谁在椭圆形办公室发推:机器学习揭露川普推文的真实作者
编者按:你是否好奇,名人在社交网络上发的消息,哪些是自己写的,哪些是工作人员写的呢?Coursera数据科学社区导师(Community Mentor)Greg Rafferty使用机器学习技术分析了川普的推文,预测哪些推文是川普亲自发的,哪些推文是工作人员所发。

我创建了一个推特机器人@whosintheoval,这个机器人会转推唐纳德·川普的推特,然后预测这条推是否是川普本人所写。在阅读下文了解我是如何创建模型的之前,别忘了在推特上关注这个机器人。
我是Greg Rafferty,湾区的一个数据科学家。你可以在我的github上查看这个项目的代码,也可以访问我的LinkedIn页面。有任何疑问和反馈,都欢迎和我联系。
动机
2017年12月1日,迈克尔·弗林(Michael Flynn)承认向FBI撒谎了。12月3日,川普的个人推特账号发了这样一条推:
由于弗林向副总统和FBI说谎,我不得不解雇了他。他已经对这些谎言认罪。这真可耻,因为他在过渡期间的行为是合法的。没什么好隐瞒的!

这条推引起了很大的争议,因为在这一年的2月14日,在弗林辞职之后,川普曾要求FBI局长詹姆斯·科米(James Comey)停止对弗林的所有调查。如果川普在向科米要求时已经知道弗林确实向FBI说谎了,那么川普的推特是川普试图妨碍司法的证据。在若干法律专家主张这一观点之后,川普为自己辩护,声称撰写并发布这条推的是他的律师约翰·多德(John Dowd)。然而,果真如此吗?
介绍
本文分为四部分:
背景
特征选取
模型
结果
当中的两小节(特别是模型那一节)技术性比较强;所以如果你对此不感兴趣,可以直接跳到结果一节,看看到底是谁发了关于弗林的那条推。
背景
文本分析取证是一门“古老的”机器学习技术,在各种各样的案例中得到应用,比如识别大学炸弹客(Unabomber),发现罗伯特·加尔布雷斯(Rob Galbraith)是J·K·罗琳(J. K. Rowling)的笔名,确定《联邦党人文集》中特定文章的归属。我们这个项目尝试使用这一机器学习技术识别@realDonaldTrump所发的推是否是川普本人所写。然而,这一任务比较特别,非常具有挑战性,因为推文都非常短——在如此短的文本中没有太多的信号可供分析。不过,我最终还是成功了,精确度几乎达到了99%. 你可以关注我的推特机器人@whosintheoval,这样一旦川普发推,你就可以实时查看相应的预测。
数据
2017年3月26日之前,川普使用三星Galaxy发推而他的工作人员使用iPhone发推。基于这些推文的元数据,我们可以知道是川普本人还是他的工作人员在发推(参考这些具体讨论这一假设的文章的链接)。在此之后,川普转而使用iPhone,因此发推者的身份无法基于元数据得出,需要通过推文内容推断。
我使用了Brendan Brown的Trump Tweet Data Archive(川普推文数据归档),得到了川普账号在2009年中至2017年末所发的所有推文,约有33000条。尽管我知道推文来自于哪个设备,作者身份仍有一些模棱两可,因为人们知道川普有时会向助理口述发推内容,因此一条具有川普特色的推文可能发自非川普所有的设备,同时(特别是大选期间)推文可能是由川普和助手们共同撰写的,没有明确的作者。
川普推特账号从开始(2009年5月4日)至停止使用Android设备(2017年初)的超过30000条推文我知道(至少有比较大的把握能猜到)作者(关键在于,关于弗林的推文不在这一期间,所以我让我的模型猜测真正的发推者——本文之后的结果一节会更多地讨论这个)。这30000条推文基本上是在Android和非Android设备间均匀分布的(47%/53%),所以不用担心类别失衡问题。这是我用的训练数据。使用若干不同的技术,我基于数据创建了将近900个不同的特征,我的模型可以使用这些特征预测作者。
选择特征

我查看了六方面的特征以建立模型:
川普的癖好
风格
情感
情绪
遣词
语法结构
川普的癖好
有时候数据科学更像是艺术而不是科学。在开始构建模型的时候,我首先考虑自己作为人类如何识别一条推文是川普式的。然后尽我所能将这些“感觉”转换为基于规则的代码。有一些明显的癖好,可以识别是否川普本人在键盘后面,例如,全部使用大写,随机大写某个特定词汇,以及无理由!地使用感叹号!!!
