Uber AI实验室:遗传算法PK随机梯度下降,欢迎来到深度神经进化时代!

编者按:今天,Uber AI实验室发表长文,对近期发表的5篇关于神经进化的论文做了总结,指出遗传算法也可用于DNN优化,结合了随机梯度下降(SGD)的一些思想后,改良版的GA和ES在优化上表现出了令人惊奇的效果。事实上,自今年OpenAI提出进化策略在强化学习问题上有优秀表现后,遗传算法、进化策略等传统概念再一次成为机器学习领域的热门词汇,大有“文艺复兴”的趋势,那Uber在文章中讲了什么呢?请跟着论智去一探究竟。
以下内容由论智编译自原文:

在深度学习领域,现在人们常用随机梯度下降(SGD)算法来对层数很深、拥有数百万个连接的深层神经网络(DNN)进行训练。许多人认为,SGD对梯度的有效计算在这当中扮演着重要角色。为此,我们最近发布了5篇论文来支持另一种新观点——神经进化(neuroevolution),它指出遗传算法(genetic algorithm,GA)也可用于神经网络优化,经GA训练的DNN在强化学习问题上也有出色表现。
遗传算法在训练DNN上的竞争力
在实验中,我们使用了一种自创的新型DNN演化方法,让神经网络玩雅达利像素游戏。我们惊奇地发现,最简单的遗传算法竟然能训练一个包含400万参数的深层卷积网络,经它训练的模型不仅在许多游戏的效果上胜过使用经典强化学习算法的网络,而且由于是并行计算,它在速度上也有显著优势。
这一结果令我们始料未及,因为遗传算法不基于梯度计算,所以一般人们认为它不能很好地扩展到如此大的参数空间,并且一些学界最先进的研究成果也显示,遗传算法无法与强化学习算法相媲美。为了解释这个现象,我们做了进一步研究,发现现代的一些遗传算法增强版本弥补了传统的缺陷,如新颖性搜索(novelty search)算法,它可以在DNN这样规模的神经网络中运作,还可以通过扩大搜索来解决欺骗性问题(局部最优解)。而局部最优解/最大值正是阻碍DQN、A3C、ES、传统GA等实现奖励最大化的主要困难。
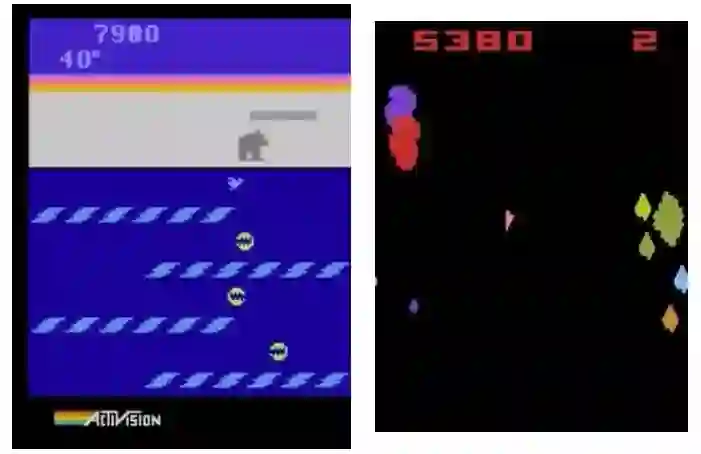
左:GA在过河游戏Frostbite上获得10,500分,而DQN、A3C、ES只有不到1000分;右:GA在太空游戏Asteroids上的平均表现超过DQN和ES,但不及A3C
用梯度实现安全突变
在Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients一文中,我们尝试过一种通过将梯度计算结合进神经进化,让遗传算法能在非常深的神经网络内起效的方法。实验表明,这种做法可以使100层DNN中的参数不断进化,远远超过过去研究显示的水平。不同于深度学习中常使用的误差(error)梯度,我们输入的是一个权重梯度,它能将突变校准到少量敏感参数上,从而解决大型神经网络随机进化问题。
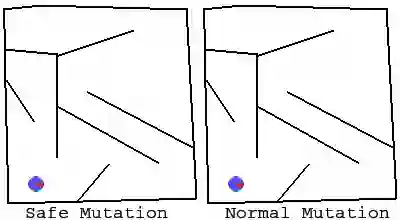
如上图所示,左图为安全突变,右图为正常GA突变。突变参数(蓝球)从左下角输入,需要前往左上角“出口”,可以发现,安全突变保留了大部分达成目标能力,并实现了多样性,在这类问题上,它和传统GA相比有着显著的优越性。
如何实现ES和SGD的关联
在论文中,我们援引了otoro的一篇文章:ML领域的生物进化论,进化策略图文详解。主要介绍了OpenAI在今年早些时候提出的一个用于强化学习问题的进化策略(ES)算法。虽然时至今日,学界对他们的成果仍会有一些猜想,但我们在原有基础上做了一些创新。
通过全面研究,我们深入探讨了进化策略和SGD的关系,检查了OpenAI版进化策略在MNIST数据集上的梯度,以及这些梯度与SGD算法梯度的相似性。事实证明,两者的梯度越相近,模型的表现越好,如果能提供足够的计算来保证梯度近似,那OpenAI版进化策略可以在MNIST取得99%的准确度。
而这也暗示了进化策略可能将成为深度强化学习中的一个有力竞争者,因为它能获得大量我们无法计算得到的完美梯度信息。
和梯度下降方法的差异
我们的另一篇论文ES Is More Than Just a Traditional Finite-Difference Approximator对进化策略在神经网络优化上的表现做了一些分析。研究表明,进化策略(有足够大扰动规模的参数,P.S.Uber论文称ES靠扰动现有参数来搜索参数空间)的优化方式和SGD不同,它依靠概率分布给出的是整个群体(种群)的期望奖励(搜索空间中的一片云),而SGD预测的只是一个参数的奖励(搜索空间中的一个点)。这个差异使进化策略能搜索参数空间中的不同区域,并标出哪块是好的,哪块是不好的。
扰动参数群体进行优化的另一个结果是进化策略不是靠SGD梯度下降来获得鲁棒性的,这也揭示了它和贝叶斯方法的一些有趣联系。
上述视频是进化策略是TPRO(信赖域策略优化)算法的训练结果对比,两者基于步态质量相同小人(九宫格最中间的小人)。两种算法都对参数进行了扰动,但可以发现,由于TPRO是根据权重做随机扰动,所以它训练的小人步态更不稳定,而进化策略的小人稳定性和原始小人类似,摔倒次数也相对更少。

