深度学习模型压缩算法综述

极市导读
本文以两篇综述深度学习模型压缩算法的综述为基础,加入了一定的分析和补充对模型压缩算法进行总结介绍。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
今天要跟大家分享的是关于深度学习模型压缩算法的综述,我们将以2020年的一篇名为《A Survey of Model Compression and Acceleration for Deep Neural Networks》的综述文章为基础,结合另一篇2020年发表的名为《A Comprehensive Survey on Model Compression and Acceleration》的文章,并加入一定的分析和补充。
背景介绍
近年来,深度神经网络(deep neural networks,DNN)逐渐受到各行各业的关注。它是指具有更深层(不止一个隐藏层)的神经网络,是深度学习的基础。很多实际的工作通常依赖于数百万甚至数十亿个参数的深度网络,这样复杂的大规模模型通常对计算机的CPU和GPU有着极高的要求,并且会消耗大量内存,产生巨大的计算成本。随着一些便携式设备(如移动电话)的快速发展,如何将这些复杂的计算系统部署到资源有限的设备上就成为了需要应对的全新挑战。这些设备通常内存有限,而且计算能力较低,不支持大模型的在线计算。因此需要对模型进行压缩和加速,以求在基本不损失模型精度的条件下,节约参数并降低其计算时间。
目前,在模型压缩和加速方面常用的方法大致可以分为四类:剪枝与量化(parameter pruning and quantization)、低秩因子分解(low-rank factorization)、迁移/压缩卷积滤波器(transferred/compact convolutional filters)、蒸馏学习(knowledge distillation)。作者在文中给出的图1展示了这些方法的定义及其之间的对比:
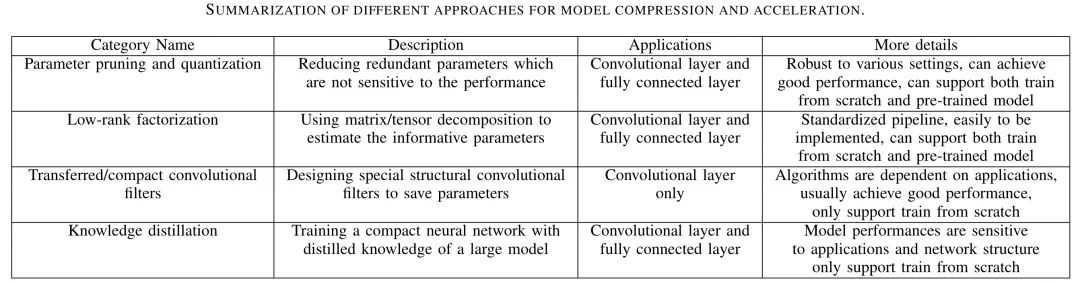
剪枝与量化主要针对模型中的冗余参数进行删减;低秩因子分解使用张量分解的方法来估计神经网络的参数;迁移/压缩卷积滤波器则是设计了一个特殊结构的卷积滤波器,能够减少参数空间并且节约内存;蒸馏学习是先训练一个较大的模型,再训练一个较小的神经网络以达到跟大模型同样的效果。其中,低秩因子分解和迁移/压缩卷积滤波器两种方法提供了端到端的管道,可以在CPU/GPU环境中轻松实现;而剪枝与量化使用二进制及稀疏约束等方法来实现目标。此外,剪枝与量化和低秩因子分解方法可以从预训练的模型中提取或者是从头开始训练,而另外两种方法仅支持从头开始的训练。这四种方法大多是独立设计的,但又相互补充,在实际应用中常常可以一起使用,实现对模型进一步的压缩或加速。接下来将分别对这四种方法进行介绍。
剪枝与量化(parameter pruning and quantization)
早期的研究表明,对构建的网络进行剪枝和量化在降低网络复杂性以及解决过拟合问题方面是有效的(Gong et al. 2014)。同剪枝与量化有关的方法可以进一步分为三个子类:量化与二值化(quantization and binarization)、网络剪枝(network pruning)、结构矩阵(structural matrix)。
