观点 | 对比梯度下降与进化策略,神经进化会成为深度学习的未来吗?
选自towardsdatascience
作者:Lars Hulstaert
机器之心编译
参与:李舒阳
今年 OpenAI 和 Uber 都发布了关于进化策略的文章,它们的研究表明进化策略在监督学习场景中可获得令人满意的效果,在强化学习场景中表现出高性能(在某些领域可以与目前最先进水平比肩)。那么神经进化会成为深度学习的未来吗?来自微软的 Lars Hulstaert 撰文介绍了自己的观点,同时介绍了梯度下降和神经进化及其区别。
2017 年 3 月,OpenAI 发布了一篇关于进化策略的博文。进化策略作为一种优化手段,已有几十年历史,而 OpenAI 论文的新颖之处在于使用进化策略优化强化学习(RL)问题中的深度神经网络。在此之前,深度学习 RL 模型(往往有数百万个参数)的优化通常采用反向传播。用进化策略优化深度神经网络(DNN)的做法可能为深度学习研究者开启了新的大门。
Uber AI Research 上周发布了五篇论文,主题均为「神经进化」。神经进化是指用进化算法对神经网络进行优化。研究者认为,遗传算法是强化学习问题中训练深度神经网络的有效方法,在某些领域的训练效果超过了传统的 RL 方法。

神经进化与自然进化的关系就像飞机与鸟的关系。神经进化从自然中借用了一些基本概念,神经网络和飞机也是如此。
概览
这是否意味着,在不久的将来,有监督、无监督和 RL 应用中的所有 DNN 都会采用神经进化的方法来优化呢?神经进化是深度学习的未来吗?神经进化究竟是什么?本文将走近神经进化算法,并与传统的反向传播算法做个比较。同时,我也会尝试回答上述问题,摆正神经进化算法在整个 DL 领域中的位置。