事实上,我的模型中最紧要的特征之一就是引用转推。看起来川普不知道如何在推特上转推别人的推文。在整个33000条推文的语料库中,仅有一条来自Android设备的方法正确的转推。在其他转推中,川普复制别人的推文,@用户,然后用引号包围推文,然后自己发布:
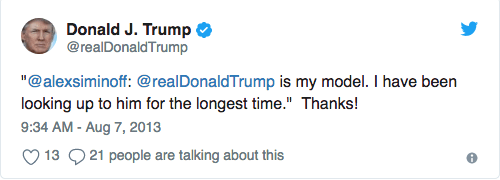
这些转推经常(并非总是)是像这样的自我庆祝推文。在本文后面讨论结果的部分,你会看到,川普倾向于大量@自己,其原因就是这样的转推。
风格
这里的风格特征指可以用来识别任何一个推特用户的特征,而不是指川普的个人风格。风格特征包括每条推文的平均长度,每句话的平均长度,每个单词的平均长度。我也考察了各种标点符号的使用频率(川普几乎从不使用分号;他的助手们相对而言经常使用分号)。@提及、#标签、URL的数目最终都成为强有力的预测特征。最后,在星期几和一天的什么时间段发推也泄露了不少信息。
情感
我使用了C.J. Hutto的VADER包来提取每条推文的情感。VADER是Valence Aware Dictionary and sEntiment Reasoning的简称(因为,我猜,VADSR听起来很蠢?),是一个为社交媒体特别调制的基于词典和规则的工具。给定一个文本字符串,VADER为文本的消极性、积极性和中性各自输出一个0到1之间的小数,以及一个-1到1之间的汇总指标。
关于VADER包的开发、验证、评估的完整描述可以参考这篇论文。VADER的精髓是,包作者首先构造了一个对应情感的词汇特征的列表(用简单英语来说,“单词和短语”),然后将这一列表与一些规则组合起来,这些规则表述了短语的语法结构如何加强或减弱这一情感。VADER的表现(精确度96%)超过了人类(精确度84%)。
情绪
加拿大国家研究委员会(National Research Council of Canada)编制了一个超过14000单词的词典,其中每个单词标注了对应2种情感(消极、积极)和8种情绪(愤怒、希望、厌恶、恐惧、快乐、悲伤、惊讶、信任)的评分。加拿大国家研究委员会十分友善地允许我访问这一词典,我编写了一个Python脚本,遍历推文中的每个单词,通过查询这一词典得出单词对应的情绪。根据推文中包含的对应相应情绪的单词的数目,给每条推文包含的每种情绪分配一个相应的分数。
遣词
我使用tf-idf技术分析推文的遣词,tf-idf是Term Frequency — Inverse Document Frequency(词频-逆向文档频率)的简称。基本上,它衡量了文档中的一个单词的描述性和唯一性。例如,你希望分组一些新闻类文章,并向读者推荐相似文章。你让计算机读取每篇文章,其中一篇的特征是提到了10次“棒球”。那么,“棒球”应该是文章中一个相当显著的单词!这是词频的部分。
然而,同一篇文章同样提到了8次“说过”。看起来这也是一个相当显著的单词。但我们人类并不这么看;我们知道如果若干篇文章都提到了“棒球”,那么它们多半是关于同一主题的文章,不过如果若干篇文章都提到了“说过”,这并不能说明这些文章的相似性。因此我们查看集合内的所有文章使用单词“棒球”和“说过”的词频。比如,结果是,1000篇文章中,只有30篇提到了“棒球”,却有870篇提到了“说过”。那么我们将这些单词在所有文档中的词频的倒数——1/30和1/870——乘以它们在单篇文章中的词频——10和8。这是逆向文档频率的部分。所以单词“棒球”的评分是10/30 = 0.333,单词“说过”的评分是8/870 = 0.009。我们为每篇文档中的每个单词进行这样的计算,然后看看哪些文章具有相同的高分单词。这就是tf-idf。