1.量化与二值化(quantization and binarization)
在DNN中,权重通常是以32位浮点数的形式(即32-bit)进行存储,量化法则是通过减少表示每个权重需要的比特数(the number of bits)来压缩原始网络。此时权重可以量化为16-bit、8-bit、4-bit甚至是1-bit(这是量化的一种特殊情况,权重仅用二进制表示,称为权重二值化)。8-bit的参数量化已经可以在损失小部分准确率的同时实现大幅度加速(Vanhoucke et al. 2011)。图2展示了基于修剪、量化和编码三个过程的压缩法:首先修剪小权重的连接,然后使用权重共享来量化权重,最后将哈夫曼编码应用于量化后的权重和码本上。
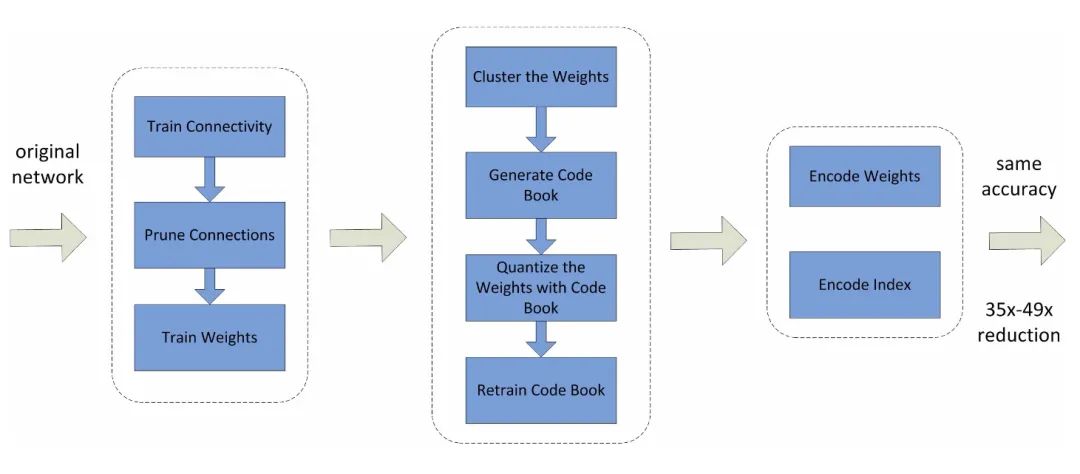
此方法的缺点是,在处理大型CNN(如GoogleNet)时,二值网络的精度明显降低。此外,现有的二值化方法大多基于简单的矩阵近似,忽略了二值化对精度损失产生的影响。
2.网络剪枝(network pruning)
剪枝是指通过修剪影响较小的连接来显著减少DNN模型的存储和计算成本,目前比较主流的剪枝方法主要有以下几种:
-
权重剪枝(weight pruning):此方法主要应用于对不重要的连接权重进行修剪。如果连接权重低于预先设定的某个阈值,则该连接权重将会被修剪(Han et al. 2015)。 -
神经元剪枝(neuron pruning):此方法与逐个修剪权重的方法不同,它直接移除某个冗余的神经元。这样一来,该神经元的所有传入和传出连接也将被移除(Srinivas and Babu 2015)。 -
卷积核剪枝(filter pruning):此方法依据卷积核的重要程度将其进行排序,并从网络中修剪最不重要/排名最低的卷积核。卷积核的重要程度可以通过或范数或一些其他方法计算(Li et al. 2016)。 -
层剪枝(layer pruning):此方法主要应用于一些非常深度的网络,可以直接修剪其中的某些层(Chen and Zhao 2018)。
按照剪枝的对象分类,可以分为在全连接层上剪枝和在卷积层上剪枝两种。DNN中的全连接层是存储密集的,对全连接层中的参数进行剪枝能够显著降低存储成本。对于卷积层而言,每个卷积层中都有许多卷积核,从卷积层修剪不重要的卷积核也能够减少计算成本并加速模型。
-
在全连接层上剪枝:考虑一个输入层、隐藏层和输出层分别具有3、2和1个神经元的前馈神经网络,如图3所示。
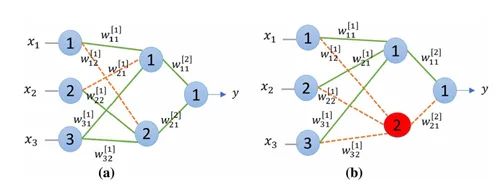
其中, 是网络的输入, 是从当前层中节点 的层 到下一层中的节点 的权重。从图3(a)可以清楚地看出,目前总共有8个连接权重,如果删除两个橙色(虚线)的连接,那么总连接权重将减少到6个。类似地,从图3(b)中,如果移除红色神经元,那么其所有相关的连接权重(虚线)也将被移除,导致总连接权重减少到4个(参数数量减少50%)。
-
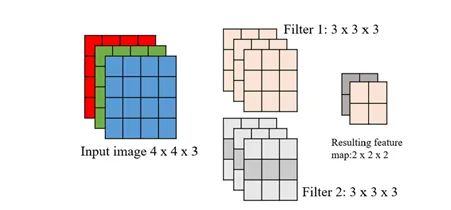
