编辑:好困 拉燕
【新智元导读】LeCun刚刚发表完自己以AI为基构建「世界模型」的设想,随即就引发了大量的讨论。众多网友表示,这个概念早就提出过了。
2月24日,Meta在「春晚」上介绍了首席科学家Yann LeCun在构建人类级别的AI勾勒出的另一种愿景。
LeCun表示,AI学习「世界模型」(世界如何运作的内部模型)的能力可能是关键。
然而,文章一出,便遭到了很多业内人士的质疑,这不是老早就有了的东西么?
多伦多大学的副教授Dan Roy指出,「我好像记得Josh Tenenbaum确实提过世界模型。当然也可能我记错了。」
卡内基梅隆大学计算机科学教授、前苹果人工智能研究主任Russ Salakhutdinov随即跟帖表示:
「我十年前从事博士后研究时,Josh Tenenbaum和很多人就已经在搞世界模型了。所以今天Facebook说他们要描绘一个以AI为基础的世界模型,我听着就觉得挺逗的。」
甚至有网友搬出了Jürgen Schmidhuber在1990年发表的论文,其中就有关于世界模型的介绍。
论文地址:
https://mediatum.ub.tum.de/doc/814960/file.pdf
另有热心网友在下面附上了他2018年在NIPS上发表的一篇有关世界模型的论文的链接。
论文地址:
https://arxiv.org/abs/1809.01999
项目地址:
https://worldmodels.github.io/
被推上风口浪尖的LeCun,不得不亲自下场:这和Facebook没啥关系,是我自己提出的,况且应该是Meta。
他表示,「确实有很多人聊世界模型聊了几十年了,自打上个世纪60年代的控制论开始。但提出这个概念不是关键,关键在于到底怎样构建和训练世界模型。」