我们先从表述优化问题开始,优化问题是反向传播和神经进化试图解决的核心问题。此外,我也将对监督学习和强化学习的区别作出清晰的界定。
接下来,我会讨论反向传播及其与神经进化的关系。鉴于 OpenAI 和 Uber AI Research 都刚刚发布有关神经进化的论文,大量疑问会涌现出来。好在深度学习神经进化尚处于研究早期,算法的机制还比较容易理解。
优化问题
我在之前的博文中提过,机器学习模型的本质是函数逼近器。无论是分类、回归还是强化学习,最终目标基本都是要找到一个函数,从输入数据映射到输出数据。我们用训练数据来推断参数和超参数,用测试数据来验证近似函数是否适用于新数据。
输入可以是人为定义的特征或者原始数据(图像、文本等),输出可以是分类问题中的类或标签、回归问题中的数值,或者强化学习中的操作。本文限定函数逼近器的类型为深度学习网络(讨论结果也适用于其他模型),因此需要推断的参数是网络中的权重和偏差。「在训练数据和测试数据上表现良好」可以用客观指标来衡量,例如分类问题中的对数损失,回归问题中的均方差(MSE)和强化学习问题中的奖励。
核心问题是找到合适的参数设置,使损失最小或者奖励最大。简单嘛!把需要优化的目标(损失或奖励)看作网络参数的函数,微调参数使优化目标达到最大或最小值就好了。
举两个可视化的例子。第一个是抛物线,x 轴表示模型的单一参数,y 轴表示(测试数据上的)优化目标。
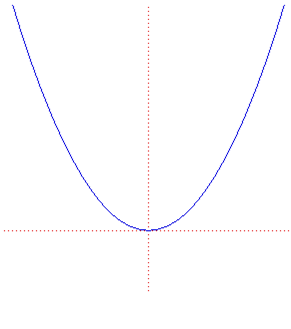
第二个例子见下图,x 轴和 y 轴分别表示模型的两个参数,z 轴表示(测试数据上的)优化目标。
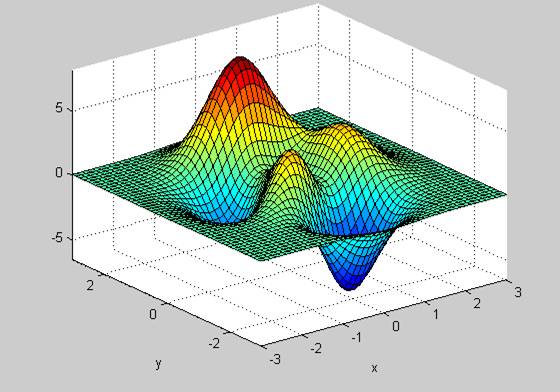
实际上,「优化曲面」是很难画出来的,因为深度学习网络中的参数数量庞大,而且是非线性组合,不过与简单曲面的思路相通。实际中的优化曲面往往高维且复杂,有很多丘陵、山谷和洼地。
