26秒单GPU训练CIFAR10,Jeff Dean也点赞的深度学习优化技巧
选自myrtle.ai
26 秒内用 ResNet 训练 CIFAR10?一块 GPU 也能这么干。近日,myrtle.ai 科学家 David Page 提出了一大堆针对数据预处理、模型架构、训练和测试方面的优化方法,有了它们,加速训练你也可以。
colab地址:https://colab.research.google.com/github/davidcpage/cifar10-fast/blob/master/bag_of_tricks.ipynb
博客地址:https://myrtle.ai/how-to-train-your-resnet-8-bag-of-tricks/
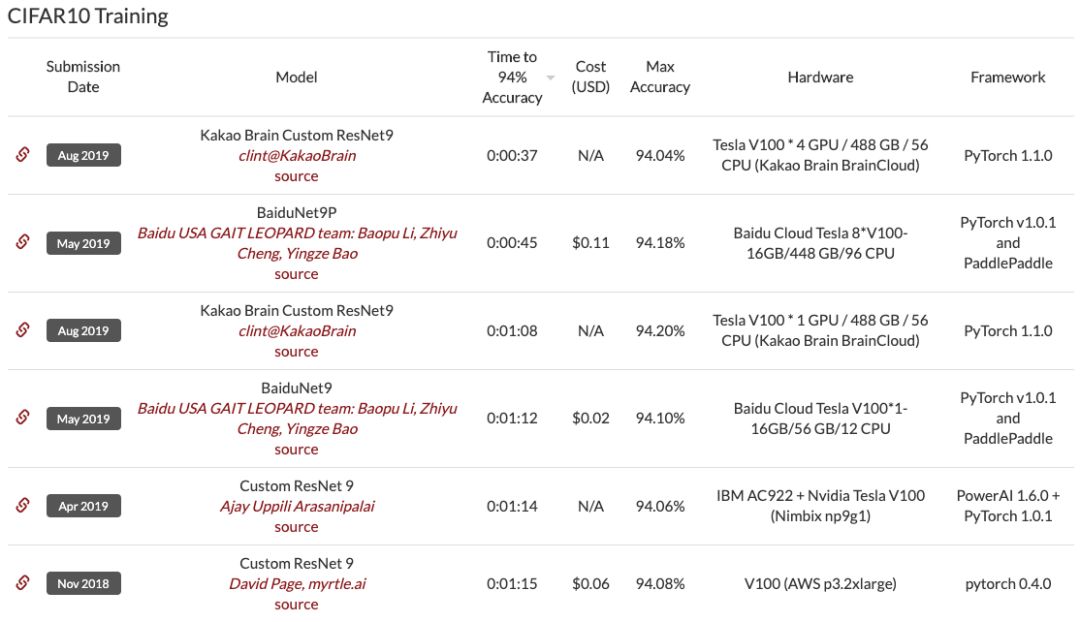
GPU 上进行数据预处理 (70s)
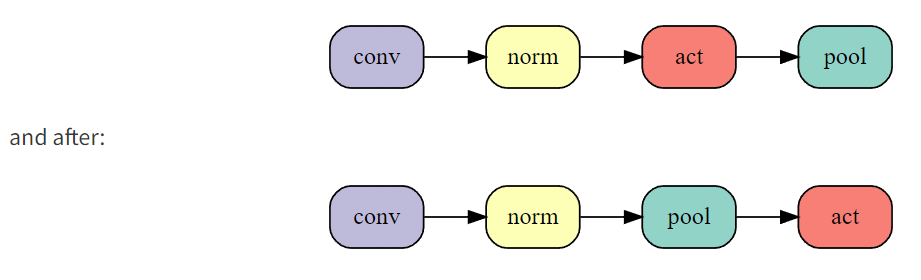
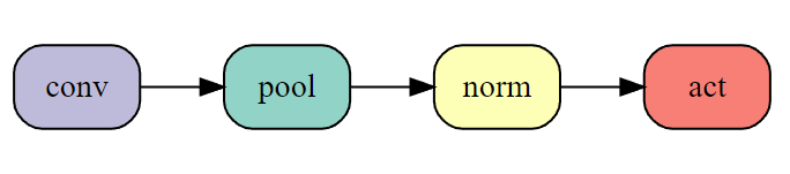
更换最大池化顺序 (64s)
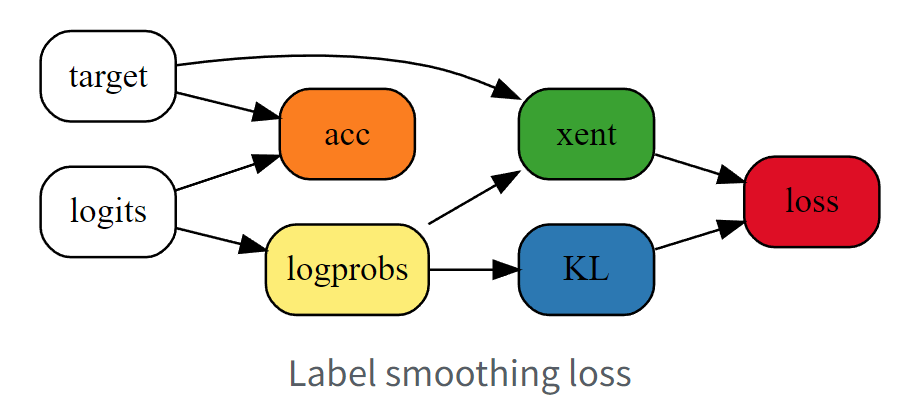
标签平滑化 (59s)
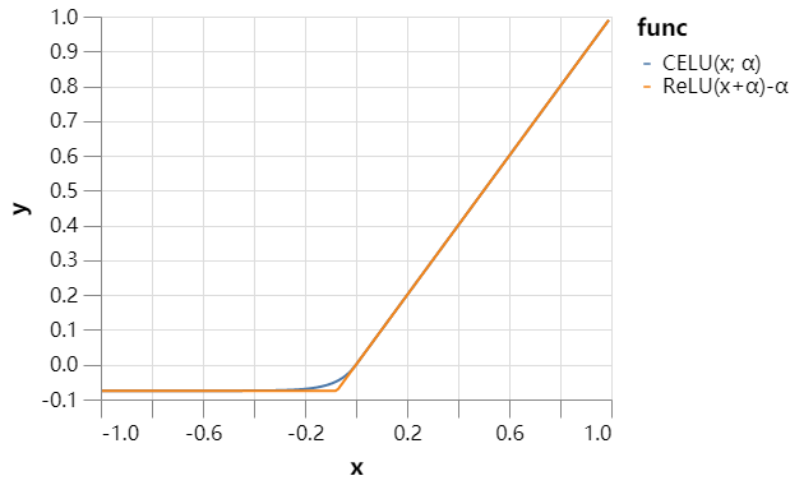
使用 CELU 激活函数 (52s)
幽灵批归一化 (46s)