在卷积层上剪枝: 在卷积神经网络中, 卷积核 应用于每个输入的图像 , 并且经过卷积操作后输出特征映射 。其中, 和 是卷积核的尺寸, 是输入图像中输入通道的数量, 是应用的卷积核 的数量, 和 是输入图像的尺寸, 和 是结果特征映射的输出尺寸。输出特征映射的形状计算如下:
其中, 为步长 (stride), 为填充(padding)。图4显示了最简单的CNN形式,其 中输入图像的大小为 , 应用的卷积核大小为 (2是卷积核的数 量)。
受到早期剪枝方法和神经网络过度参数化问题的启发,Han et al.(2015)提出了三步法来进行剪枝。其思想是,首先修剪激活小于某个预定义阈值的所有连接权重(不重要的连接),随后再识别那些重要的连接权重。最后,为了补偿由于修剪连接权重而导致的精度损失,再次微调/重新训练剪枝模型。这样的剪枝和再训练过程将重复数次,以减小模型的大小,将密集网络转换为稀疏网络。这种方法能够对全连接层和卷积层进行修剪,而且卷积层比全连接层对修剪更加敏感。
从卷积层修剪一些不重要的卷积核能够直接减少计算成本并且加速模型。但是,使用网络剪枝方法同样存在着一些问题。首先,使用或正则化进行剪枝比常规方法需要更多的迭代次数才能收敛。其次,所有的剪枝都需要手动设置神经网络层的灵敏度,这需要对参数进行微调,在某些应用中可能会十分复杂。最后,网络剪枝虽然通常能够使大模型变小,但是却不能够提高训练的效率。
3.结构矩阵(structural matrix)
神经网络各层之间使用的是非线性变换 , 这里的 是对每个 元素特异的非线性算子, 是输入向量, 代表 维的参数矩阵, 此时的运算复 杂度为 (V. Sindhwani et al. 2015) 。一个直观的剪枝方法就是使用参数化的 结构矩阵。一个大小为 , 但是参数量却小于 的矩阵就叫做结构矩阵。Cheng et al. ( 2015 ) 提 出了一种 基于循环预测的简单方法, 对于一个向量 , 其对应的 维循环矩阵定义如下:
这样一来存储的成本就从O 变成了O 。给定 维 向量的条件下, 上式中的 一层循环神经网络的时间复杂度为 。
结构矩阵不仅能够降低内存成本,而且能够通过矩阵向量和梯度计算大幅度加快训练的速度。但是这种方法的缺点在于,结构约束通常会给模型带来偏差,从而损害模型的性能。再者,如何找到合适的结构矩阵也是一个难题,目前还没有理论上的方法能够推导出结构矩阵。
低秩因子分解(low-rank factorization)
低秩分解的思想是, 如果原始权重矩阵具有维数 和秩 , 则满秩矩阵可以分 解为一个 的权重矩阵和一个 的权重矩阵。该方法通过将大矩阵分解为小矩 阵, 以减小模型的尺寸。CNN通常由许多层组成, 每层都有一组权重矩阵, 这些权重 可以用张量 (Tensor) 来表示。图5展示了一个维数为 的三维张量。
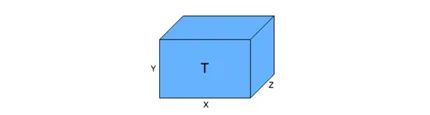
给定一个维数为 , 且有 个卷积核的卷积层, 其权重矩阵 可以表示为一个 维的张量 (Granés and Santamaria 2017) 。对于全连接层而言, 可以用矩阵 (2阶张量) 来表示。因此对权重矩阵进行分解就是对张量进行分解。张量分解指的是, 用标量 (O阶张量) 、向量 (1阶张量) 、矩阵 (2阶张量) 和一些其他高阶的张量来表示原始张量的方法。对矩阵可以应用满秩分解 (full-rank decomposition) 和奇异值分解 (singular value decomposition, SVD), 对三维及三维以上张量可以应用 Tucker 分解和 CP分解 (Canonical Polyadic) (Deng et al.2020) 。
