一文看懂地平线如何再造"摩尔定律"| 地平线大牛讲堂
3月 25 日,地平线 BPU 算法负责人罗恒以《地平线如何追求极致效能?》为题展开了一场别开生面的线上分享。
作为「地平线核心技术系列公开课」的“奠基之课”,罗恒从当前 AI 芯片的最大挑战,到 MLperf 的理想性与局限性,再到地平线 BPU(Brain Processing Unit,地平线自研人工智能专用处理器架构)的演进之路娓娓而谈,结合人工智能的发展趋势深度剖析了地平线通过软硬结合挑战极致效能,再造“摩尔定律”的技术历程。
以下为经整理后的分享:
AI 芯片最大的挑战
自 2015 年起,AI 芯片逐渐成为人们所关注的趋势。产业参与者们都希望能够做出极具竞争力的芯片,种种挑战中最大的莫过于算法发展快和芯片迭代慢之间的矛盾。
以 2016 年 DeepMind 提出的人工神经网络 WaveNet 为例,它能够模仿出让真假难辨的人类声音,但其计算量之大甚至无法在当时最强大的 GPU 上实时处理,接近一分钟的延迟让这项革命性突破始终无法真正的得到应用。
2017 年,算法优化后的 Paralle WaveNet 让计算效率提升了 1000 倍,谷歌将其成功应用到谷歌助手。假如某公司在此时(2017年)准备推出一款用于嵌入式系统的芯片,使得手机等移动场景也可以应用这项 AI 成果,是非常合理的选择。但到了 2018 年,算法又发生了优化,核心计算方式历经 RNN、DalitedCNN 已升级到了 Spares RNN,让手机 CPU 也可以运行。而 2017 年研发的芯片,在 2019 年才能面世,这是一个悲伤的故事,反映了算法快速发展与芯片迭代较慢之间的矛盾。
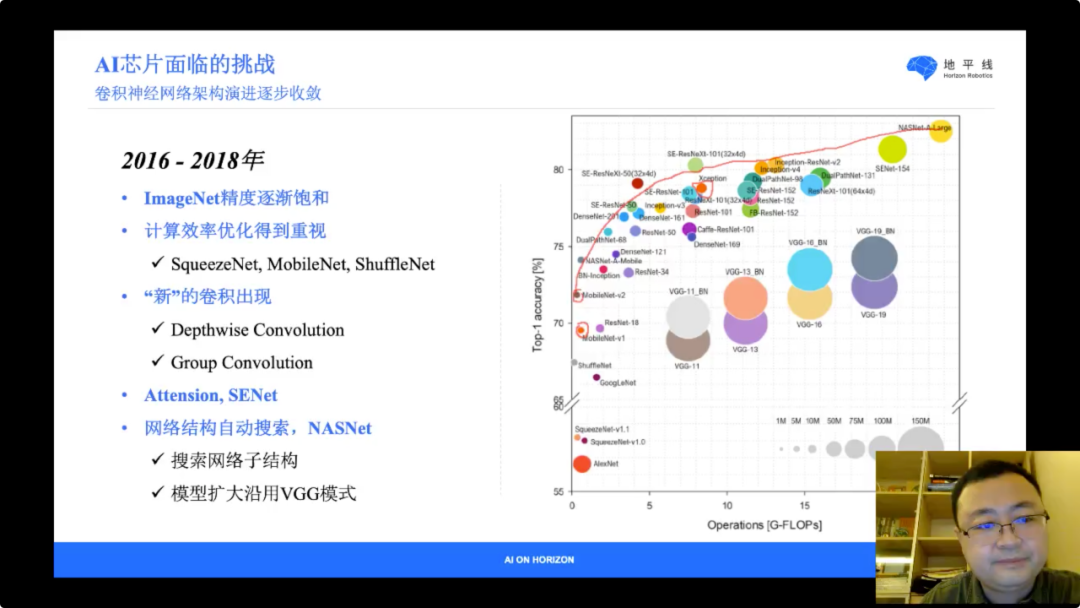
回到地平线的主航道视觉感知上。2012 年的 AlexNet 在 ImageNet 上的突破, 拉开了这一波的 AI 浪潮的序幕,2012 年到 2016 年,各种网络出现,起初致力于提升 ImageNet,VGG 模型扩充过快受限于 GPU,接下来的模型开始适度的考虑精度和算力的折中,ResNet 开始给出扩充网络算力获得不同精度的方案。
2016 年之后,ImageNet 精度逐渐饱和,计算效率优化得到重视,算法实现开始追求用更少的计算得到更高的精度,SpueezeNet、MobileNet、ShuffleNet就是这一时期的“新”卷积神经网络代表。同时也开始了使用机器学习方法自动化搜索网络,以 NASNet 为代表,但主要还是在搜索网络子结构。
到了 2019 年,卷积神经网络架构演进逐步收敛,子结构收敛于 MobileNet v2 的子结构,模型扩充方法则来自于 EfficientNet 的 Compound scaling method。
以上 AI 算法的演进趋势对 AI 芯片厂商之间的竞争产生了极为重要的影响:固然芯片架构设计能力,芯片SOC 的能力非常重要,但是由于算法在不断的变化,如何能够使得设计出来的芯片在面世的时候还能够符合算法的最新的进展,在现在乃至可预见的未来都将是 AI 芯片竞争的关键点。
什么是更好的 AI 芯片?
