如何亿点点降低语音识别跨领域、跨语种迁移难度?

(本文阅读时间:18分钟)
语音识别就是将人的声音转化为对应的文字,在如今的日常生活中有着重要的应用,例如手机中的语音助手、语音输入;智能家居中的声控照明、智能电视交互;还有影视字幕生成、听录速记等等,以语音识别为核心技术的应用已经屡见不鲜。但是,语音数据天然存在着获取难、数据标注耗时昂贵的问题。不同人的方言、口音、说话方式也有所不同。受限于此,采集到的语音数据绝大多数会面临模型漂移、标注数据不足等问题。
尤其是语音识别中的跨领域和跨语言场景更是十分具有挑战性。跨领域指的是在领域 A(如普通麦克风)训练的模型如何迁移到领域 B(如专用麦克风)。而跨语种则指的是在语言 A(如俄语)上训练的模型如何迁移到语言 B(如捷克语)。特别是对于一些标注数据稀缺的小语种更是如此。因此,研究低资源跨语种迁移至关重要。
为了解决上述难题,微软亚洲研究院提出了用于语音识别的无监督字符级分布适配迁移学习方法 CMatch 和基于适配器架构的参数高效跨语言迁移方法 Adapter。相关论文已分别被语音领域顶会和顶刊 Interspeech 2021 及 IEEE/ACM TASLP 2022 所接收。(论文链接,请见文末)

众所周知,基于深度学习的端到端 ASR(自动语音识别)已经可以通过大规模的训练数据和强大的模型得到很好的性能。但是,训练和测试数据之间可能会因录音设备、环境的不同有着相似却不匹配的分布,导致 ASR 模型测试时的识别精度下降。而这种领域或分布不匹配的情况非常多样且常见,以至于很难对每个领域的语音数据进行大量收集并标记。这种情况下模型往往需要借助无监督领域适配来提升其在目标域的表现。
现有的无监督领域适配方法通常将每个领域视为一个分布,然后进行领域适配,例如领域对抗训练或是特征匹配。这些方法可能会忽略一些不同领域内细粒度更高的分布知识,例如字符、音素或单词,这在一定程度上会影响适配的效果。这点在此前的研究《Deep subdomain adaptation network for image classification》[1] 中得到了验证,与在整个域中对齐的传统方法相比,在子域中对齐的图像(即按类标签划分的域)通常可以实现更好的自适应性能。
