独家 | 清华崔鹏团队KDD论文一作解读:在大数据背景下进行因果效应评估

AI科技评论按:ACM SIGKDD 国际会议(简称KDD)是由ACM的知识发现及数据挖掘专委会(SIGKDD)主办的数据挖掘研究领域的顶级学术会议。AI科技评论今年也来到了KDD 2017现场做了覆盖和报道。参与本次KDD的清华大学博士生况琨受AI科技评论独家邀请,介绍他与导师杨士强博士、崔鹏博士、黎波(清华大学)和蒋朦(UIUC)的工作《Estimating Treatment Effect in the Wild via Differentiated Confounder Balancing》。
论文地址:http://www.kdd.org/kdd2017/papers/view/estimating-treatment-effect-in-the-wild-via-differentiated-confounder-balan
在当今大数据时代,在广告、医疗等各个领域都积累了海量历史数据。同时,大量高效的机器学习和数据挖掘算法提出,使得我们能更有效的利用大数据对未来数据点进行预测。在预测导向的问题上,大部分算法都取得了不错的效果。但是,由于绝大多数预测算法缺乏可解释性,导致其很难应用于许多实际问题上,尤其是那些需要进行决策制定的问题。因此,如何提高这些算法的可解释性,不管对于学术界还是工业界都十分重要。
拿医疗领域举个例子。假设在整个医疗系统中,我们拥有 100 万流感病人数据。对于每一位病人,我们知道其过往病史、诊断历史、常用药物、基因测试以及年龄性别等特征。现在,医院来了为新病人 Anna,我们知道 Anna 是亚洲人,54 岁,得了流感,伴头疼闹热发烧等症状。Anna 问医生,哪种治疗能最有效地治疗其流感。因此,医生就需要做出决策,到底是给 Anna 服用药物 A (Tylenol),还是药物 B (Sudafed),或者是其他药物。作为数据科学家,基于这些数据,我们能不能利用我们的机器学习和数据挖掘算法帮助医生进行正确的药物决策呢?
当然,最简单的,我们可以构造一个回归模型,通过病人的特征(X)加上药物决策(A/B)来回归预测药效(Y)。通过回归模型学习,我们能很容易地预测 Anna 在服用药物 A 或 B 之后的药效,并通过药效差异来进行药物决策。
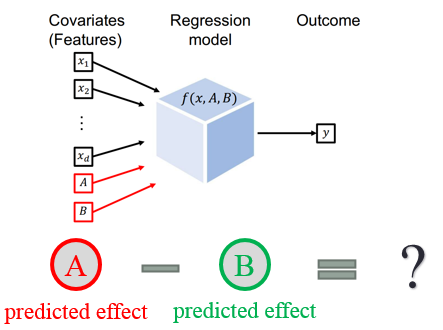
回归模型进行决策制定
但是,我们认为类似于上述基于关联分析的算法是不足以解决决策制定问题的。主要原因如下:
第一,数据中变量之间的依赖性。我们知道,在真实数据中,病人的一些特征,如收入,往往会影响病人对药物的选择。也就是说病人特征和药物的选择并不是独立关系。而在很多关联分析模型中,他们假设数据中变量关系是独立的。忽略数据变量依赖性,会导致我们很难评估每个药物的实际疗效,很容易使得我们做出错误决定。

关联分析模型不足以解决决策制定问题
例如,在医疗历史数据中,我们发现对于大多数身体健壮的病人,即使不服用任何药物,最后病情恢复的也很快;而对于身体虚弱的病人,即使服用了相关的药物,其最后疗效也不是非常好。基于这个简单的数据,关联分析模型会挖掘出错误的觉果:「不服用任何药物对病人反而更好」。
第二个原因是:关联并不代表因果。也就是说两个变量之间存在关联关系,但其并不一定存在因果关系。如果不存在因果关系,那么就不能进行决策制定。例如,基于观测,我们发现某地冰激凌销量跟当地汽车熄火频率十分相关。基于观测数据,我们能通过冰激销量准确预测汽车熄火频率。但是我们并不能通过控制冰激凌销量来达到减少汽车熄火频率的目的,原因就是冰激凌销量跟汽车熄火之间并不存在任何因果关系。冰激凌销量之所以和汽车熄火频率十分相关,是因为受炎热天气影响。