算法演进与芯片迭代的脱节是摆在面前的挑战,那么,如何为 AI 芯片赛道上的玩家设立清晰的目标?如何拉通研究与市场,拉通工程与开发,并通过最优代表性的任务在实际场景中的测试反映机器学习算法的演进呢?目前通用的基准测试是 MLPerf。
但事实上,2019 年 MLPerf Inference V0.5 使用的分类模型仍是 ResNet50 和 MobileNet V1,检测模型则是 MobileNet V1和RerNet34。从这一点来看,MLPerf Inference 尽管是刚刚出现的,但由于采用相对较老的模型其已经落后于算法进展两年了。此外,由于量化模型的普及型,MLPerf 希望设计统一的标准,但却因为精度问题最终选择降低标准(MobileNet)。
提交者和标准设计方之间的博弈,使得任务往往没有办法像预期那样更新模型。但地平线始终认为,评估 AI 芯片的真实效能需要与时俱进的标准。
因此为了更严格的测试真实效能,选用了目前如前所述的视觉领域最高效的 MobileNet V2 结构(EfficientNet 并不改变计算方式,其中的 SE 结构也被 EfficientNetTPU 证明并不是关键因素)。实测表明,工艺领先两代的两款竞品,在 MobileNet V2 的帧率上显著落后于地平线征程二代芯片。
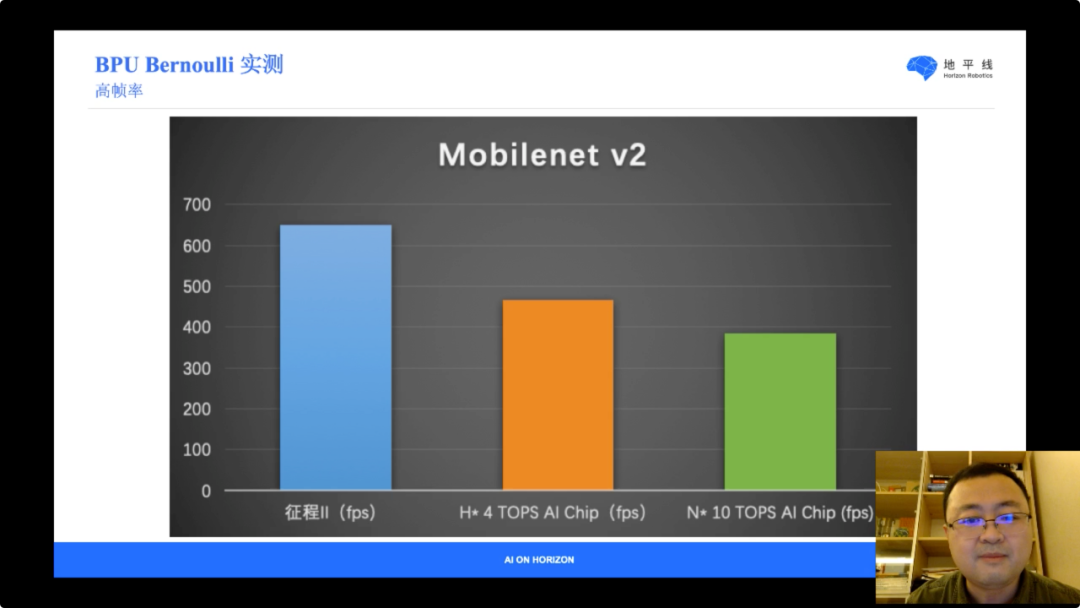
除此之外,想要实现极致能效还需要考虑到其他因素。
对于芯片来说,功耗最大的地方并不在于计算,还在于数据的搬运,如何能够减少 DDR (Double Data Rate SDRAM,双倍速率同步动态随机存储器)的吞吐,其实是降低功耗的一个关键的地方。这方面地平线也做了针对性的优化,在帧率超过竞品芯片的情况下只有竞品 1/4 DDR 吞吐率。从而,一方面用户可以使用更低成本的DDR,另一方面则是我们不可能假设用户加速模型的时候是 DDR 独占,一定需要和 ISP、Codec 以及各种应用一起使用带宽,征程二代的低 DDR 吞吐率使得用户可以充分使用算力而不受限于 DDR 带宽。