1.对矩阵的分解
-
满秩分解。对任何给定的矩阵 , 其秩 , 则 的满秩分解可以表示为 , 其中 。如果 远小于 或 ,我们称 为低秩矩阵 (low-rank matrix) 。通过满秩分解可以将空间复杂度从 显著减小到 。特别地, 当 和 非常接近, 并且原始矩阵是行(或列) 满秩时, 这种减小空间复杂度的作用会失效。满秩分解方法对于全连接层十分有效, 特别是当两层之间的神经元数量相差很大或权重矩阵低秩稀疏时。给定一个较小的正整数 $k<r$, 可以通过如下的式子求解最优的="" $w="" \in="" r^{(m="" \times="" k)}$,$h="" r^{(k="" n)}$,="" 其中,="" $f$="" 表示frobenius范数。<="" section="">
-
SVD。SVD是一种将原始权重矩阵分解为三个较小的矩阵以替换原始权重矩阵的 方法。对于任意的矩阵 , 存在分解 , 其中, , 。 和 是正交矩阵, 是对角线上只有奇异值的对角矩 阵, 其中的每一个元素都比其下一个对角线上的元素大。这种方法可以使空间复 杂度从 减小到 。实际应用中, 可以用更小的 替换 , 这 种方法称为截断奇异值分解 (truncated SVD, TSVD) 。在前馈神经网络和卷积神 经网络中, SVD是一种常用的分解方法, 主要用于减少参数的个数。
2.对三维及三维以上张量的分解
-
Tucker分解。该方法是将TSVD方法中的对角矩阵扩展为张量的一种方法。TSVD和Tucker分解之间的关系可以用图6来表示:
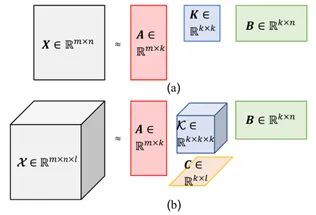
其中, 6 (a) 表示TSVD的过程, 6 (b) 表示Tucker分解的过程。定义对于 阶张量 和矩 阵 和 之间的乘积 是 , 并且 是一个 阶张量。有了这个前提, 对于一个 阶的张量 ,它能够被分解为一个核张量 和 个因子矩阵 , 其中 就是张量分 解所生成的矩阵的秩, 核张量与原始张量的阶数相同。则这个过程可以写成如下的形 式:
图6 (b) 展示的就是 时的Tucker分解过程, 其中 是待分解矩阵, 是核张 量矩阵, 为三个因子矩阵。
-
CP分解。该分解是Tucker分解的一种特殊形式。如果Tucker分解中的每个 等于正 整数 , 并且核张量 满足, 除了 之外 的所有元素都是 0 , 此时Tucker分解就成为了CP分解。与Tucker分解相比, CP分解 常用于解释数据的组成成分, 而前者主要用于数据压缩。图7展示了三阶张量 被 个组成部分分解的过程, 这个过程也可以用如下的公式来表示, 其中, (Marcella Astrid and Seung- and Ik Lee 2018)。
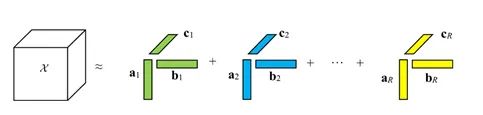