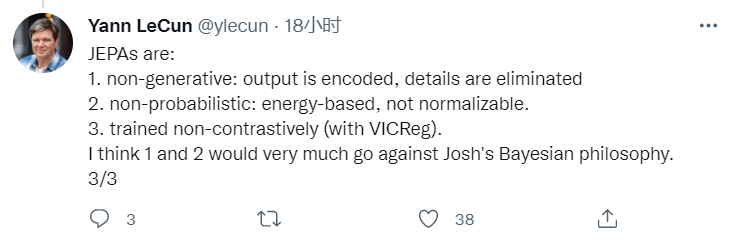
也就是如何让世界模型学习分级表示法,并且实现分级规划。我认为这里创新的点就在于使用联合嵌入型预测架构(JEPA)在表征空间中进行预测。
非生成性——输出是被加密的,细节都被省掉。
非概率性——是基于能量的,不是可规范化的。
非对比训练(用VICR)
我认为第一个和第二个特点大概率会有悖于Josh的贝叶斯定理。
他表示,「确实,训练是个问题。对于一个离开自己原来的工作,去搞世界模型的人来说,他们可能会从物理学家、控制理论专家和人工智能的角度去构思,这样的话这些视角很难帮他们做什么...哪怕你搭建了一个机器,也学了一些特定领域的世界模型,你还是很难做出一款现象级的软件。」
人类会根据自己有限的感官所能感知到的事物,去建立了一个关于世界的模型。
在此之后,人类做出的所有决定和行动都将基于这个内部模型的。
而这个模型并不只是泛泛地预测未来,而是根据我们当前的运动和行动对未来的感官数据进行预测。
当面临危险时,人类能够本能地根据这个预测模型采取行动,并进行快速的反射性行为,而不需要有意识地计划出行动方案。
LeCun指出:「人类学习在世界如何运作的背景知识时,是通过观察,以及用独立于任务和无监督方式进行的。可以假定,这种积累的知识可能构成了通常被称为常识的基础。」
常识可以被视为世界模型的集合,可以指导智能体何种行为可能、何种行为合理、何种行为不可能。
这使人类能够在不熟悉的情况中有效地预先计划。例如,一名少年司机以前可能从未在雪地上驾驶,但他预知雪地会很滑、如果车开得太猛将会失控打滑。