BPU 软硬结合打造极致效能
回到设计征程二代 BPU 的2017年,我们观察到学术界的两个信号,Xeception和MobileNet 分别使用了 Depthwise Convolution 在 ImageNet 高精度和中低精度都取得了很好的效率。
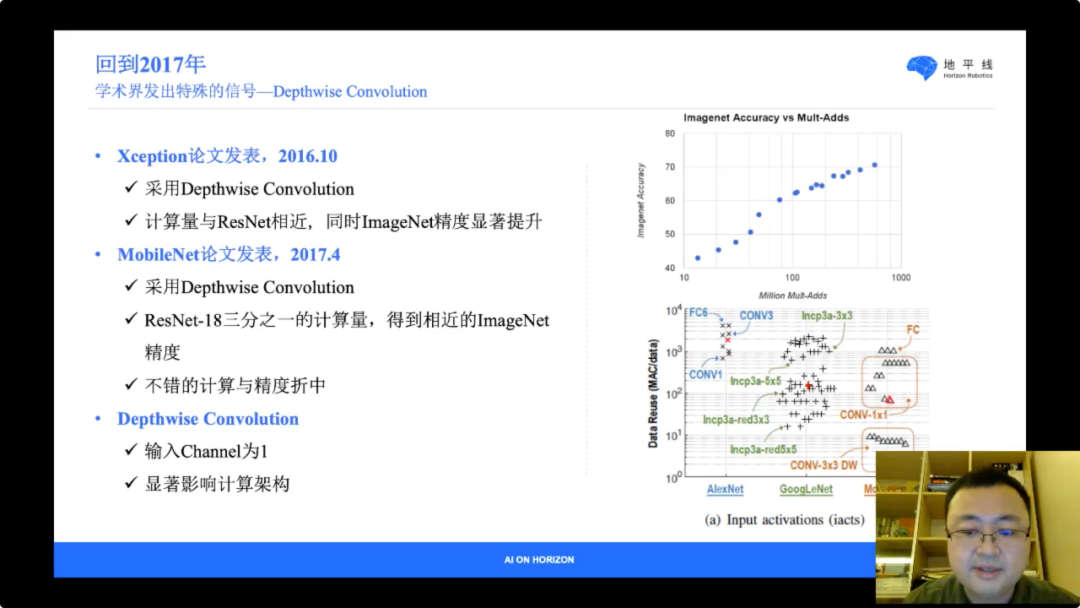
我们迅速在地平线关心的视觉任务、自由数据上做了验证。证明了 Depthwise Convolution 带来的效率提升。
进而我们做了初步的优化,8bit 量化了 Depthwise Convolution 模型,量化模型精度>浮点模型精度*0.99(半年后Google量化论文发表,但精度并不理想);尝试了使用1x1 扩大 Depthwise Convolution 的 kernel 数目同时减少1x1 convolution引入的计算量(与一年后发表的MobileNet v2相似);尝试了不同kernel size,发现扩大 kernel size 到 7 可以提升精度在只付出很小的计算代价下(与两年后的 Mixconv 论文一致)。
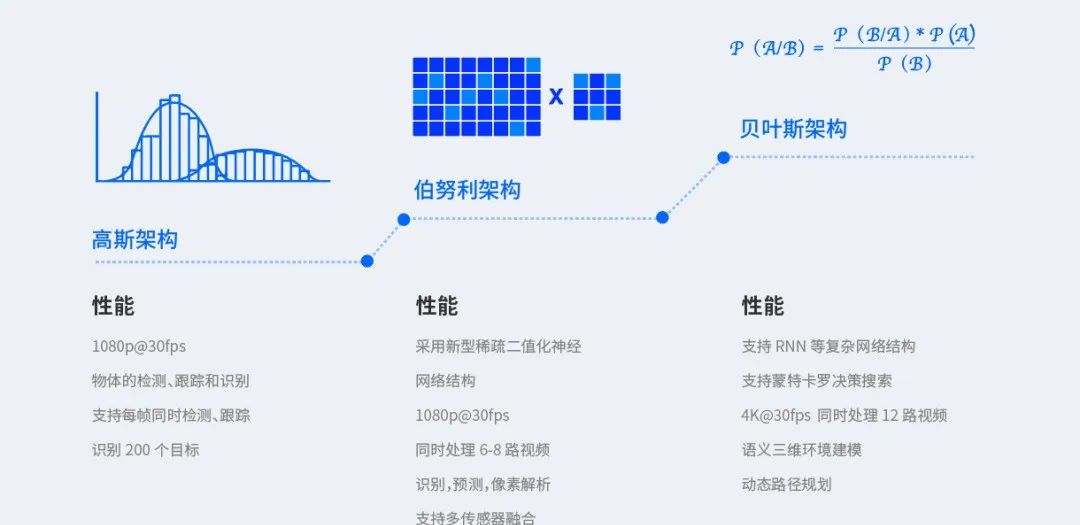
在完成初步验证和优化之后,我们做了 BPU 的 FPGA 版本,演化成为后来的 Matrix(曾获 2019 年 CES 创新奖,这也是车辆智能和自动驾驶技术分类奖项下唯一获此殊荣的中国产品),实车测试了我们的所有方案。

以上的验证、优化、实际应用场景打磨,为我们的架构设计提供了参考,使得我们从一开始就面向未来的算法趋势进行优化,在今天也得到了证明。