微软亚洲研究院提出了一种用于 ASR 的无监督字符级分布匹配方法—— CMatch,以实现在两个不同领域中的每个字符之间执行细粒度的自适应。在 Libri-Adapt 数据集上进行的实验表明,CMatch 在跨设备和跨环境的适配上相对单词错误率(WER)分别降低了14.39%和16.50%。同时,研究员们还全面分析了帧级标签分配和基于 Transformer 的领域适配的不同策略。
以图1为例,通过执行 CMatch 算法,两个领域相同的字符在特征分布中被拉近了:
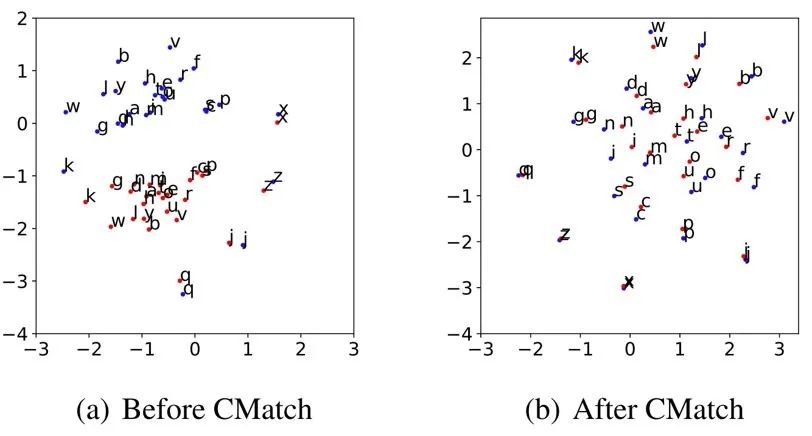
图1:执行 CMatch 前后效果对比
CMatch 方法由两个步骤组成:帧级标签分配和字符级别的分布匹配。
其中,帧级别标签分配可以为语音信号获得更加准确的“特征-标签”对应关系,为下一步实现基于标签(即字符)的分布适配提供依据,即需要获得帧级别的标签以取得更细粒度的特征分布。要想进行帧级标签分配,首先需要获得较为准确的标签对齐。如图2所示的三种方法:CTC 强制对齐、动态帧平均、以及伪 CTC 标签。可以看出,CTC 强制对齐是通过预训练的 CTC 模块,在计算每条文本对应的最可能的 CTC 路径(插入重复和 Blank 符号)后分配到每个语音帧上,这个方法相对准确但是计算代价较高;动态帧平均则是将语音帧平均分配到每个字符上,这个方法需要基于源域和目标域语速均匀的假设;而伪 CTC 标签的方法,通过利用已经在源域上学习较好的 CTC 模块外加基于置信度的过滤(如图2中的 t、e、p 等),兼顾了高效和准确性。
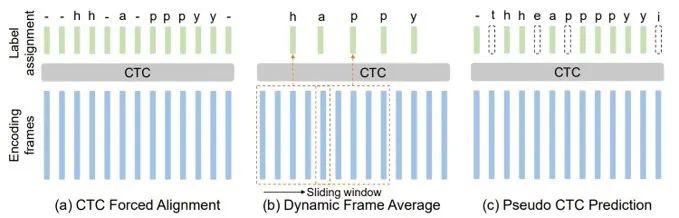
图2:三种帧级标签分配策略
需要说明的是,在源域上使用真实文本进行标签分配时,由于目标域没有文本,所以需要借助源域模型先对目标域的语音数据进行伪标注,然后再使用模型标注的文本进行标签分配。
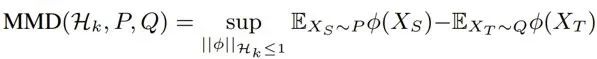
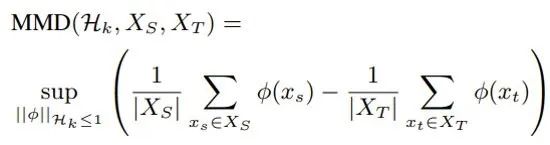

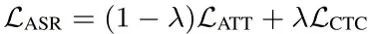