现在的目标是找到一种优化技术,让我们穿越优化曲面,抵达最大或最小位置。注意,优化曲面的大小和形状与参数数量有关,不管采用连续还是离散参数,我们都不可能探索完所有的参数取值。于是问题变成了:随机给定优化曲面上的一个起点,找到绝对最小或最大值。
深度神经网络是很好的函数逼近器(甚至在一定程度上是通用函数逼近器),但它们依然很难优化,也就是说,很难在「优化曲面」上找到全局最小或最大值。下一节将讨论怎样用梯度下降和神经进化方法求解。
梯度下降
梯度下降(反向传播)的一般思想已经存在几十年了。有了丰富的数据、强大的计算力和创新的构思,梯度下降已成为深度学习模型参数优化的主要技术。
梯度下降的总体思路如下:
- 假设你在法国巴黎,要去德国柏林。这时候欧洲就是优化曲面,巴黎是随机的起点,柏林是最大或最小值的所在位置。
- 由于没有地图,你随机问陌生人去柏林的方向。有的人知道柏林在哪儿,有的人不知道,尽管多数时候你的方向正确,有时也可能走错方向。不过,只要指对路的陌生人比指错路的多,你应该能到达柏林(即,随机梯度下降或小批量梯度下降)。
- 按陌生人指的方向走 5 英里(步长或学习速率)。重复执行,直到你认为已经足够靠近德国。可能这时候你刚刚进入德国国境,离柏林还远(局部最优)。你没法确认有没有到达目的地,只能根据周边环境(测试损失或奖励)来估计。
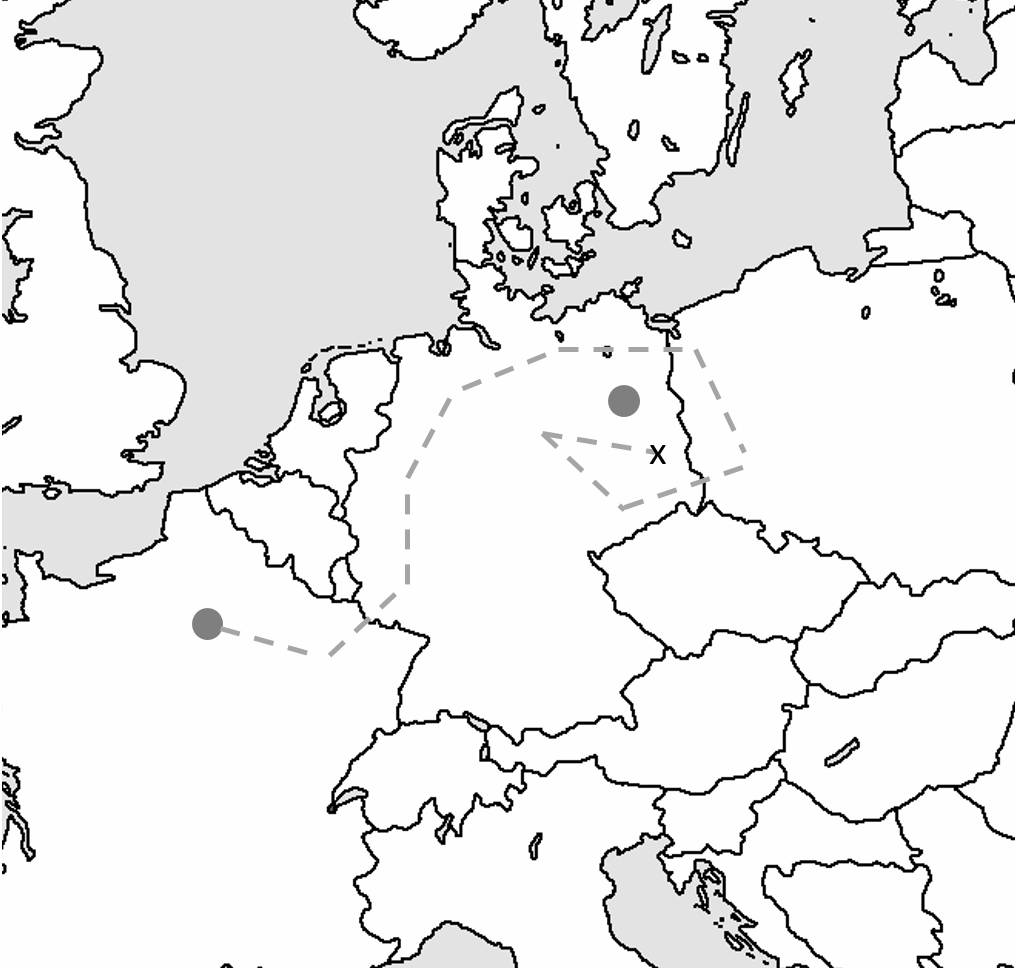
梯度下降:无地图暴走欧洲
回到之前的两个例子,想象在抛物线和更复杂曲面上的梯度下降情况。梯度下降的本质是在优化曲面上走下坡路。如果是抛物线,很简单,只要沿着曲线向下走就行。但如果学习速率太大,可能永远到不了最小值的位置。
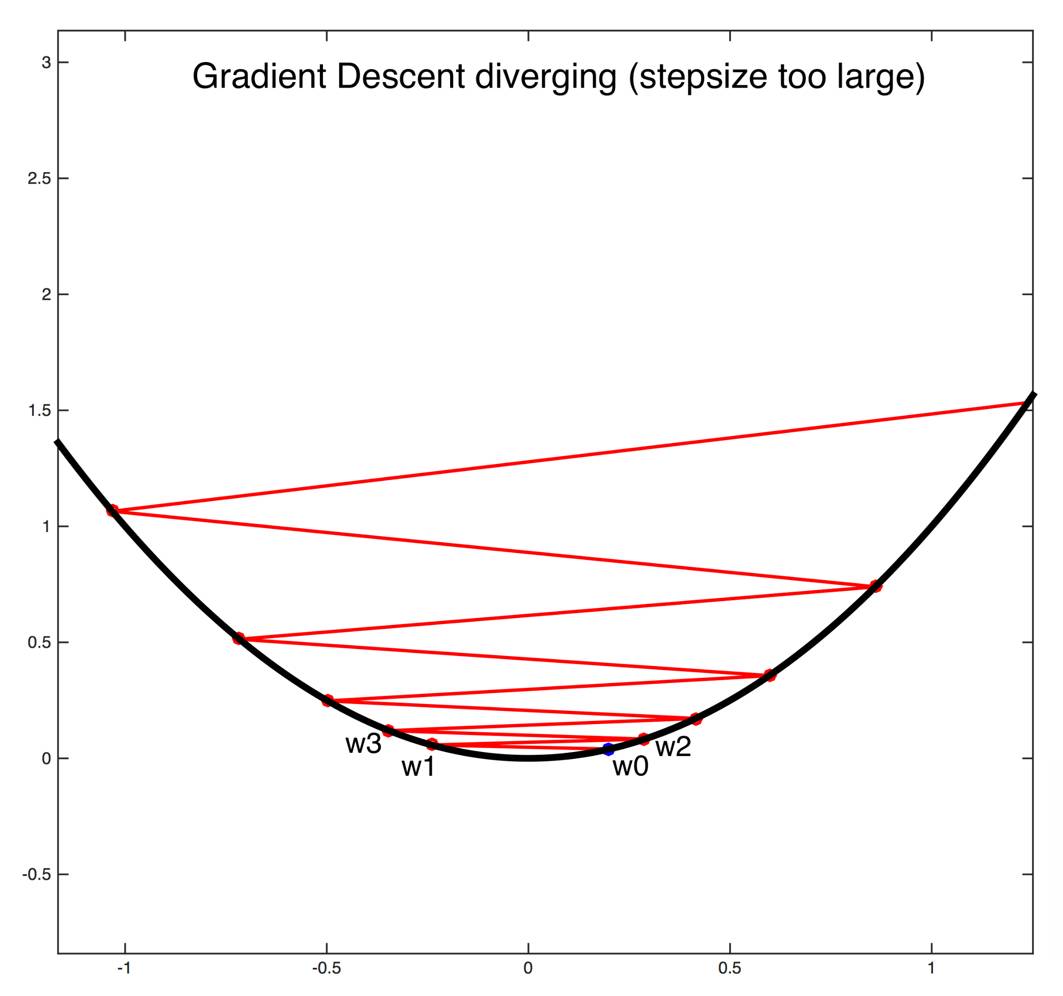