可以说,地平线的最大特点,就是对关键算法的发展趋势进行预判、在最重要的场景中垂直打穿,前瞻性地将其计算特点融入到架构设计当中,使得 AI 处理器经过两年的研发,在推出的时候,仍然能够很好地适应最新的主流算法,同时保证满足最关键应用的需求。因此,和其他典型的 AI 处理器相比,地平线的 AI 处理器,随着算法的演进趋势,始终能够保持相当高的有效利用率,从而真正意义上受益于算法创新带来的优势。
技术先发优势推动商业化进程,领先的商业落地探索又反哺技术进步。在 AI 芯片这条硬科技创新道路上,地平线将继续坚持深耕“算法+芯片+工具链”基础技术平台。预计今年内,地平线将会推出新一代车规级 AI 芯片,以人工智能赋能万物,让每个人的生活更安全、更美好!
下一期,地平线将进一步解读“天工开物”AI开发平台如何开放赋能,欢迎大家扫码报名~

关于地平线「大牛讲堂」
「大牛讲堂」秉承着“为技术干货而生”的理念,旨在通过分享人工智能与 AI 芯片领域的前沿观点、技术干货、开发者经验,打造一个开放的技术社区。正如地平线抱着开放心态、坚持芯片赋能一样,「大牛讲堂」也希望以同样的开放心态分享知识,与AI路上的同行者一起进步。
近期,我们推出了「地平线核心技术系列公开课」,希望通过在线分享的形式让更多的人了解 AI 芯片的前沿知识,传播技术的力量!
— 完 —
如何关注、学习、用好人工智能?
每个工作日,量子位AI内参精选全球科技和研究最新动态,汇总新技术、新产品和新应用,梳理当日最热行业趋势和政策,搜索有价值的论文、教程、研究等。
同时,AI内参群为大家提供了交流和分享的平台,更好地满足大家获取AI资讯、学习AI技术的需求。扫码即可订阅:
了解AI发展现状,抓住行业发展机遇

AI社群 | 与优秀的人交流


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