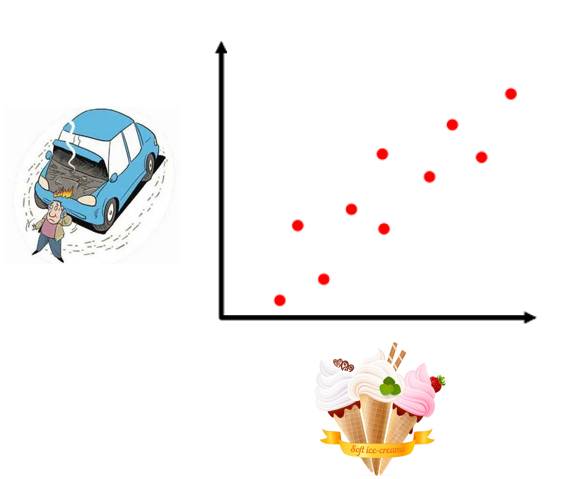
冰激凌销量和汽车熄火频率十分相关
因此,我们认为关联分析模型不足以解决决策制定问题。
因果推理(Causal Inference)是一个用于决策制定等问题的强大统计建模工具。因果推理中一个根本的问题是因果效应评估,常用的方法是随机对照试验,例如 A/B Testing,通过控制两组样本特征一样,然后给予不同的治疗并比较其最终输出的差异来评估药物对患者的因果效应。但是完全的随机对照试验代价往往非常昂贵,而且在很多涉及伦理道德的问题上甚至不可行。因此,处于大数据时代的我们就在思考这样一个问题:我们能不能基于历史观测数据进行因果效应评估?
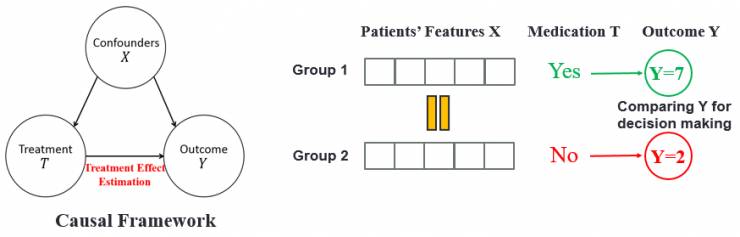
因果推断框架
这个问题的相关工作主要有如下两块:
Propensity Score Based Methods,包括 Inverse Propensity Weight 和 Doubly Robust 方法。这些方法首先需要对 Propensity Score 进行评估,然后通过 Propensity Score 加权样本使得不同 Treatment 组之间的特征 Confounder X 分布是一样的(可以理解为逼近随机对照试验或者 AA Testing),并进行因果效应评估。但是,此类方法的最大缺陷是需要先验知识进行对 Confounder X 和 Treatment T 之间的模型进行假设。然而,我们知道在大数据背景下,我们常常拥有大量的观测变量,我们很难知道变量之间的模型结构,因此我们在计算因果效应时不能进行模型假设。
Directly Variable Balancing Methods,例如 Entropy Balancing 和 Approximate Residual Balancing 方法。这些方法的 Motivation 在于变量的分布由其矩(Moments)唯一决定,因此通过矩可以控制不同 Treatment 组间变量平衡。但是这类方法将所有的观测变量都进行了同等平衡,包括那些不会影响 Treatment T 的一些无关变量。然而,在大数据背景下,并不是所有的变量都需要平衡,而且不同变量需要平衡的权重也不一样。
因此,本文认为在大数据背景下进行因果效应评估,存在如下两个挑战:
一是变量之间关系和模型的未知性,导致我们在进行因果效应评估时不能进行模型假设。
二是高维变量和噪声数据的影响,并不是所有的变量都需要平衡,而且不同变量需要的平衡权重不一样。
为了解决以上挑战,本文提出了 Differentiated Confounder Balancing 算法,通过同时学习 Confounder Weights β 和 Sample Weights W 进行因果效应评估。其中 Confounder Weights 决定哪些观测变量是 Confounder 以及其产生的 Confounding Bias 权重,而 Sample Weights 则用来控制 Treated 组(T=1)和 Control 组(T=0)之间的 Confounder X 分布相似。

Ideas on Differentiated Confounder Balancing Algorithm
但是我们如何去学习这些 Confounder Weights 和 Sample Weights 呢?
