【学习】为什么说随机最速下降法(SGD)是一个很好的方法?
转自:袁洋
[本文主要介绍SGD算法,和两篇分析它逃离鞍点的论文: 我与鬲融,金驰,黄芙蓉写的Escaping From Saddle Points – Online Stochastic Gradient for Tensor Decomposition, 以及由金驰,鬲融等人写的最新力作:How to Escape Saddle Points Efficiently]
假如我们要优化一个函数最小值, 常用的方法叫做Gradient Descent (GD), 也就是最速下降法. 说起来很简单, 就是每次沿着当前位置的导数方向走一小步, 走啊走啊就能够走到一个好地方了.
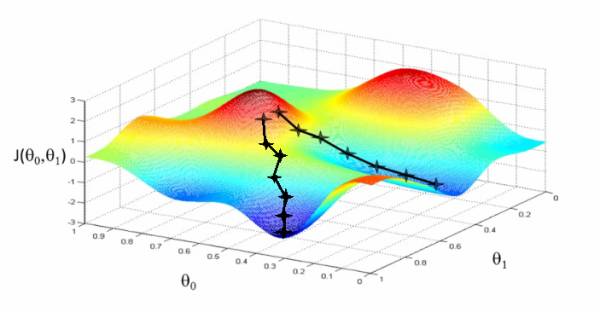
如上图, 就像你下山一样, 每一步你都挑最陡的路走, 如果最后你没摔死的话, 一般你很快就能够走到山脚. 用数学表示一下, 就是
原文链接:
https://zhuanlan.zhihu.com/p/27609238
登录查看更多
相关内容

最速下降法又称为梯度法,是1847 年由著名数学家Cauchy 给出的,它是解析法中最古老的一种,其他解析方法或是它的变形,或是受它的启发而得到的,因此它是最优化方法的基础。作为一种基本的算法,他在最优化方法中占有重要地位。其优点是工作量少,存储变量较少,初始点要求不高;缺点是收敛慢,效率不高,有时达不到最优解。非线性规划研究的对象是非线性函数的数值最优化问题。它的理论和方法渗透到许多方面,特别是在军事、经济、管理、生产过程自动化、工程设计和产品优化设计等方面都有着重要的应用。而最速下降法正是n元函数的无约束非线性规划问题min f (x)的一种重要解析法,研究最速下降法原理及其算法实现对我们有着极其重要的意义
专知会员服务
19+阅读 · 2020年6月29日
专知会员服务
31+阅读 · 2019年12月30日
专知会员服务
148+阅读 · 2019年12月28日
专知会员服务
46+阅读 · 2019年12月25日
专知会员服务
13+阅读 · 2019年10月3日
Arxiv
3+阅读 · 2019年2月26日



相关VIP内容
专知会员服务
19+阅读 · 2020年6月29日
专知会员服务
31+阅读 · 2019年12月30日
专知会员服务
148+阅读 · 2019年12月28日
专知会员服务
46+阅读 · 2019年12月25日
专知会员服务
13+阅读 · 2019年10月3日
相关资讯
相关论文
Arxiv
3+阅读 · 2019年2月26日