常识性知识让智能动物不仅可以预测未来事件的结果,还可以在时间或空间上填补缺失的信息。当司机听到附近有金属撞击声时,即使没有看到撞车现场,他也能立即知道车祸发生。
就像首次接触左侧驾驶的人,不用再重复学习方向盘该怎么打一样,物理法则是不会改变的,而这就是个「世界模型」的例子。
早在1990年,就有研究人员开始尝试建立一个完全依靠自己来学习世界表征的智能体。
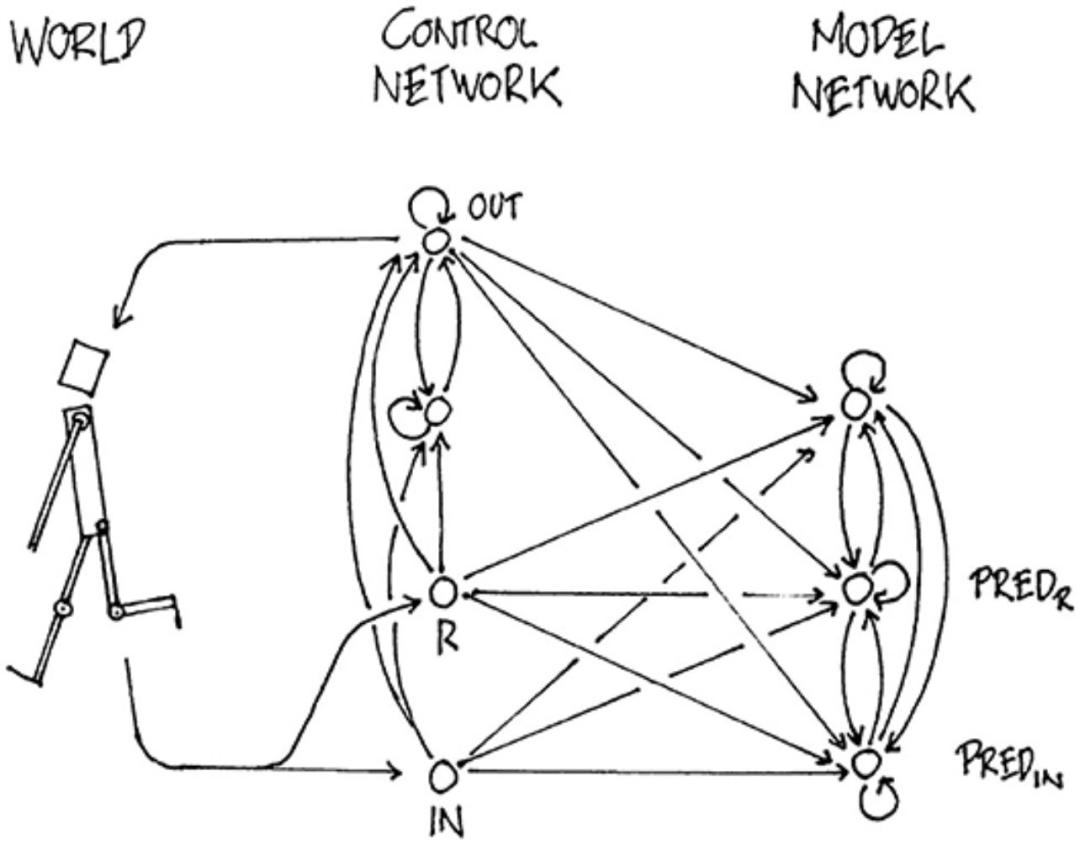
Schmidhuber的模型指出,智能体可以从世界接收奖励R和输入IN。输入在经过网络处理后,模型会分别对世界和未来的奖励进行预测——PREDIN,PREDR。最后,动作通过OUT输出。
也就是说,这个智能体对于未来的奖励和输入是使用世界模型预测的。
Schmidhuber的模型遵循的是压缩神经表征的思想,而压缩也是归纳推理的关键,即从少数例子中学习,这通常被认为是智能才有的行为。
然而,Schmidhuber在这个方法中缺少一个关于如何分析智力和意识的理论。
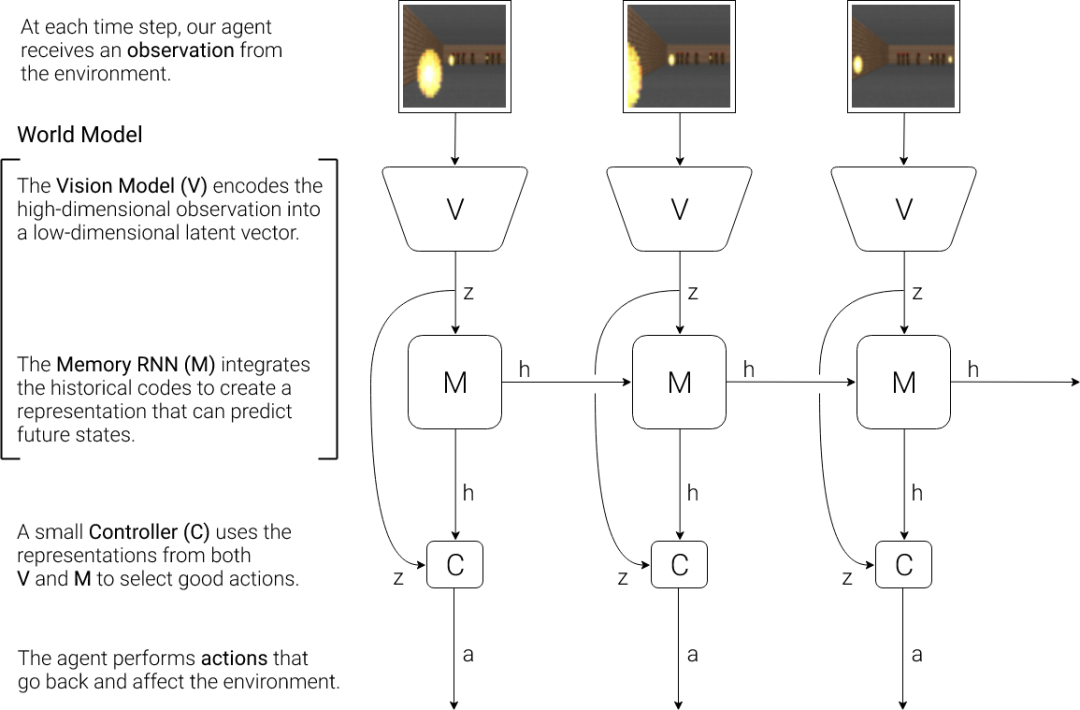
在2018年的论文中,Schmidhuber再次提出了一个受人类认知系统启发的简单模型。
在这个模型中,智能体有一个视觉感觉组件,将它看到的东西压缩成一个小的代表代码。还有一个记忆组件,根据历史信息对未来的代码进行预测。最后是一个决策组件,只根据其视觉和记忆组件所创建的表征来决定采取什么行动。
智能体由三个组件组成:视觉(V),记忆(M),和控制器(C)
在这项工作中,Schmidhuber首先训练一个大型神经网络,以无监督的方式学习智能体的世界模型,然后训练较小的控制器模型,学习使用这个世界模型来执行任务。