为了减少我的模型的运算需求,我只考察了一元语法(unigram,单个单词),没有考察二元语法(bigram)和三元语法(trigram)。(tf-idf处理二元语法和三元语法的方法和处理单个单词的方法一样。)n元语法每增加一元,相应的处理时间会指数级增长,并且我发现“Crooked Hillary”或“Lyin’ Ted Cruz”能被“crooked”和“lyin”代表。我同时忽略了在超过99%的推文中出现的词汇(语料库特定的停止词),以及在不到1%的推文中出现的词汇。我的这个项目大量使用了Python的scikit-learn包,它包含了一个tf-idf实现。
语法结构
将自然语言处理技术应用到时效性较强的文本时,遇到的主要挑战之一是事件随时间发生变动。比如,川普竞选期间的推文多次提到了“Crooked Hillary”和“Lyin’ Ted Cruz”,而川普现在的推文几乎不提了。我希望刻画川普推文更基本的形式,因此我使用NLTK将每条推文转换成了词类表示。
本质上,这将每个单词转换成了它的词类,也就是它在句子中的角色,例如,作为名词的“羞辱”和作为动词的“羞辱”被区分开来了。
这将短语“I had to fire General Flynn because he lied to the Vice President and the FBI”转换成它的基本词类表示“PRP VBD TO VB NNP NNP IN PRP VBD TO DT NNP NNP CC DT NNP”。我使用了Penn词类标记(PRP = 人称代词,VBD = 动词过去式,TO = to,VB = 动词原形,NNP = 单数形式的专有名词,等等)。使用之前的tf-idf过程,不过这次忽略一元语法,转而关注二元语法和三元语法,我可以提取更一般的川普或其助手发推方式。
最后,我使用Stanford Named Entity Recognition (NER) Tagger(斯坦福命名实体识别)将推文中的所有人名替换为“PERSON”,所有地名替换为“LOCATION”,所有组织替换为“ORGANIZATION”。这是概括推文的又一尝试。目前为止,这一NER(命名实体识别)过程是处理这些推文时计算开销最高的过程,如果我重新进行这个项目,我可能会认真考虑使用一个次优的NER工具(不依赖高级的统计学习算法的工具),从而显著提升处理时间。勿谓言之不预!
模型如何工作

我采取了这一领域的标准做法,将数据分成两部分:80%训练集和20%测试集。
特征重要程度
我进行的最重要的任务之一是根据对模型输出的影响的数量级排序特征。为了排序,我使用了scikit learn的Ridge分类器。Ridge回归是一种包含正则化因子(alpha)的逻辑回归形式。alpha为零时,ridge回归和普通的逻辑回归一样;alpha值较低时,ridge回归迫使影响力最低的那些特征的系数为零,实际上将这些特征从模型中移除了;alpha值较高时,更多特征被移除了。我递归地迭代每个alpha级别,逐一移除特征,直到所有特征都被移除了。
