Transformers+世界模型,竟能拯救深度强化学习?
新智元报道
新智元报道
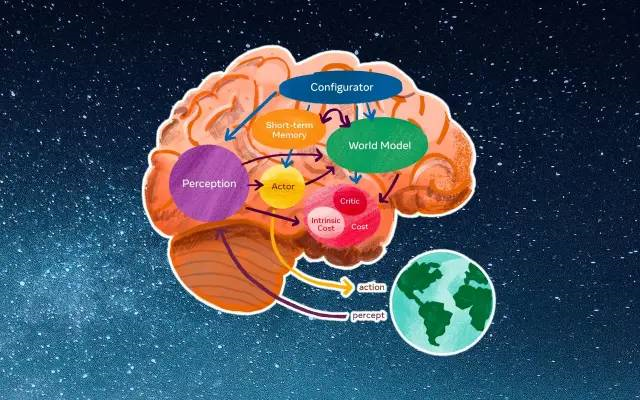
【新智元导读】前一段时间,LeCun曾预言AGI:大模型和强化学习都没出路,世界模型才是新路。但最近,康奈尔大学有研究人员,正试着用Transformers将强化学习与世界模型连接起来。

深度强化学习有什么不一样
Transformers有什么神奇之处
Transformers首次亮相于2017年,是Google的论文《Attention is All You Need》中提出的。
世界模型与Transformers联手,其他人怎么看

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月26日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月26日