基于低秩近似的方法虽然是模型压缩和加速的前沿,然而具体实现却并非易事。因为这涉及到分解操作,需要付出高昂的计算成本。此外,当前的方法仍集中于逐层执行低秩近似,因此无法执行全局的参数压缩。但全局的参数压缩十分重要,因为不同的层包含不同的信息。最后,与原始的模型相比,因子分解需要对大量的模型进行再训练以实现收敛。
迁移/压缩卷积滤波器(transferred/compact convolutional filters)
Cohen and Welling (2016) 提出了使用卷积滤波器压缩CNN模型的想法, 并在 研究中引入了等变群理论 (the equivariant group theory)。让 作为输入, 作为 一个神经网络或者网络层, 作为迁移矩阵, 则等价的概念定义如下:
这样的定义指的是, 迁移矩阵 先对输入x进行变换, 再将其传输到 所得到 的结果应该跟先将输入 映射到神经网络 上再做变换 得到的结果相同。值得注 意的是, 和 不一定相同, 因为它们作用在不同的对象上。根据这样的理论, 通过将变换应用于层或者滤波器 来压缩整个网络模型就十分合理。从经验来看, 使用一组大的卷积滤波器也对深层CNN有益, 具体方法是将一些变换 应用于一组 充当模型正则化器的小型基滤波器上。
沿着这一研究方向, 近期的许多研究提出了从一组基滤波器出发构建卷积层的思 想。它们的共同点是, 迁移矩阵 是只在卷积滤波器的空间域中操作的一类函数。例如, Shang et al. (2016) 发现, CNN的较低卷积层通过学习㐌余的滤波器来提取 输入信号的正负相位信息, 并将 定义为简单的否定函数:
其中, 是基础的卷积滤波器, 是由激活与 相反的移位 (shift) 构成的滤波 器, 并且这些移位是在最大池 (max-pooling) 操作后选择的。通过这样操作, 就可以 很容易的实现在所有卷积层上的二倍压缩率。它还表明, 否定变换作为一个强大的正 则化方法, 能够用以提高分类精度。一种直观的理解是, 具有成对正负约束的学习算 法可以产生实用而不是冗余的的卷积滤波器。此外, Zhai et al. (2016) 将 定义为 应用于 2 维滤波器的平移函数集:
其中, 表示第一个操作数沿其空间维度平移 , 并在边界处进行适当的零 填充以保持形状。提出的框架可用于公式 (1) 改善分类精度的问题, 进而作为 maxout网络的正则化版本。
对于将变换约束应用于卷积滤波器的方法,还有几个问题需要解决。首先,这些方法可以在宽/平的架构(如VGGNet,AlexNet)上实现有竞争力的性能,但是在窄/深的架构(如ResNet)上则不行。其次,迁移假设有时太强,无法指导学习过程,导致得到的结果在某些情况下不稳定。此外,使用紧凑的卷积滤波器虽然可以直接降低计算成本,但关键思想是要用紧凑的块替换松散的和过度参数化的滤波器以提高计算速度。
蒸馏学习(knowledge distillation)
蒸馏学习(knowledge distillation,KD)是指通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度。KD与迁移学习(transfer learning)不同,在迁移学习中,我们使用相同的模型体系结构和学习的权重,仅根据应用的要求使用新层来替换部分全连接层。而在KD中,通过在大数据集上训练的更大的复杂网络(也称之为教师模型(teacher model))学习到的知识可以迁移到一个更小、更轻的网络上(也称之为学生模型(student model))。前一个大模型可以是单个的大模型,也可以是独立训练模型的集合。KD方法的主要思想是通过softmax函数学习课堂分布输出,将知识从大型教师模型转换为一个更小的学生模型。从教师模型训练学生模型的主要目的是学习教师模型的泛化能力。
