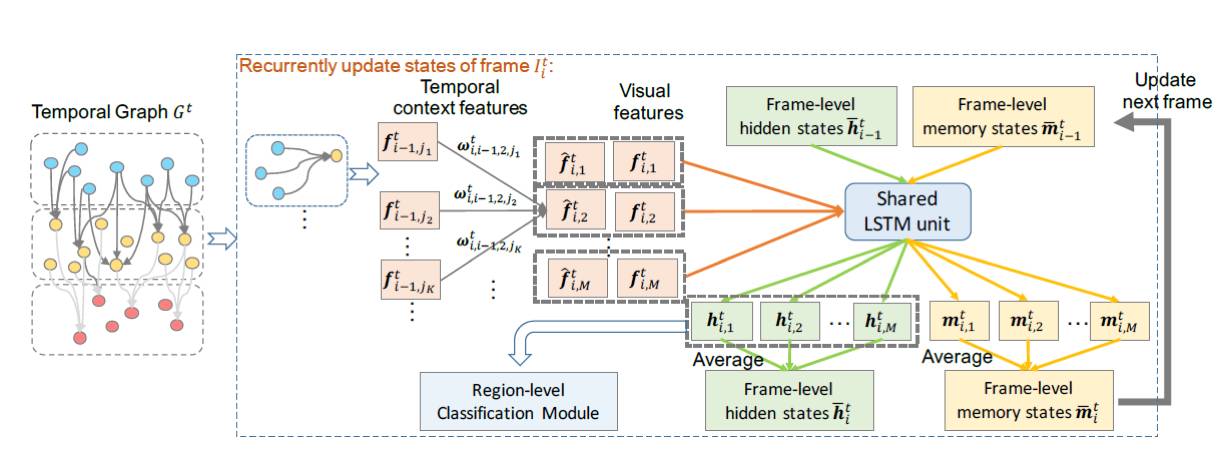
图 3. TD-Graph LSTM 在第 t 次梯度更新时的示意图。

图 4. Charades 游戏视频关键帧的样本图。动作标签都在图像底部,而相关对象则在图像上部。

表 1. 在 Charades 数据集中评估测试分类平均精度(%)时,我们新提出的模型与两种目前最先进的弱监督学习方法的全面性能比较。

表 2. 在 Charades 数据集中评估测试检测平均精度(%)时,我们新提出的模型与两种目前最先进的弱监督学习方法的全面性能比较。

图 7. 新方法与两种目前最佳的视频目标检测方法的定性比较。绿色框为检测结果,黄色框为真值。
论文:Temporal Dynamic Graph LSTM for Action-driven Video Object Detection

论文链接:https://arxiv.org/abs/1708.00666
摘要:在本论文中,我们探讨了弱监督目标检测框架。大多数现有框架着重于使用静态图来学习目标检测器,但由于域转移,这些检测器通常无法泛化至视频。因此,我们尝试让这些检测器直接从日常活动的视频中学习。我们没有使用边界框,而是探索了使用动作描述作为监督的方式,因为这种标记方式相对容易获得。一个常见问题是:未包含在人类动作中的物体通常不会出现在描述语句中,这被称为「标记缺失」。为了解决这个问题,我们提出了全新的时间动态图长短期记忆网络 TD-Graph LSTM。它通过构建基于目标提议的时间相关性并横跨整个视频的动态图来实现全局时间推理。因此,通过在整个视频中相关目标提议的知识进行传递,新方法可以显著减少每一帧的标记缺失问题。我们在大规模日常活动数据集(如 Charades)上进行了大量评估,证明了这种新方法的优越性。我们还发布了 Charades 数据集中超过 5000 帧的目标边界框标注。我们相信,这些标注数据会对未来基于视频的目标识别研究有所裨益。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