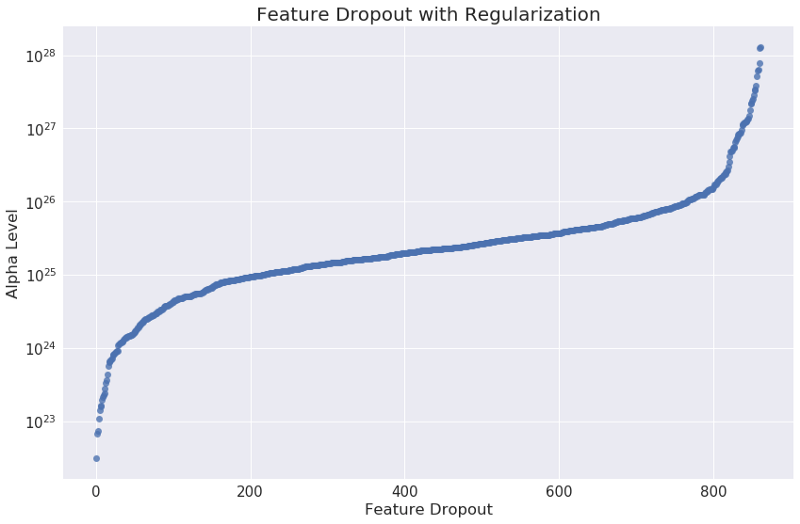
如图所示,在alpha级别刚超过1022时,第一个(影响力最低)的特征被移除了。超过1025之后,特征移除的速度迅速增加了,在1026之上,只有最具影响力的特征保留下来。
单个模型
我总共创建了9个模型:高斯朴素贝叶斯、多项朴素贝叶斯、K近邻、逻辑回归、支持向量分类器、支持向量机,以及集成方法AdaBoost、梯度提升、随机森林。每个模型在训练数据上使用10折交叉验证精心调优,并在测试数据上进行了评估。
交叉验证是训练这些模型同时避免它们过于偏向特定的训练数据的有效方法;换句话说,让它们在未知数据上更具概括性。在10折交叉验证中,数据被平均分为10组,组1-10. 在第一次训练的迭代中,模型在组1-9上训练,在组10上测试。然后重复这一过程,只不过这次在组1-8、10上训练,在组9上测试。整个训练步骤共重复10次,因此训练集中的每个组都有一次被保留,作为未知测试集使用。最后,在10折中具有最佳平均表现的模型参数组合成为最终模型使用的组合。
这些模型背后的算法都很迷人;它们各有自己的优势和弱点,在偏置-方差的折衷上各有不同的取舍,有时处理时间大不相同(例如,训练朴素贝叶斯,只需几分之一秒,而支持向量分类和梯度提升方法各自需要一整个周末进行网格搜索)。如果你对此感兴趣,想要学习更多内容,我推荐从阅读这些模型的维基百科条目开始:
朴素贝叶斯分类器
K近邻算法
逻辑回归
支持向量机
AdaBoost
梯度提升
随机森林
利用前面提到的生成的特征重要程度,我在每个模型上训练了将近900个特征的子集。例如,朴素贝叶斯,在只有5个最重要特征的情形下表现最优,而两个提升模型在300个最重要特征上表现出色。这部分源于维度诅咒;在高维空间中,看上去彼此相近的两个点(在我们3维生物的脑海中想象的),可能事实上相距非常、非常远。特别是K近邻模型(knn),对过多维度高度敏感,因此我对传入这一模型的数据应用了主成分分析(PCA)方法。
主成分分析技术可以在降维的同时消除特征间的共线性。想象一组高维空间中的向量,PCA扭曲、揉搓这些向量,使得所有向量彼此垂直。如果这些向量表示特征,那么通过迫使所有向量正交,我们确保了它们之间不存在任何共线性。这将大大提升knn这样的模型的预测能力,也让我们可以在不减少信息的前提下,减少传给模型的特征数目。简而言之,这让我的knn模型表现更好。
集成
最后,我创建了两个不同的集合。第一个是简单多数投票:奇数个模型和二元输出意味着不会有平局,所以我可以简单地将结果为川普的预测和结果为助手的预测分别相加,其中值较大的那个将是我的最终预测。我的第二个集成有一点复杂:我将9个模型的结果传入一颗新的决策树。这一最终模型在我的测试集上达到了完美的精确度。
好了,终于到结果部分了……
结果
如你所见,梯度提升和随机森林的表现最优,错误率大约只有1/20。
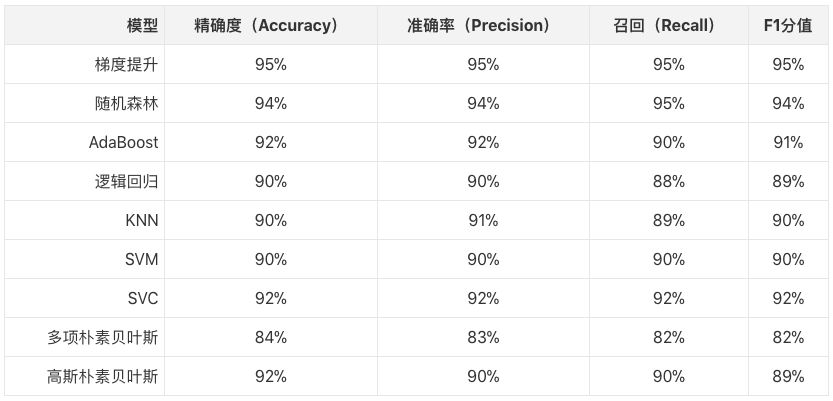
其他模型单独使用时表现不那么好,不过在最终的集成中贡献不少。我基于这9个模型的结果创建的决策树最终达到了99%的精确度!