恰当选取步长的重要性(图片来自康奈尔大学课程)
第二个例子的情况更为复杂。要越过几个山丘和山谷才能到达最低点。为了避免陷入局部最优,梯度下降法的几个变种(如 ADAM)尝试模仿物理现象,例如有动量的球沿曲面滚下。
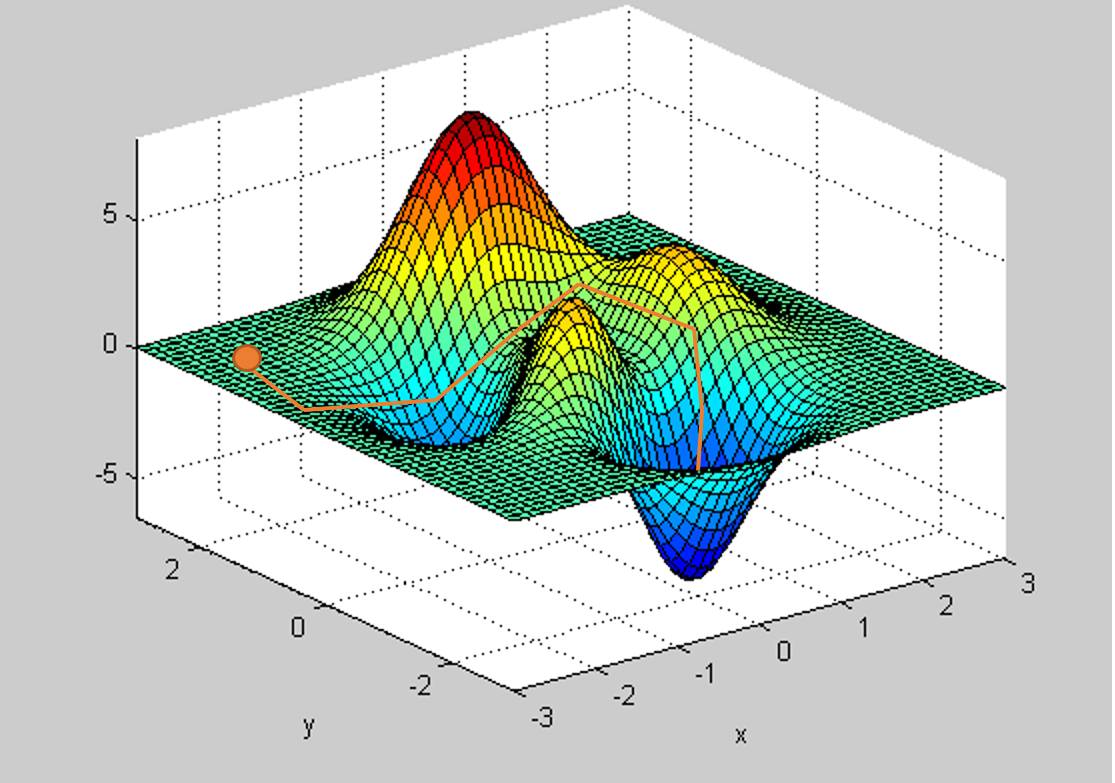
梯度下降法的路径示例。注意,如果超参数选取不当,可能陷入起点附近的局部极小值。
十分推荐这篇关于梯度下降法变种的博文(http://ruder.io/optimizing-gradient-descent/index.html#fn:15)。文中清楚地阐释了不同变种方法的区别以及适用的问题。优化问题中通常含有多个局部最优、障碍物和多条路径,不同的变种方法通常可以解决部分(或全部)疑难杂症。目前,ADAM 优化器似乎是最有影响力的一种。
梯度下降的关键是计算合适的梯度,推动你向好的解决方案迈进。在监督学习中,通过标注数据集可以较轻松地获取「高质量梯度」。然而在强化学习中,你只有稀疏的奖励,毕竟随机的初始行为不会带来高回报,而奖励只有在几次动作之后才会出现。总之,分类和回归问题中的损失可以较好地代表需要近似的函数,而强化学习中的奖励往往不是好的代表。
正由于强化学习中的梯度难以保证质量,Uber 和 OpenAI 最近采用进化算法来改善强化学习效果。
神经进化
神经进化、遗传算法和进化策略均围绕着遗传进化的概念展开。
对 DNN 做遗传优化,要从初始的模型群体(population)开始。通常,先随机初始化一个模型(和平常的做法一样),再由初始模型获得多个后代(offspring),即在模型参数上叠加小的随机向量,这些向量采样自简单的高斯分布。如此可以产生位于优化曲面上某处的模型群。注意,遗传优化与梯度下降的第一个重要区别就在于,遗传优化开始(并持续作用)于一群模型,而不是单个(点)模型。