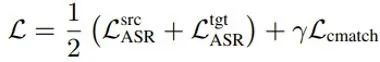

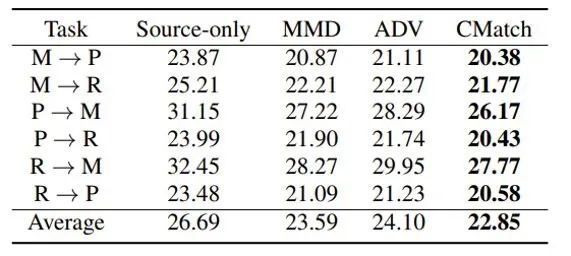
表3的结果表明,CMatch 在跨环境(抗噪声)语音识别情况下也取得了很好的效果。
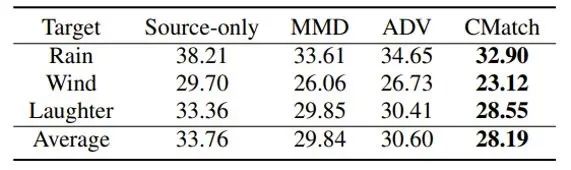
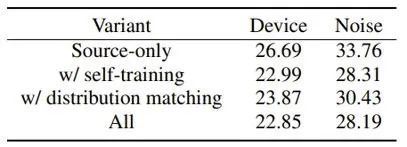
此外,研究员们还分析比较了三种字符分配方法。在表5中可以看出 CTC 强制对齐取得了最好的效果,但是其计算开销也最大;而 FrameAverage 也取得了较好的效果,但它的假设前提是领域和目标域具有均匀的说话速度;而使用 CTC 伪标签的方法取得了与 CTC 强制对齐相近的结果,同时计算起来也更加高效。
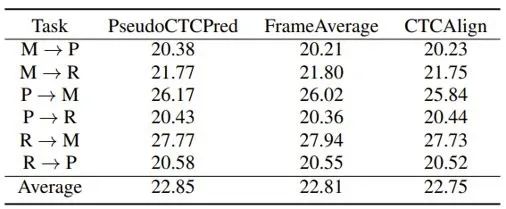
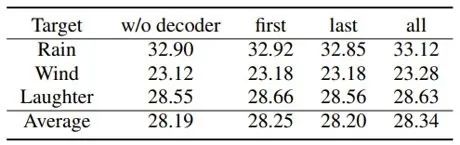
最后,对于是否需要在解码器端使用 CMatch Loss,实验结果如表6。由于解码器在实验中本来就没有功能上的差别,目标文本都是标准的英文,因此减小其分布的差异并没有什么效果,甚至会损害性能。
在一代代科学家和工程师的努力下,语音识别系统在各种主流语言上都已经达到了非常好的效果,比如英语、中文、法语、俄语、西班牙语等……让人们在日常生活中就能享受其带来的便利。然而,世界上有大约7,000种语言,其中绝大部分语言的使用者并不多,而且不同人的方言、口音、说话方式也有所不同,这就使得这些语言的语音数据十分稀缺,即低资源(low-resource)语言。标注数据的稀缺导致近年来端到端语音识别的诸多成果迟迟不能应用到这些语言上。
为此,微软亚洲研究院的研究员们开始思考如何利用迁移学习,将主流语言(如英语、中文等)的知识用于帮助低资源语言的学习,在多种语言之间共享,起到“四两拨千斤”的效果,从而提升小语种语音识别的表现。如图3所示,给定罗马尼亚语作为目标语言,如何利用数据相对丰富的意大利语、威尔士语和俄语来训练出更好的罗马尼亚语语音识别模型?
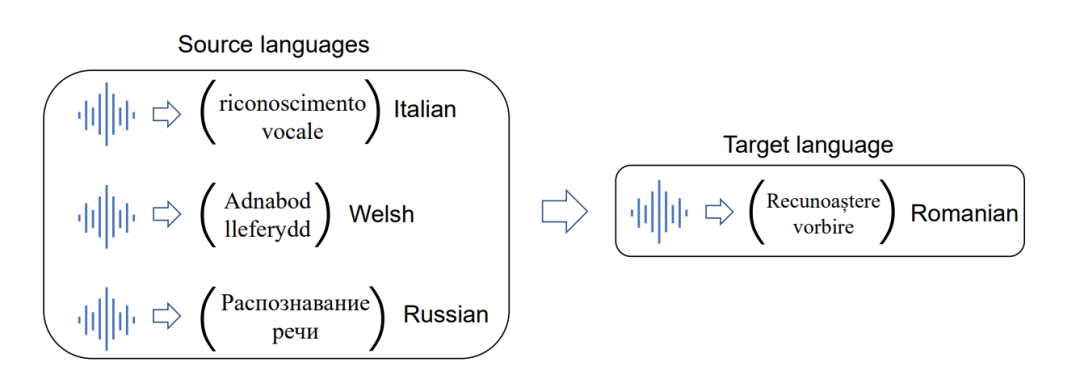
图3:给定若干源语言,如何将知识迁移到目标语言上?