其中,控制器让训练算法专注于小的搜索空间上的信用分配问题,同时不牺牲通过大的世界模型的能力和表现力。
在通过世界模型的视角进行训练之后,Schmidhuber证明,智能体可以学习一个高度紧凑的策略来执行其任务。
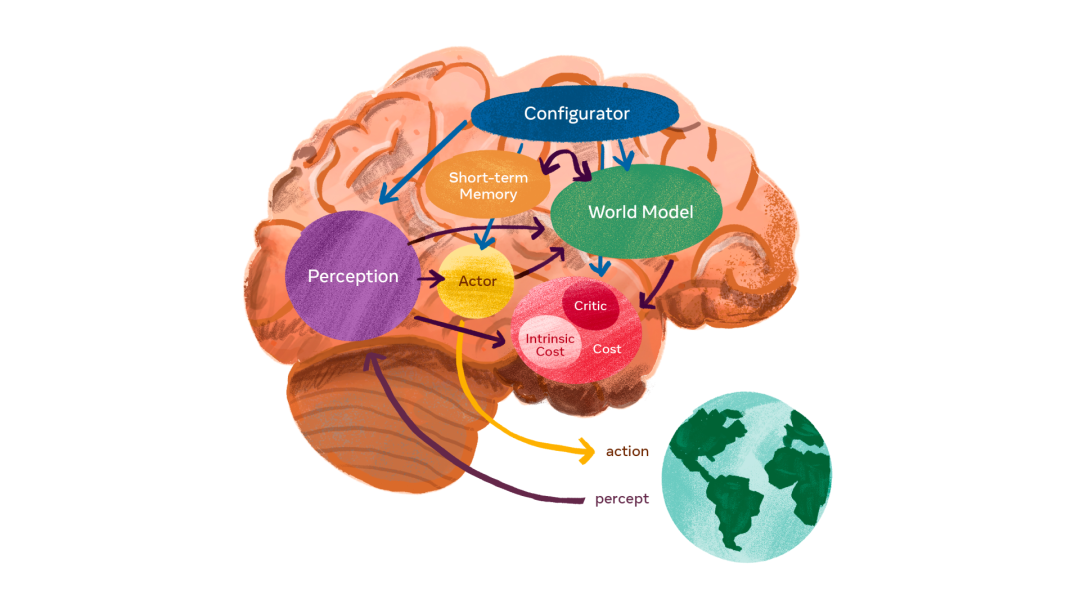
LeCun在自己的「世界模型」中提出了一个由六个独立模块组成的架构。
-
-
感知模块负责接收来自传感器的信号并估计世界的当前状态。
-
世界模型模块的作用有两点:(1)补全感知模块没有提供的信息;(2)预测合理的未来状态。
-
代价模块负责计算和预测智能体的不合适程度。由两个部分组成:(1)内在代价,直接计算「不适」:对智能体的损害、违反硬编码的行为等;(2)评价者,预测内在代价的未来值。
-
-
短期记忆模块负责跟踪当前和预测的世界状态,以及相关代价。
自主智能架构的核心是预测世界模型。而建构它的关键挑战,是如何能使其呈现多种可能性的预测。
现实世界并不是完全可以单一预测的,特定情况的演变有多种可能途径,并且状况的许多细节与当下任务无关。
人类司机可能需要预测驾驶时自己周围的汽车会做什么,但不需要预测道路附近树木中单个叶子的详细位置。
世界模型如何学习现实世界的抽象表示,从而保留关键细节、忽略不相关细节,且能在抽象表示的空间中进行预测?
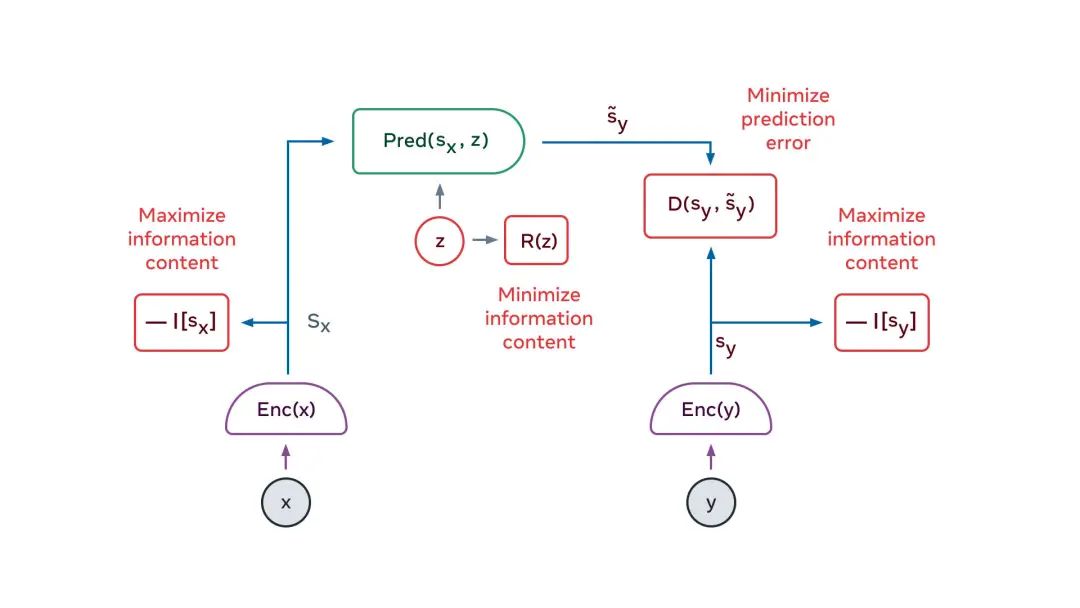
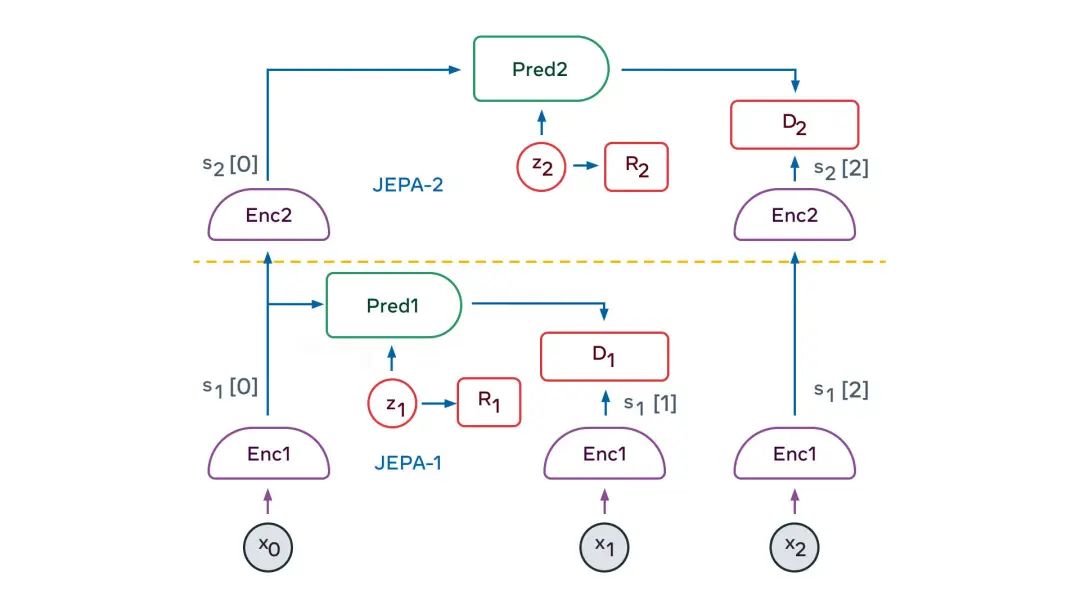
解决方案的关键要素是「联合嵌入式可预测架构」 (JEPA)。
JEPA能捕获两个输入数据x和y之间的依赖关系。例如,x可以是一段视频,y可以是视频的下一段。输入数据x和y被馈送到可训练的编码器,这些编码器提取它们的抽象表示,即sx和sy。