如果你不清楚上面的这些指标意味着什么,我这里简单介绍一下。精确度是这些指标之中最为直观的,它是正确猜测数除以总猜测数,即,我的所有猜测对了多少?准确率则回答这样一个问题,在我所有猜测是川普所发的推文中,有多少确实是川普所发的?召回几乎是准确率的反义词(不过事实上并不是);它回答的问题是,在所有事实上由川普所写的推文中,有多少被我预测到了?F1是准确率和召回两者的调和,技术上而言是两者的调和平均数(一种平均数)。它理解起来不像精确度那样直观,但当类别失衡程度较高时,f1分值是比精确度好很多的指标。在这一推文数据的情形中,类别很均衡,因此上表中的指标都差不多。如果你仍对这些概念感到困惑,或者你想了解更多内容,可以参考这篇讨论这些指标的文章。
因此,川普的推文的特征是什么呢?
引用转推
@提及
在10pm和10am间发布
惊讶、愤怒、消极性、厌恶、快乐、悲伤、恐惧
感叹号
全大写单词
@realDonaldTrump
正如我所预料的,我在特征选取一节中描述的引用转推很能预测推文是否是川普所发。@提及其他用户同样如此。川普经常在晚上、大清早还有周末发推。他传达了惊讶、愤怒、消极性、厌恶……事实上包括了所有的情绪,而不仅仅是媒体如此强调的负面情绪。相比语法上的需要,他确实更多地使用感叹号和全大写的单词。最后,他太多地提及了自己。
另一方面,他的助手发的推文的特征是:
真正的转推
使用单词“via”
在10am和4pm间发布
分号
句号
URL
@BarackObama
如果一则推文是方法正确的转推,你可以很自信地打赌它是由助手发布的。有趣的是,助手的推文经常使用“via”——他们经常引用一篇文章或者一张图片,然后使用“via”指明作者。意料之中,他们经常在工作日发推,工作日以外不常发推。他们的语法更复杂,句子结构和标点的使用更妥当,同时他们频繁地粘贴指向其他资源的URL。有趣的是,如果一则推文@了Barack Obama(奥巴马)的推特用户名,那么通常这条推文是助手发布的。川普会提到奥巴马的名字,但不会@奥巴马。
词类标记上,川普最常使用的组合是NN PRP VBP,或者,名词、人称代词、动词。这些推文经常采用@某人后接“I thank…”或“I have…”的形式。助手常常写的是NNP NNP NNP,连用三个专有名词,经常是某个组织的名字。同时,助手倾向于在文字之后使用#,而Trump习惯在@某人后使用#。
我有点失望,因为词类标记对模型的作用不是那么显著。我知道推文使用的具体词汇表会随时间而改变,因此我希望更多地刻画语法结构,据我推断,这些语法结构更加稳定。然而,这一项目面对的主要挑战是推文本质上的简短,这大大减少了我的模型可以获取的语法信号。对我的模型而言,尽管它在历史推文上具有几乎完美的精确度,在当下的推文上的精确度下降了。
此外,有三个在历史推文上表现出高度预测能力的特征:推文长度、收藏数量、转推数量。然而,我在部署模型进行实时预测时,移除了这三个特征。移除后两个特征的原因很明显:我尝试在推文发布后立刻进行预测,因此它还没来得及被收藏或被转推。移除推文长度是基于另一个原因。训练数据中的33000条推文,是在推特限制字符数140的前提下发布的。但最近推特将限制提高到了280。所以我需要丢弃基于这一特征进行的训练。
一个小游戏
让我们玩一个小游戏。我会提供一条推特,你来猜猜作者是谁?