幸运的是,近年来,如 wav2vec2.0 [2] 等预训练模型都已经推出了多语言版本,微软亚洲研究院之前的研究也证明了仅需要简单的微调,一个大规模的多语言模型就能被适配到一个低资源语言上,并能显著改善识别性能。
但与此同时,研究员们也发现了两个新问题:
大规模的多语言模型往往含有大量的参数,导致在一些数据量非常少的情况下,模型极易过拟合。
如果对于世界上的每一个小语种都维护一个微调后的大模型,成本将会十分巨大。
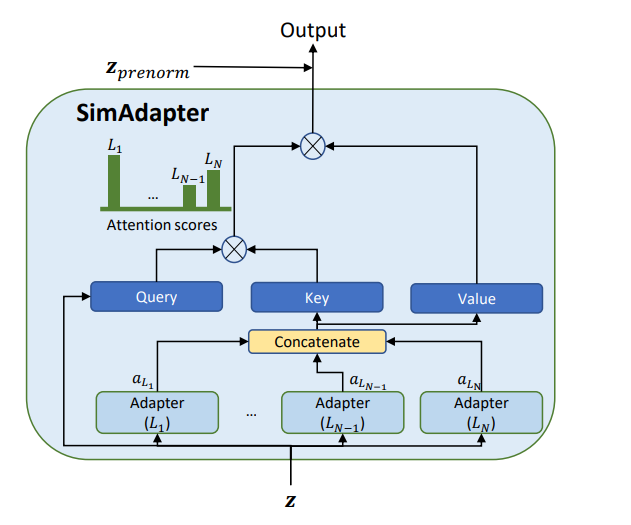
不过,之前 Houlsby 等人发现[3],对于一个预训练好的 BERT,只需要在 Transformer 的每一层插入一个如图4所示的 Adapter,就能在不改变模型主干参数的情况下将模型适配到各种下游任务,甚至能够取得接近整个模型微调的表现。Adapter 主要包含一个 LayerNorm 层,用于重新调节原始特征的尺度,接着分别是一个降采样层和一个升采样层对特征进行压缩和还原,最后由一个残差连接保证原始特征依然能通过,从而提升 Adapter 训练时的稳定性。
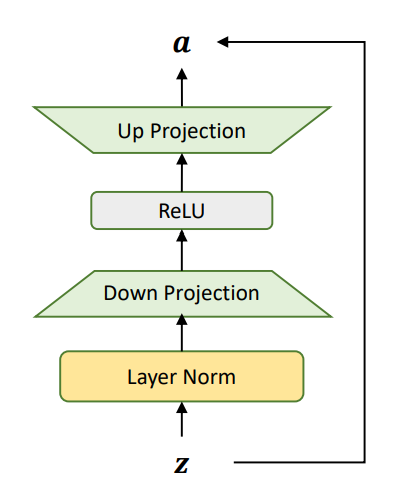
图4:Adapter 结构示意图
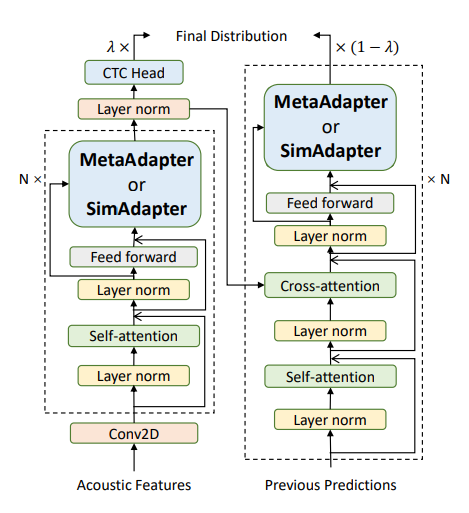
MetaAdapter:MetaAdapter 在结构上与 Adapter 完全一致,唯一不同的是,使用了 MAML (Model-Agnostic Meta-Learning) [4] 元学习算法来学习一个 Adapter 更优的初始化。MetaAdapter 需要通过学习如何学习多种源语言,从而在各种语言中收集隐含的共享信息,以帮助学习一个新的语言。实验发现,MetaAdapter 对于过拟合和极少数据量的鲁棒性,以及最终迁移效果均显著强于原始 Adapter 。
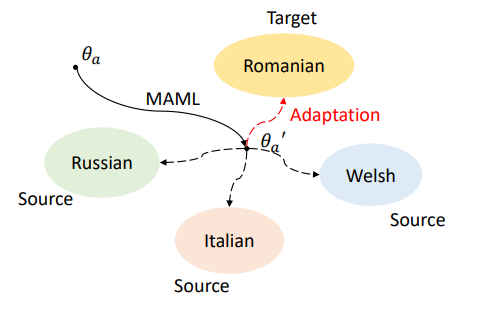
图6:MetaAdapter
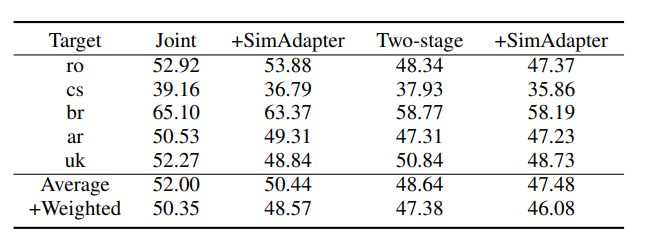
通过将模型在 Common Voice 的五种低资源语言上进行实验,结果如表7所示。根据迁移与否以及迁移方式的不同,可以将各种方法分为三类:
不迁移(左边栏):包括了传统的 DNN/HMM 混合模型,从头训练的 Transformer(B. 和本文用的主干模型大小结构均一致;S. 指为了抑制过拟合,而将参数量调小的版本),以及将预训练好的模型当作特征提取器,去学习目标语言的输出层。
基于微调的迁移(中间栏):包括了完整模型的微调,以及对于抑制过拟合的尝试(完整模型微调 +L2 正则化、仅微调模型最后几层参数)