JEPA以两种方式处理预测中的不确定性:(1)编码器可能会抛弃关于y的难以预测信息,(2)当潜在变量z在一个集合上有变化时,将导致在另一个可能性集合上的预测结果有变化。
直到晚近,唯一的途径是使用对比方法,即提供足够多的兼容x和y的示例、兼容x但不兼容y的示例、不兼容x但兼容y的示例。
过去两年出现了另一种训练策略:正则化方法。当应用于JEPA时,该方法使用四个准则:
-
-
-
-
使预测器调用来自潜在变量的尽可能少的信息,来表示预测中的不确定性。
这些准则可以通过VICReg,也就是「方差、不变性、协方差正则化」(Variance, Invariance, Covariance Regularization)方法,转化为可微的代价函数。
其中,x和y表示的信息内容最大化方式,是将其分量的方差保持在阈值之上,并使这些分量尽可能地相互独立。
同时,此方法试图让y的表征可以从x的表示中预测,而潜变量的信息内容,则被使其离散、低维、稀疏或噪声化的方式最小化。
JEPA的妙处,在于它自然地产生了关于输入信息的抽象表示,这些抽象表示消除了不相关的细节,基于其可以执行预测。
这使得JEPA可以相互堆叠,用来学习具有更高层次的、能藉以执行更长期预测的抽象表示。
例如,一个场景可以在高层次上抽象描述为「厨师正在制作法式薄饼」。
因此,人类智能可以预测:厨师会去取面粉、牛奶和鸡蛋;混合原料;把面糊舀进锅里;让面糊油炸;翻转薄饼;重复以上流程。
在低一级的层次上,人类智能可以预测:舀面糊动作,包括勺子舀面糊、倒进锅里、将面糊铺在锅面上。
这种层级的摊低可以一直持续到以毫秒为单位的厨师手部的精确运动轨迹。
在手部轨迹的低层次上,「世界模型」只能在短期内做出准确的预测。但在更高的抽象层次上,它可以做出长期的预测。
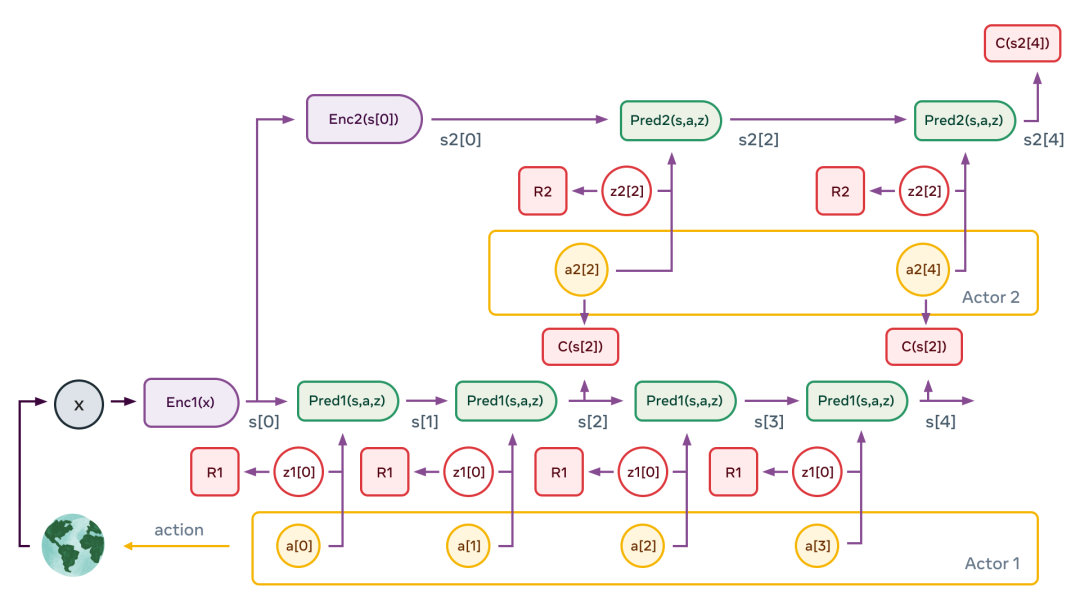
多层JEPA可用于在多个抽象级别和多个时间尺度上执行预测。训练的主要途径是被动观察,辅助途径是与环境互动。
正如婴儿在出生后头几个月,主要通过观察来了解世界是如何运作的。她了解到世界是三维的、有些物体排在其他物体的前面、当一个物体被遮挡时它仍然存在。
最终,在大约9个月大的时候,婴儿学会了直观的物理学——例如,不受支撑的物体会因重力而落下。
多层JEPA有望通过类似的观看视频、与环境交互等方式,来了解世界是如何运作的。
通过自训练来预测视频中会发生什么,它将产生世界的分层级表示。通过在现实世界上采取行动并观察结果,「世界模型」将学会预测其行动的后果,这将使其能够进行推理和计划。
在LeCun看来,我们应该让机器通过观察来学会现实世界中的最基础定律,这是让机器学习世界模型的最主要途径。
而对于现在的人工智能来说,最重要的挑战之一就是设计学习范式和架构,使起能够以自监督的方式学习世界模型,然后用这些模型进行预测、推理和计划。
或许,这个概念并没有想象中的那么「新」,但如何真正应用于实践,可能还有很长的一条路要走。
参考资料:
https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research/
https://twitter.com/rsalakhu/status/1496677311290167302
https://twitter.com/ylecun/status/1496750102609809410
![]()