别向下滚动太多,以免不小心看到答案!现在是第一条;谁写的,川普还是他的一个助手?
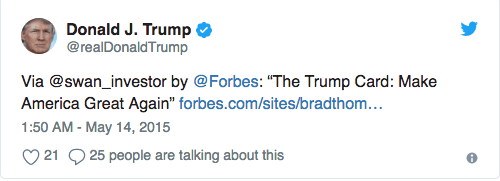
这条比较简单。这条推文使用了单词“via”,明显指示了这是助手所发。它包含一个链接,另一个助手发推的迹象。它是在一天中午发布的,它很正式,不带感情:一切都指向助手。

是的,你猜对了,这条推是助手所发!好,再来一条:

这是川普所发,还是助手所发?同样,让我们综合一切迹象。这一条推文包含了更多感情,通常这是川普的标记。推文里有一个感叹号:这是川普的调调。记得换算时间,时间是6:30pm,工作日差不多结束了。所以,我们可以自信地猜测这条推文的作者是……

川普!是的,又猜对了!
关于弗林的推文
下面是一条重磅推文,整个项目就是因这条推文而起:
这条推文发布于2017年3月26日之后,如果你没忘记的话,这意味着这条推文没有真正发布者的标签。只能寄希望于我的模型了。事实上,这条推文的作者不怎么好猜。它包含“lied”、“guilty”、“shame”、“hide”这样饱含感情的单词——这可能显示川普是作者。另一方面,它又比较正式;语法很规整,同时包含一些超过平均长度的单词:这些又是助手代笔的迹象。它是在中午时刻发布的,又一个助手代笔的暗示。但它又很个人化,暗示是川普。那么我们的模型怎么看?
rf [ 0.23884372 0.76115628]
ab [ 0.49269671 0.50730329]
gb [ 0.1271846 0.8728154]
knn [ 0.71428571 0.28571429]
nb [ 0.11928973 0.88071027]
gnb [ 0.9265792 0.0734208]
lr [ 0.35540594 0.64459406]
rf [1]
ab [1]
gb [1]
knn [0]
nb [1]
gnb [0]
svc [1]
svm [0]
lr [1]
([1], [ 0.15384615, 0.84615385])
“rf”代表随机森林,它预测1,也就是川普,概率为76%(前7行显示概率,第一项为助手,第二项为川普;接下来9行显示预测:0表示助手,1表示川普)。“ab”是AdaBoost,同样预测川普,但是概率是51%对49%——一点也不自信。梯度提升模型更自信,87%的可能是川普。不过KNN并不赞同:71%的可能是助手。多项朴素贝叶斯预测川普,高斯朴素贝叶斯却预测助手。两种支持向量机器模型的意见也不一样:SVC预测川普,SVM预测助手(由于这两个模型构建的方式,它们无法输出概率估计,这是上半部分不包括它们的原因)。逻辑回归比较中庸,64%的可能是川普,36%的可能是助手。也就是说,6个模型预测川普,3个模型预测助手。
事实上,在花费数周事件阅读和分析数以千计的川普推文之后,我认为这条推文是一个协作撰写的最佳样本。从主题和情感的角度分析,它是100%的川普式推文。但从风格和语法的角度分析,它看起来又像是来自一个助手。在我看来,川普大概和多德一起起草了这条推文。川普告诉多德他想说什么,他想怎么说,然后多德实际编写了推文。这是我的最佳猜测。
这显示了这些模型并不是完美的,有不少不一致的地方;同时推文包含的信息对训练机器学习模型而言太少了。我最终的集成模型,在测试集上达到99%精确度的决策树,给出的最终预测是川普,概率为85%(上面的代码中的最后一行)。所以这就是我们最终的答案:川普。不是约翰·多德,川普的律师。所以他们声称是多德而不是川普写了那条推文,我们只能设想这是:

附:如何部署模型:https://towardsdatascience.com/whos-tweeting-from-the-oval-office-building-a-twitter-bot-9c602edf91dd