在现有的KD方法中,学生模型的学习依赖于教师模型,是一个两阶段的过程。Lan et al.(2018)提出了实时本地集成(On-the-fly Native Ensemble,ONE),这是一种高效的单阶段在线蒸馏学习方法。在训练期间,ONE添加辅助分支以创建目标网络的多分支变体,然后从所有分支中创建本地集成教师模型。对于相同的目标标签约束,可以同时学习学生和每个分支。每个分支使用两个损失项进行训练,其中最常用的就是最大交叉熵损失(softmax cross-entropy loss)和蒸馏损失(distillation loss)。
在网络压缩这一步,可以使用深度神经网络方法来解决这个问题。Romero et al.(2015)提出了一种训练薄而深的网络的方法,称为FitNets,用以压缩宽且相对较浅(但实际上仍然很深)的网络。该方法扩展了原来的思想,允许得到更薄、更深的学生模型。为了学习教师网络的中间表示,FitNet让学生模仿老师的完全特征图。然而,这样的假设太过于严格,因为教师和学生的能力可能会有很大的差别。
基于蒸馏学习的方法可以使模型的深度变浅,并且能够显著降低计算成本。然而,这个方法也存在一些弊端。其中之一是KD方法只能应用于具有softmax损失函数的任务中。再者就是,与其他类型的方法相比,基于蒸馏学习的方法往往具有较差的竞争性能。
面临的问题
在文章的最后一部分,作者总结了现有的这些模型压缩和加速的方法仍然面临的一些问题与挑战,主要有以下几个方面:
-
当前的大多数先进方法建立在精心设计的CNN模型之上,这些模型限制了更改配置的自由度(例如,网络架构、超参数等)。为了处理更复杂的任务,未来应该提供更加合理的方法来配置压缩模型。 -
各种小型平台(例如移动设备、机器人、自动驾驶汽车等)的硬件限制仍然是阻碍深层CNN扩展的主要问题。如何充分利用有限的计算资源以及如何为这些平台设计特殊的压缩方法仍然是需要解决的问题。 -
剪枝是压缩和加速CNN的有效方法。目前的剪枝技术大多是为了修剪神经元之间的连接而设计的。此外,对通道进行剪枝能够直接减少特征映射的宽度并压缩模型。这种方法虽然很有效,但是修剪通道可能会显著地改变下一层的输入,因此也存在挑战性。 -
如前所述,结构矩阵和迁移卷积滤波器的方法必须使模型具有人类的先验知识,这将会显著影响模型的性能和稳定性。研究如何控制强加这些先验知识带来的影响至关重要。 -
蒸馏学习的方法具有很多的优点,比如无需特定的硬件就能够直接加速模型。开发基于KD的更多方法并且探索如何提高其性能是未来主要的发展方向。 -
尽管这些压缩方法取得了巨大的成就,但是黑箱机制(black box mechanism)仍然是其应用的关键障碍。比如,某些神经元/连接被修剪的原因尚不清楚。探索这些方法的解释能力仍然是一个重大挑战。
参考文献
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