首先,学习 Confounder Weights. 在因果推理框架中,X,T 和 Y 之间的一般关系可以如下表示:
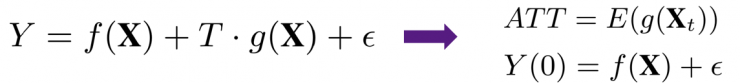
从中我们可以得到真实的因果效应 ATT 的表达式。考虑函数 f(X) 的一般形式:
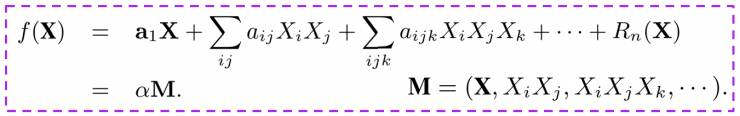
我们从理论上发现,我们实际评估的因果效应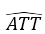
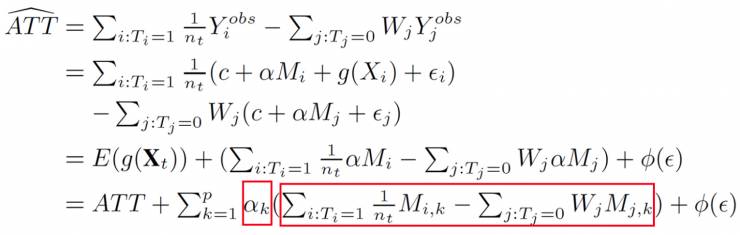
从上述推导中,我们发现如果不同的 Confounder 具有不同的 Confounder Weight αk;而且当αk=0 时,变量 Mk 就不是 Confounder,不需要进行 Balancing。我们还发现在推导过程中的 Confounder Weights αk 正好就是函数 f(X) 中变量 Mk 的相关系数。因此,我们给出如下定理:

其次,学习 Sample Weights. 通过 Wikipedia,我们知道任何变量的矩(Moments)能唯一决定其分布。受这点启发,我们提出了通过变量的矩来直接进行变量平衡,具体如下图。在 Moments 的帮助下,我们可以通过直接变量平衡来学习 Sample Weights,且并不需要任何模型假设。

Sample Weights Learning by Moments
综上,我们 DCB 算法的最终目标函数如下:
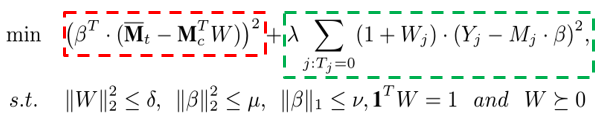
其中,红框部分是用来学习 Sample Weights 的,绿框部分是用来学习 Confounder Weights 的。
实际上,Entropy Balancing 和 Approximate Residual Balancing 方法都是我们 DCB 算法的 Special Cases 通过将我们算法中 Confounder Weights β 设置为单位向量。因此,我们算法对于因果效应评估更加一般化。
我们 DCB 算法的时间复杂度为 O(np),其中 n 表示样本数量,p 表示变量维度。
在实验部分,我们通过三个方面对我们提出的 DCB 算法进行了测试:Robustness Test, Accuracy Test 和 Predictive Power Test.
首先是 Robustness Test. 为了检测我们算法的鲁棒性,我们在仿真数据上生成了各种情景下的高维和噪声数据。

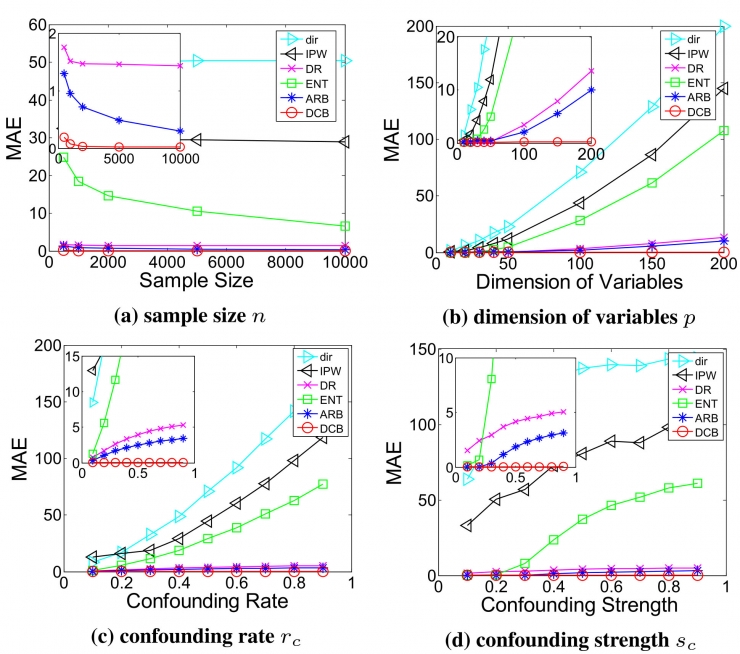