基于 Adapter 的迁移(右边栏):即本文介绍的各种方法,其中 SimAdapter+ 是结合了 SimAdapter 和 MetaAdapter 的升级版。

-
使用迁移学习的方法均明显好于不使用迁移学习的方法,印证了迁移学习的重要性。 -
全模型微调有着非常强大的效果,对其施加传统的 L2 正则,或是仅微调模型最后几层参数效果都不理想。 -
原始的 Adapter 在合适的训练方法下基本可以达到和全模型微调相同的水平,说明了 Adapter 在 ASR 任务上的有效性。 -
本文提出的 SimAdapter 和 MetaAdapter 均进一步提高了 Adapter 的表现,将它们结合后的 SimAdapter+ 更是达到了文中最优的结果。 -
值得注意的是,MetaAdapter 更擅长数据量极少的情况,而在 SimAdapter 则有着更均衡的表现。
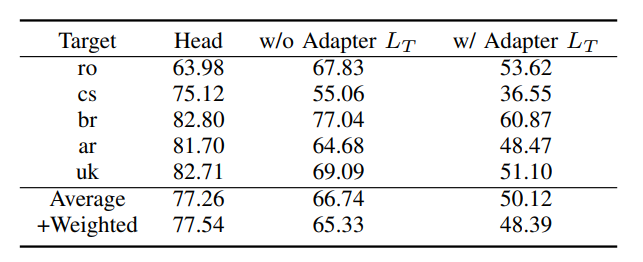
另外,为了证明 SimAdapter 的确能够从其他语言学习到有用的知识,研究员们设计了两个实验:
其一,尝试去除目标语言本身的 Adapter ,以要求 SimAdapter 仅通过源语言来学习一个对目标语言有用的特征,结果如表所示:即使没有使用目标语言 Adapter,SimAdapter 依然能够在多数语言上取得较为明显的提升。
微软亚洲研究院已将 CMatch 和 Adapter 代码开源,地址如下:
https://github.com/microsoft/NeuralSpeech/tree/master/CMatchASR
https://github.com/microsoft/NeuralSpeech/tree/master/AdapterASR
相关论文链接:
[1] Deep Subdomain Adaptation Network for Image Classification
https://arxiv.org/abs/2106.09388
[2] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
https://arxiv.org/abs/2006.11477
[3] Parameter-Efficient Transfer Learning for NLP
https://arxiv.org/abs/1902.00751
[4] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
https://arxiv.org/abs/1703.03400
你也许还想看: