小米流式平台架构演进与实践
背景介绍
小米流式平台发展历史
基于 Flink 的实时数仓
未来规划
背景介绍
-
流式数据存储: 流式数据存储指的是消息队列,小米开发了一套自己的消息队列,其类似于 Apache kafka,但它有自己的特点,小米流式平台提供消息队列的存储功能; -
流式数据接入和转储: 有了消息队列来做流式数据的缓存区之后,继而需要提供流式数据接入和转储的功能; -
流式数据处理: 指的是平台基于 Flink、Spark Streaming 和 Storm 等计算引擎对流式数据进行处理的过程。

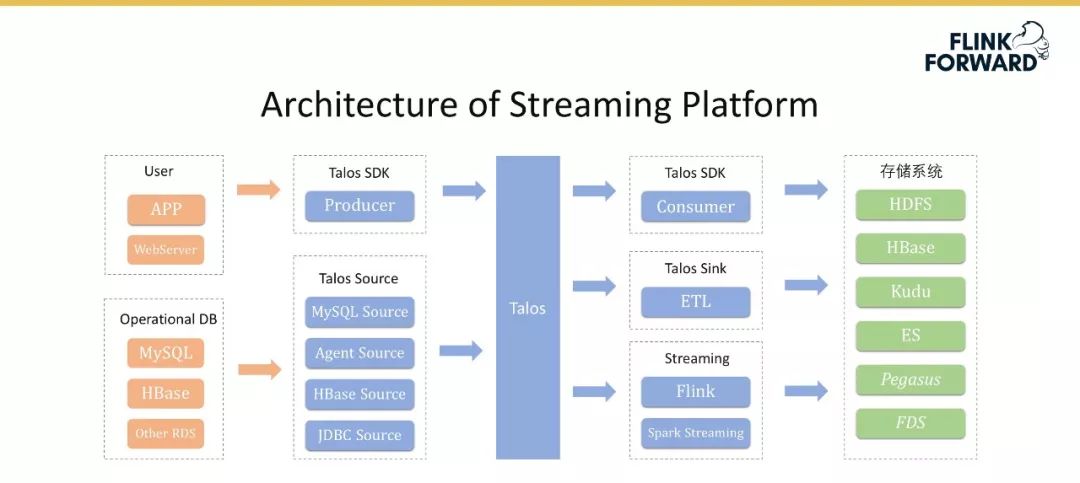
User 指的是用户各种各样的埋点数据,如用户 APP 和 WebServer 的日志,其次是 Database 数据,如 MySQL、HBase 和其他的 RDS 数据。
中间蓝色部分是流式平台的具体内容,其中 Talos 是小米实现的消息队列,其上层包含 Consumer SDK 和 Producer SDK。
此外小米还实现了一套完整的 Talos Source,主要用于收集刚才提到的用户和数据库的全场景的数据。

小米流式平台发展历史
-
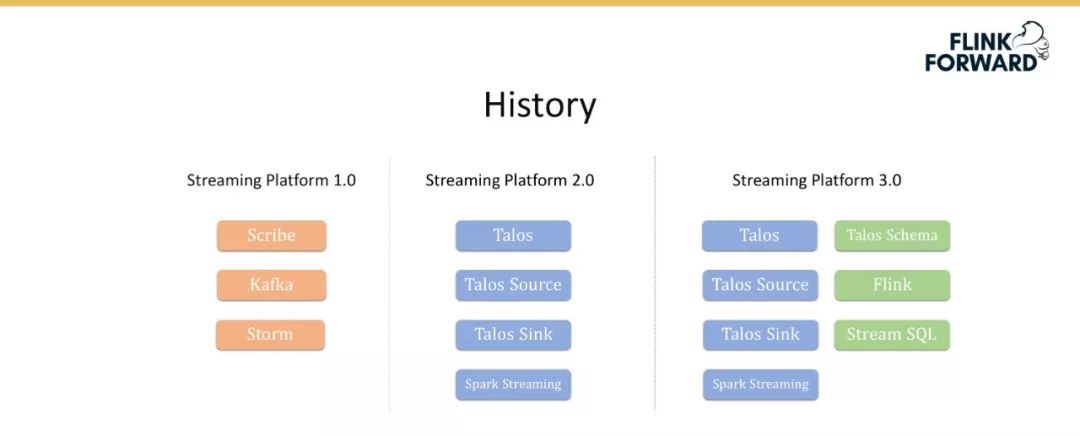
Streaming Platform 1.0 :小米流式平台的 1.0 版本构建于 2010 年,其最初使用的是 Scribe、Kafka 和 Storm,其中 Scribe 是一套解决数据收集和数据转储的服务。 -
Streaming Platform 2.0 :由于 1.0 版本存在的种种问题,我们自研了小米自己的消息队列 Talos,还包括 Talos Source、Talos Sink,并接入了 Spark Streaming。 -
Streaming Platform 3.0 :该版本在上一个版本的基础上增加了 Schema 的支持,还引入了 Flink 和 Stream SQL。
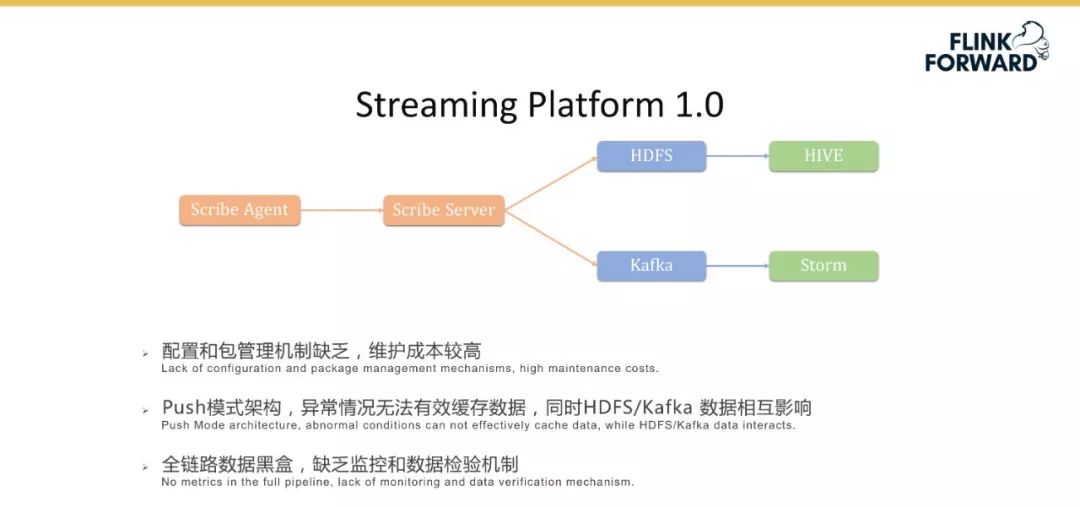
首先是 Scribe Agent 过多,而配置和包管理机制缺乏,导致维护成本非常高;
Scribe 采用的 Push 架构,异常情况下无法有效缓存数据,同时 HDFS / Kafka 数据相互影响;
最后数据链级联比较长的时候,整个全链路数据黑盒,缺乏监控和数据检验机制。
由于 Agent 自身数量及管理的流较多(具体数据均在万级别),为此该版本实现了一套配置管理和包管理系统,可以支持 Agent 一次配置之后的自动更新和重启等。
此外,小米还实现了去中心化的配置服务,配置文件设定好后可以自动地分发到分布式结点上去。
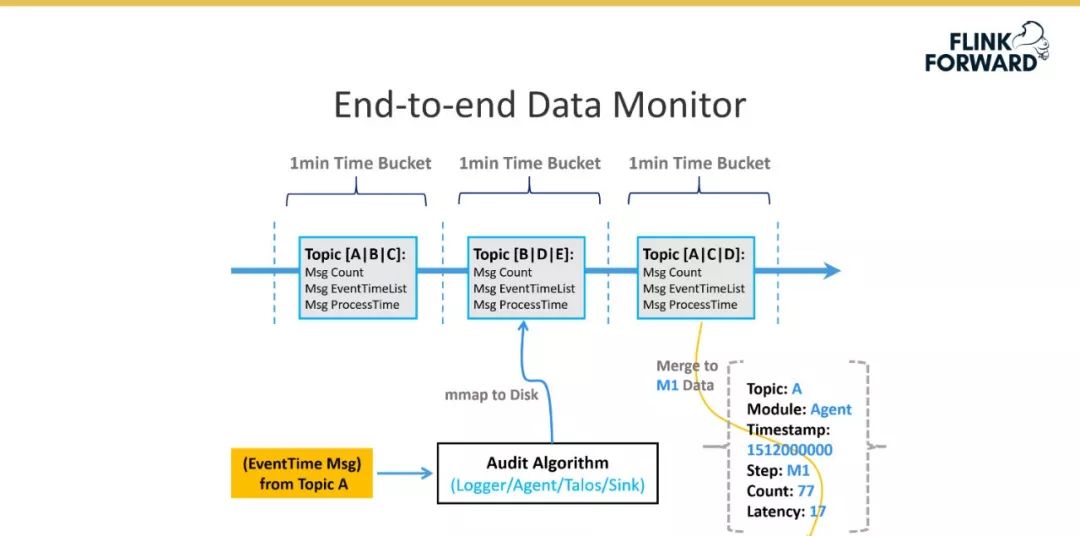
最后,该版本还实现了数据的端到端监控,通过埋点来监控数据在整个链路上的数据丢失情况和数据传输延迟情况等。
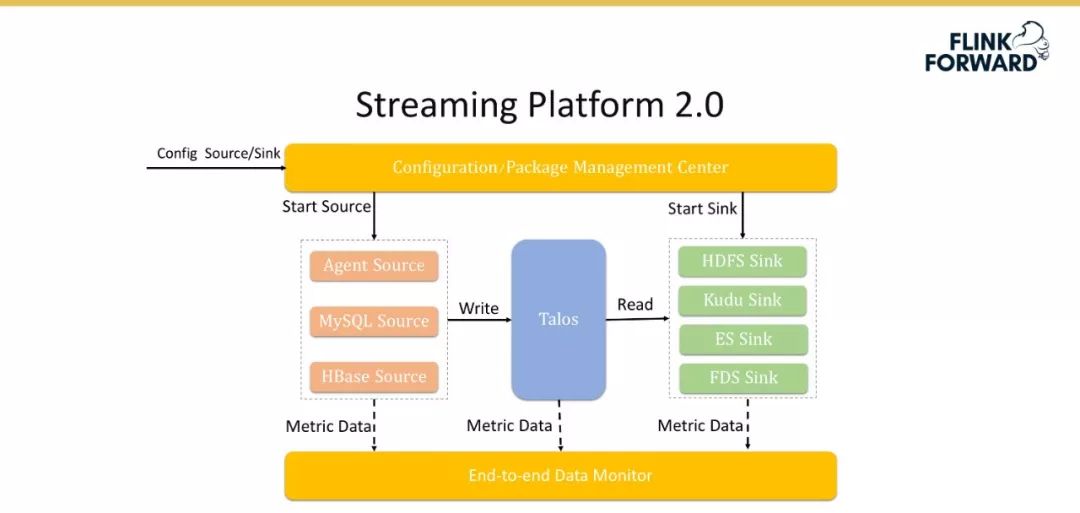
-
引入了 Multi Source & Multi Sink,之前两个系统之间导数据需要直接连接,现在的架构将系统集成复杂度由原来的 O(M*N) 降低为 O(M+N); -
引入配置管理和包管理机制,彻底解决系统升级、修改和上线等一系列问题,降低运维的压力; -
引入端到端数据监控机制,实现全链路数据监控,量化全链路数据质量; -
产品化解决方案,避免重复建设,解决业务运维问题。

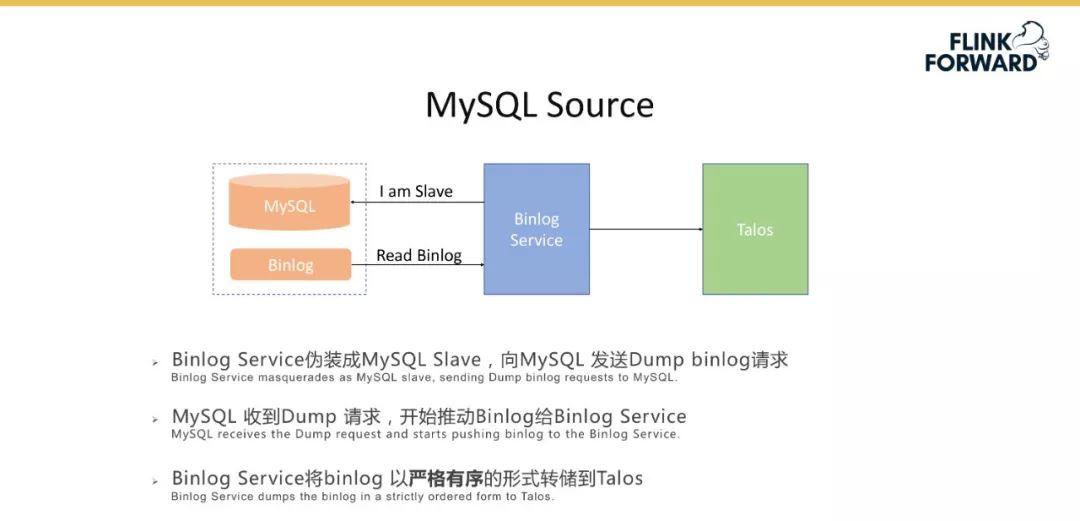
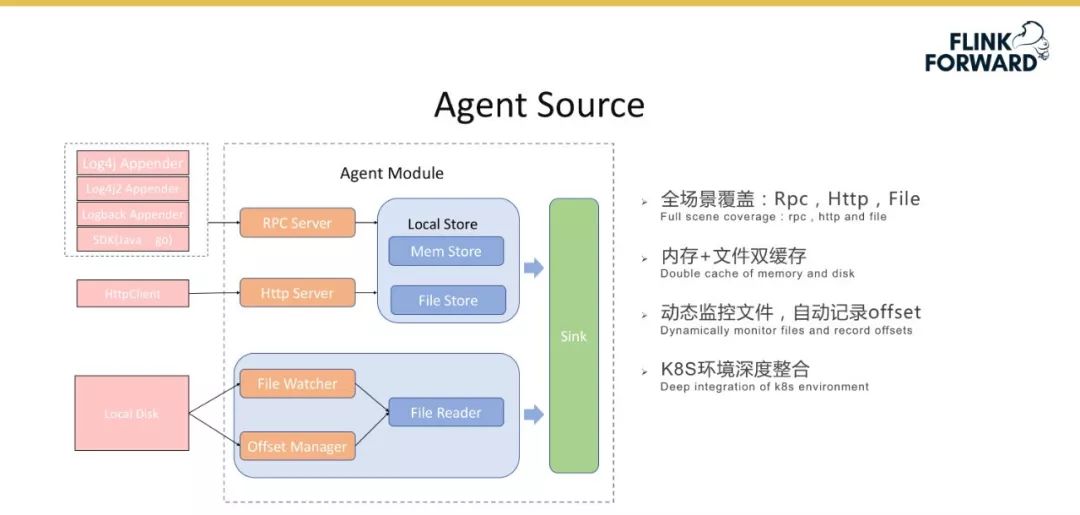
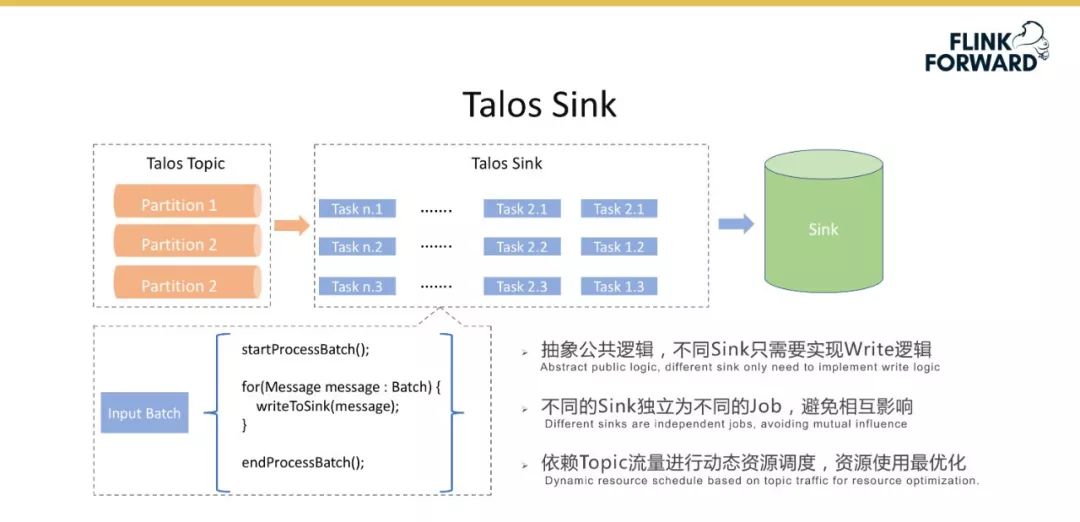
-
Talos 数据缺乏 Schema 管理,Talos 对于传入的数据是不理解的,这种情况下无法使用 SQL 来消费 Talos 的数据; -
Talos Sink 模块不支持定制化需求,例如从 Talos 将数据传输到 Kudu 中,Talos 中有十个字段,但 Kudu 中只需要 5 个字段,该功能目前无法很好地支持; -
Spark Streaming 自身问题,不支持 Event Time,端到端 Exactly Once 语义。

基于 Flink 的实时数仓
-
全链路 Schema 支持 ,这里的全链路不仅包含 Talos 到 Flink 的阶段,而是从最开始的数据收集阶段一直到后端的计算处理。需要实现数据校验机制,避免数据污染;字段变更和兼容性检查机制,在大数据场景下,Schema 变更频繁,兼容性检查很有必要,借鉴 Kafka 的经验,在 Schema 引入向前、向后或全兼容检查机制。 -
借助 Flink 社区的力量全面推进 Flink 在小米的落地,一方面 Streaming 实时计算的作业逐渐从 Spark、Storm 迁移到 Flink,保证原本的延迟和资源节省,目前小米已经运行了超过 200 个 Flink 作业;另一方面期望用 Flink 改造 Sink 的流程,提升运行效率的同时,支持 ETL,在此基础上大力推进 Streaming SQL; -
实现 Streaming 产品化 ,引入 Streaming Job 和 Streaming SQL 的平台化管理; -
基于 Flink SQL 改造 Talos Sink ,支持业务逻辑定制化

-
抽象 Table :该版本中各种存储系统如 MySQL 和 Hive 等都会抽象成 Table,为 SQL 化做准备。 -
Job 管理: 提供 Streaming 作业的管理支持,包括多版本支持、配置与Jar分离、编译部署和作业状态管理等常见的功能。 -
SQL 管理 :SQL 最终要转换为一个 Data Stream 作业,该部分功能主要有 Web IDE 支持、Schema 探查、UDF/维表 Join、SQL 编译、自动构建 DDL 和 SQL 存储等。 -
Talos Sink :该模块基于 SQL 管理对 2.0 版本的 Sink 重构,包含的功能主要有一键建表、Sink 格式自动更新、字段映射、作业合并、简单 SQL 和配置管理等。前面提到的场景中,基于 Spark Streaming 将 Message 从 Talos 读取出来,并原封不动地转到 HDFS 中做离线数仓的分析,此时可以直接用 SQL 表达很方便地实现。未来希望实现该模块与小米内部的其他系统如 ElasticSearch 和 Kudu 等进行深度整合,具体的场景是假设已有 Talos Schema,基于 Talos Topic Schema 自动帮助用户创建 Kudu 表。 -
平台化 :为用户提供一体化、平台化的解决方案,包括调试开发、监控报警和运维等。

Job 管理

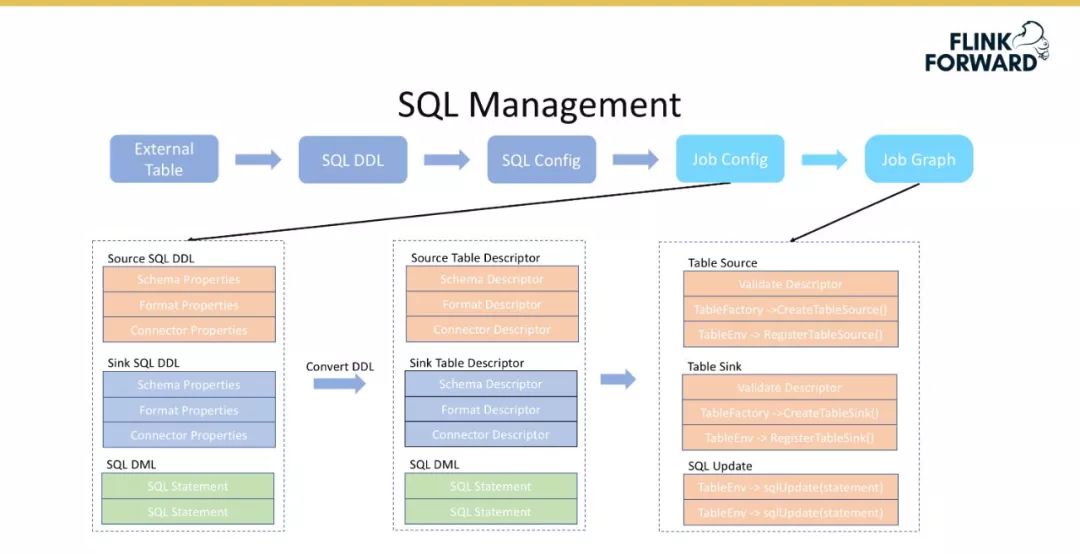
SQL 管理
-
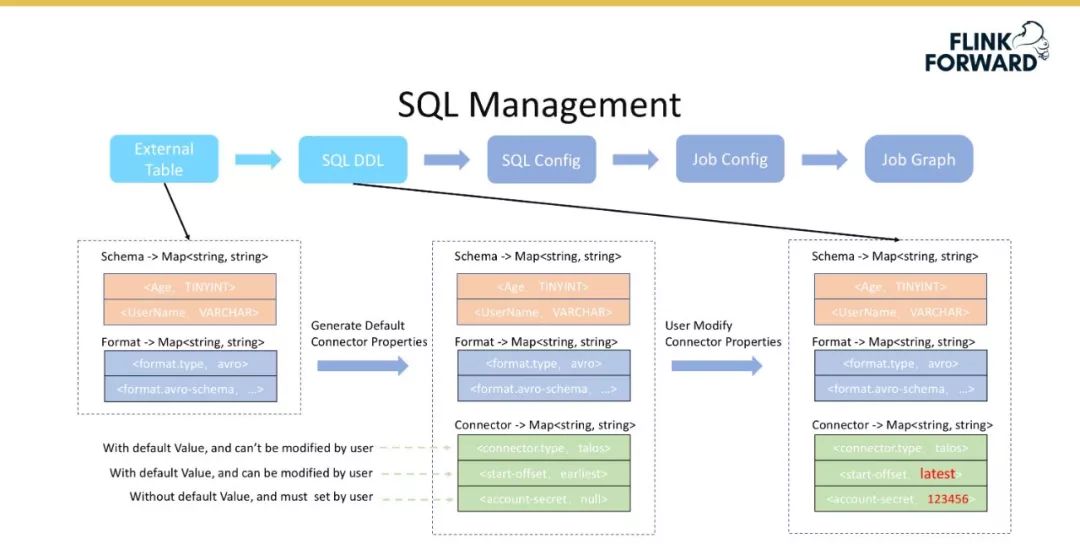
将外部表转换为 SQL DDL,对应 Flink 1.9 中标准的 DDL 语句,主要包含 Table Schema、Table Format 和 Connector Properities。 -
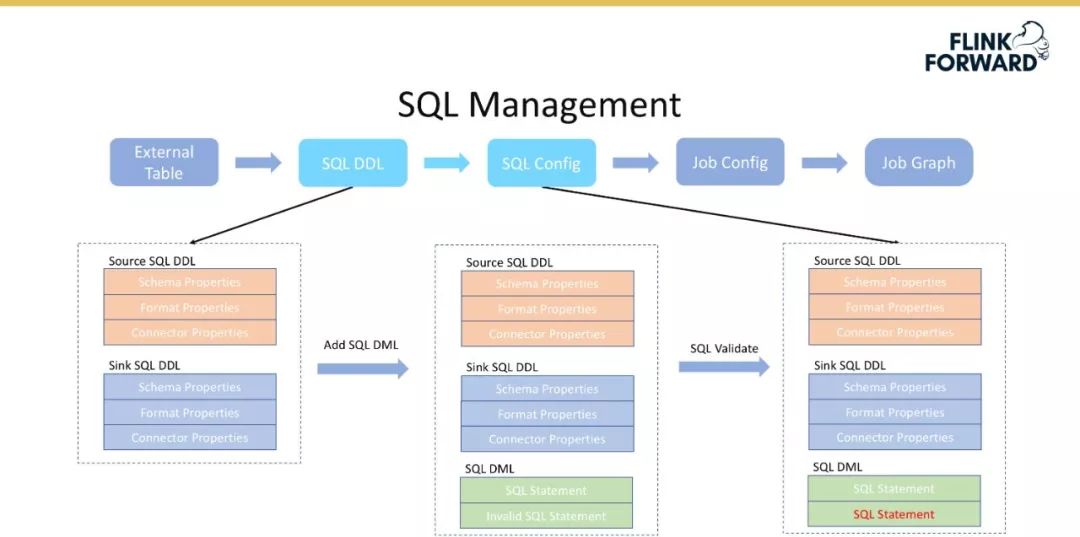
基于完整定义的外部 SQL 表,增加 SQL 语句,既可以得到完成的表达用户的需求。即 SQL Config 表示完整的用户预计表达,由 Source Table DDL、Sink Table DDL 和 SQL DML语句组成。 -
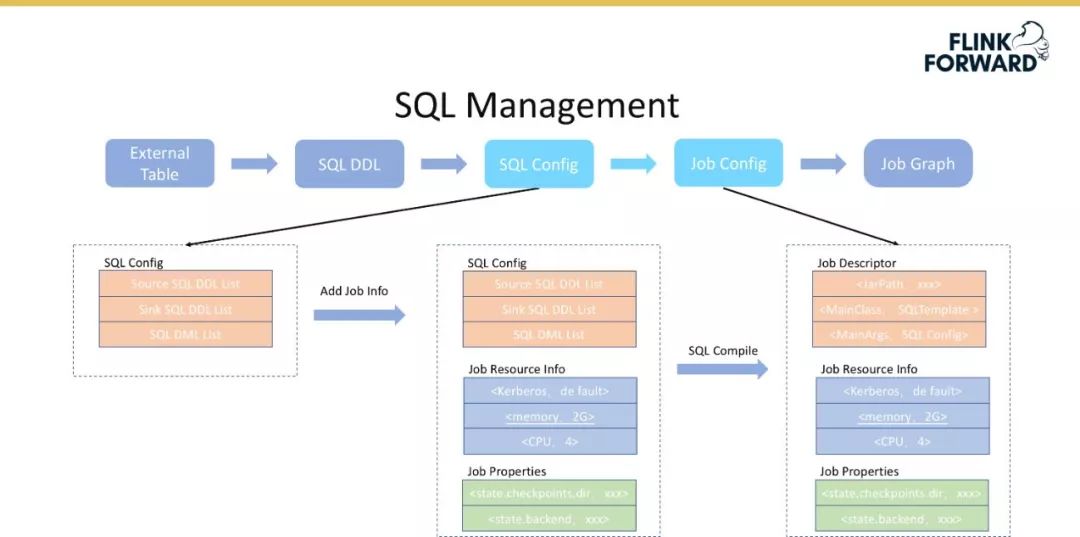
将 SQL Config 转换成 Job Config,即转换为 Stream Job 的表现形式。 -
将 Job Config 转换为 JobGraph,用于提交 Flink Job。

首先根据外部表获取 Table Schema 和 Table Format 信息,后者用于反解数据,如对于 Hive 数据反序列化;
然后再后端生成默认的 Connector 配置,该配置主要分为三部分,即不可修改的、带默认值的用户可修改的、不带默认值的用户必须配置的。

首先在 SQL Config 的基础上增加作业所需要的资源、Job 的相关配置(Flink 的 state 参数等);
然后将 SQLConfig 编译成一个 Job Descriptor,即 Job Config 的描述,如 Job 的 Jar 包地址、MainClass 和 MainArgs 等。

-
Row :Talos 的数据原封不动地灌到目标系统中,这种模式的好处是数据读取和写入的时候无需进行序列化和反序列化,效率较高; -
ID mapping :即左右两边字段进行 mapping,name 对应 field_name,timestamp 对应 timestamp,其中 Region 的字段丢掉; -
SQL :通过 SQL 表达来表示逻辑上的处理。

未来规划
-
在 Flink 落地的时候持续推进 Streaming Job 和平台化建设; -
使用 Flink SQL 统一离线数仓和实时数仓; -
在 Schema 的基础上数据血缘分析和展示,包括数据治理方面的内容; -
持续参与 Flink 社区的建设。