有了原始模型群体,就进入遗传优化周期(genetic optimisation cycle)。下面将介绍进化策略(ES)背景下的遗传优化。选择进化策略还是遗传算法,执行遗传优化的方式略有不同。

遗传优化概览
首先进行适应度评估(fitness evaluation)。检查模型位于优化曲面上的哪些位置,判断哪些模型的效果最佳(例如,适应度最高)。仅仅因为初始化方式不同,有些模型就已经鹤立鸡群了。
然后,根据适应度来选择模型(selection)。进化策略中,(伪)后代缩减为单一的模型,通过适应度评估来设置权重。而对于 DNN,适应度定义为损失或奖励。相当于,你在优化曲面上漫游,通过选择合适的后代模型,走到正确的方向上。注意,这是遗传优化与梯度下降的第二个重要区别:你不计算梯度,而是设置多根「天线」去探索方向,朝看起来最好的方向前进。这种方法有点类似于「结构化随机森林」搜索。模型选择阶段的最终结果是选出一个模型。
接下来执行复制与组合(reproduction and combination)。与初始阶段类似,对模型选择阶段选出的「最优」(prime)模型,通过复制与组合操作衍生出一组新的后代,这组后代再进入前述的遗传优化周期。
遗传优化中通常也采用突变(mutation)来提升后代的多样性,一种突变是改变后代的产生方式(例如,对不同参数选取不同的噪声水平)。
ES 的一个优点是,对群体中不同模型的适应度评估可以在不同的核上计算(核外计算)。适应度评估之后,唯一需要共享的信息是模型性能(一个标量值)和用于生成模型的随机种子值。于是,再也不需要与所有机器共享整个网络的参数了。OpenAI 和 Uber 都使用了成百上千台机器进行实验。随着云计算的兴起,这些实验的规模化将十分容易,仅仅受限于计算力。