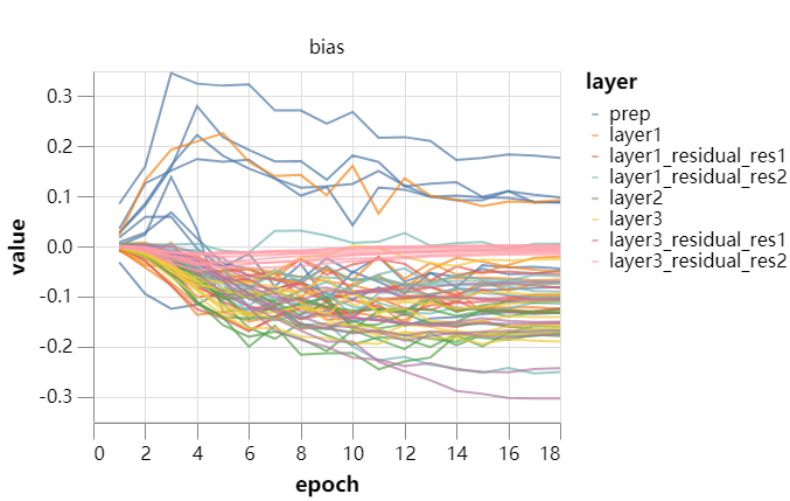
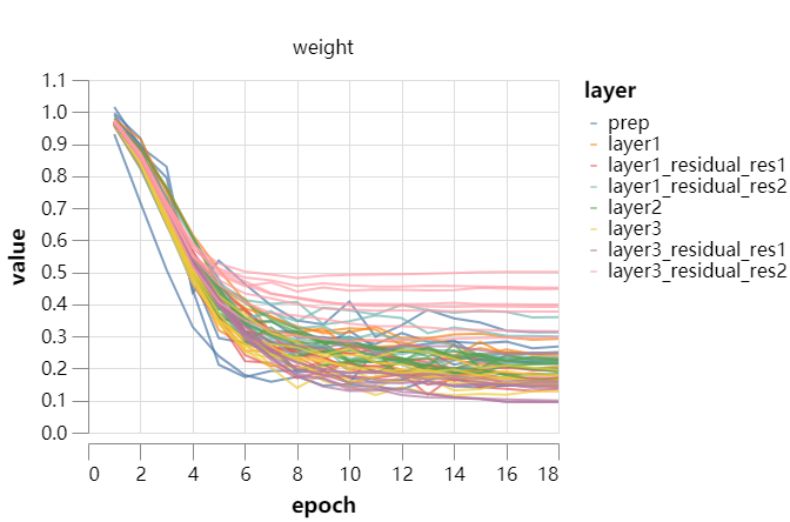
固定批归一化的缩放 (43s)
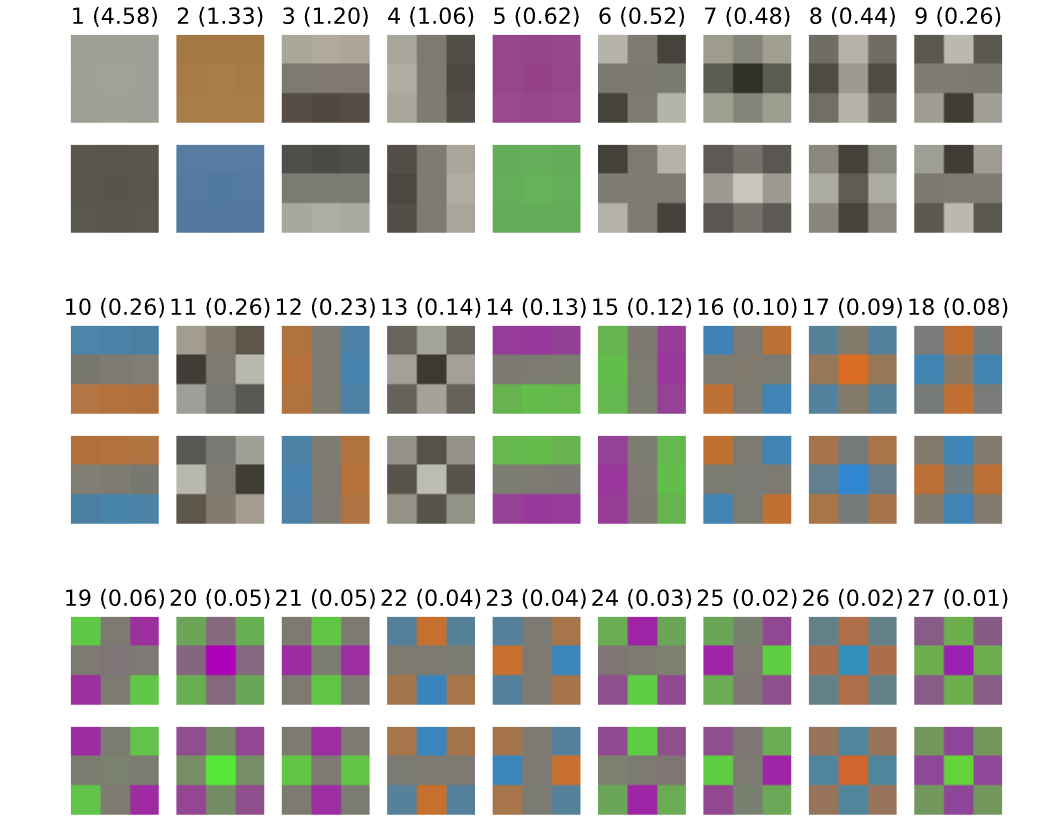
输入 patch 白化 (36s)
指数移动平均时间 (34s)
测试状态增强 (26s)
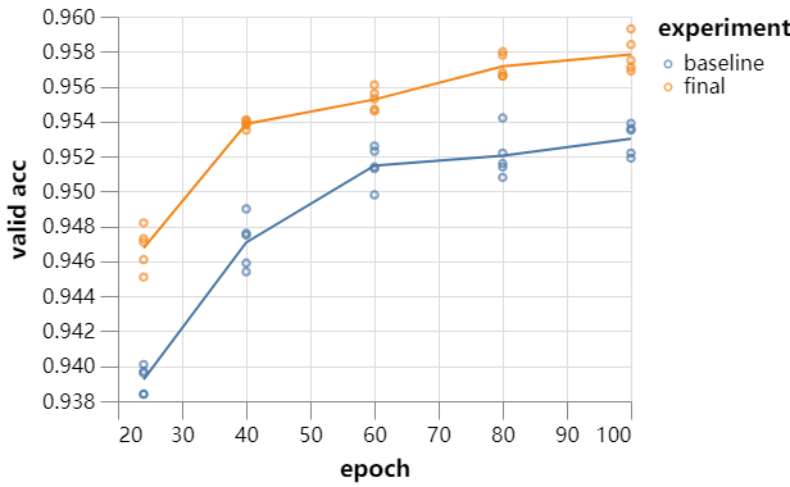
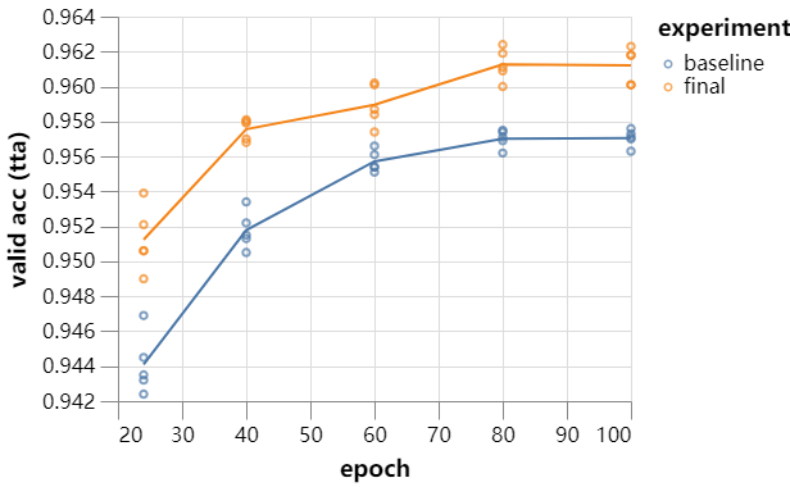
26 秒训练的 ResNet 效果怎么样


WAIC 2019 开发者日将于 8 月 31 日在上海世博中心举办,包含 1 个主单元、4 个分单元、黑客马拉松比赛和开发者诊所互动区。
届时,全球顶尖 AI 专家、技术大牛、知名企业代表以及数千名开发者将齐聚上海,围绕人工智能前沿理论技术和开发实践进行分享与解读。
点击阅读原文,立即报名。
登录查看更多
相关内容

专知会员服务
27+阅读 · 2020年3月26日
Arxiv
7+阅读 · 2020年3月12日
Arxiv
4+阅读 · 2018年1月11日


相关VIP内容
专知会员服务
27+阅读 · 2020年3月26日
相关资讯
相关论文
Arxiv
7+阅读 · 2020年3月12日
Arxiv
4+阅读 · 2018年1月11日