上述图表只汇报了小部分结果,更多结果详见我们论文。从上述结果中,我们发现,基于 Directly Estimator 在所有 setting 下都失败了,这是因为该方法忽略了数据中存在的 confounding bias;基于 propensity score 的方法,IPW 和 Doubly Robust 方法当面临错误的模型假设和高维变量时就会产生巨大错误。ENT 和 ARB 算法由于将所有的观测变量都当作 Confounder 进行同等平衡,导致其最后效果也不理想。而我们的 DCB 算法,通过同时优化 Confounder Weights 和 Sample Weights,在所有 setting 下因果效应评估性能相比基准方法都有显著性提升。说明我们的 DCB 算法的鲁棒性非常好。
其次是 Accuracy Test. 这里我们将 DCB 算法应用在真实数据 Lalonde 数据集上。该数据集包含两块,一块是随机对照试验数据,给我们提供了因果效应的 ground truth;另一块是观测数据,用来检测各个算法对因果效应评估的性能。
实验结果如下表:
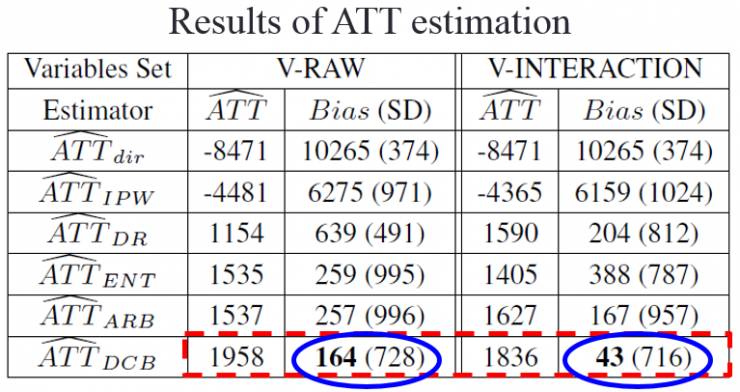
从实验结果可以看出,我们的 DCB 算法能在各中 setting 下更准确地评估因果效应。
最后,Predictive Power Test. 为了检测我们算法的预测能力,我们将 DCB 算法应用于真实的在线广告数据集中。对数据中每一维特征计算其对最后结果产生的因果效应,并选取因果效应最高的 top-k 个特征对最后结果进行预测。预测结果如下图:
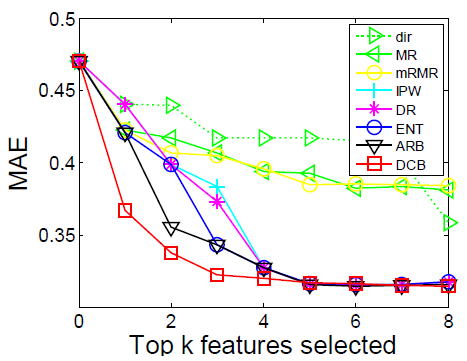
从结果中我们发现,我们的 DCB 算法在该预测问题上达到了最有的预测准确度。同时,我们将我们的算法与经典的 correlation-based features selection 方法 (MRel, mRMR) 进行了对比,实验发现 correlation-based 方法比我们 DCB 方法的效果差了很多,甚至比其他 Causality-based 方法都要差。这就说明,因果效应评估或者因果推理能有效地提升模型的预测能力。(对于 Causality 在预测问题上的应用可以参考我们最新的文章「On Image Classification: Correlation v.s. Causality」)
总结
在本文中,我们专注于解决在无约束的大数据高维背景下如何进行因果效应评估。我们发现之前绝大多数方法抑或没有考虑 Confounders 之间的不同,抑或需要正确的模型假设,导致了在大数据高维背景下表现不佳。因此我们提出了 Differentiated Confounder Balancing 的算法并给出了理论的分析。我们的算法通过联合优化 Confounder Weights 和 Sample Weights 来评估因果效应。基于仿真数据集和真实数据集的大量实验表明我们的方法能够显著地超越当前最好的方法。同时我们的方法所选出的最重要的特征在广告数据集的预测任务上也取得了最好的效果。
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————