下图反映了 ES 和梯度下降的两大区别。ES 在穿越优化曲面时采用多个模型,不计算梯度,而是对不同模型的性能取平均。Uber 研究显示,相比于优化单个模型,优化模型群体的方法具有更高的鲁棒性,并表现出与贝叶斯方法优化 DNN 的相似性。
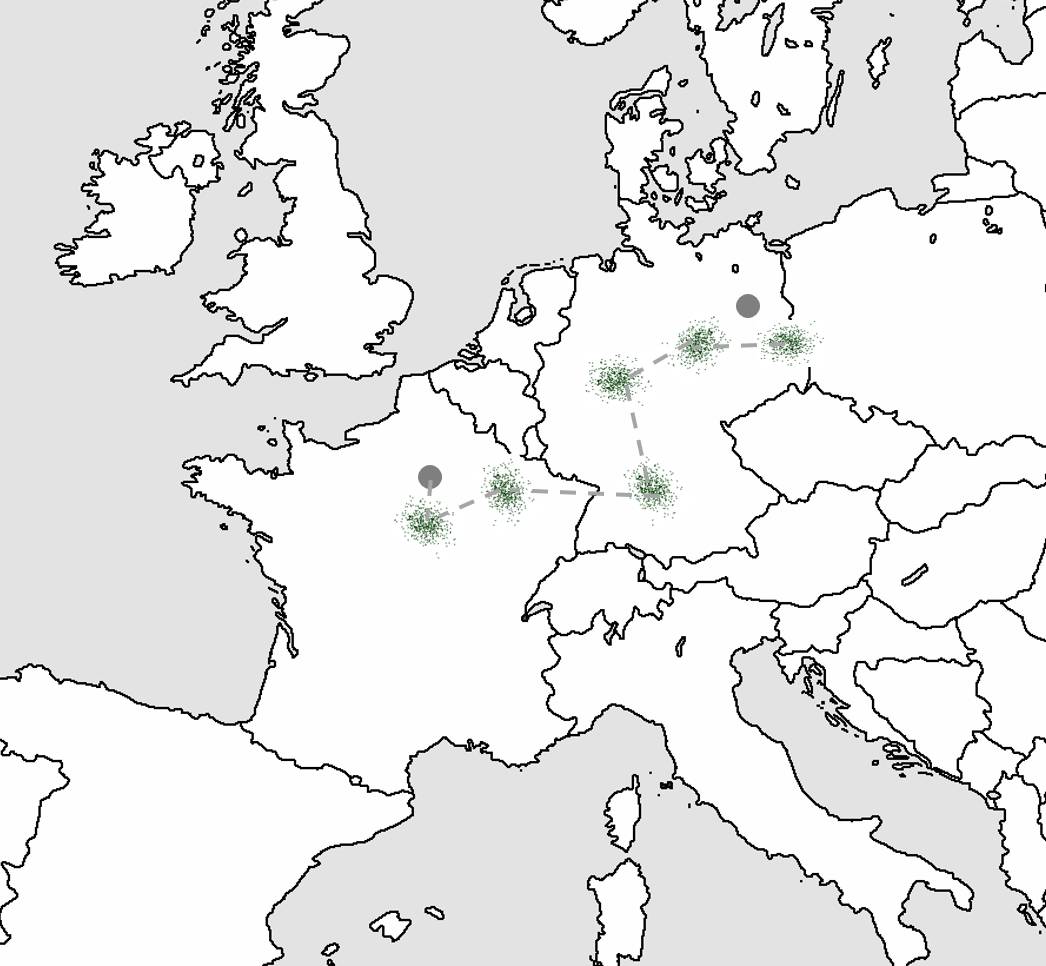
神经进化:组团游欧洲
强烈推荐大家看一下这篇 Uber 博文。文章中的插图生动表现了如何用 ES 规避梯度下降中遇到的一些问题(例如,陷入局部最优)。本质上讲,进化策略执行的是梯度逼近。能够计算真实梯度的问题中,采用真实梯度固然好,而只能计算较差的梯度近似值并且需要探索优化曲面(例如强化学习问题)时,进化策略可能更有希望。
结论
OpenAI 和 Uber 的研究人员表明,由于具有「梯度逼近」特性,进化策略在监督学习场景中可获得令人满意的效果(但并未超越目前最先进水平),在强化学习场景中表现出高性能(在某些领域可以与目前最先进水平比肩)。
神经进化会成为深度学习的未来吗?很可能不会,但我相信,它在诸如强化学习场景之类的高难度优化问题中会大展拳脚。并且,我相信神经进化和梯度下降方法的结合会显著提升强化学习的性能。不过,神经进化的一个缺点是模型群体的训练需要大量计算,对计算力的要求可能会限制这一技术的广泛传播。
有了顶尖研究团队的关注,我对神经进化的未来发展很是期待!

原文链接:https://towardsdatascience.com/gradient-descent-vs-neuroevolution-f907dace010f
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