左图为进化策略,右图为梯度下降。传统的梯度下降方法不能穿过低fit的狭窄区域,但ES可以

当高fit区域收窄时,ES停滞不前,但梯度下降没有受到干扰。这证明两者的优化方式有差别
增进对ES的探索
深度神经进化研究带来的一个令人兴奋的成果,是我们能把以往为神经进化开发的工具用来加强DNN训练,我们把握住了这个点,并在论文Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents中提出了一种新算法。
我们的算法继承了进化策略的优化能力和可扩展性,同时使用了神经进化的一些工具,它通过激励agent群体做彼此不同的参数空间探索来适应强化学习问题。简而言之,就是它虽然也像传统增强学习算法一样会在单个参数上做探索,但这个独立的探索是一种基于参数群体的探索。我们在雅达利游戏和奔跑小人上做了实验,证明这种算法可以提升进化策略在许多问题上的性能,同时避免局部最优解。

左:一般ES;右:Uber的ES
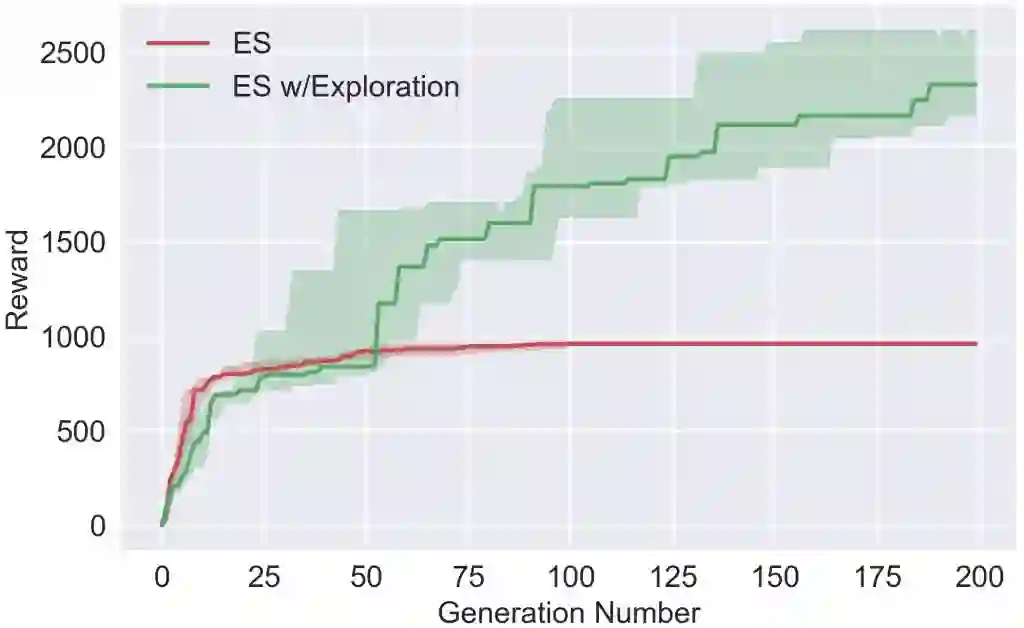
一般ES(红线)会陷入局部最优解
如上图所示(动图显示不全,可去原文看视频),给定超参数后,一般进化策略迅速收敛到一个局部最优解,即不能打怪获得奖励,也不会死的“发呆”状态。而添加神经进化工具的进化策略显示出了更多“野心”,它会积极寻求更大的奖励。

左:一般ES;右:Uber的ES
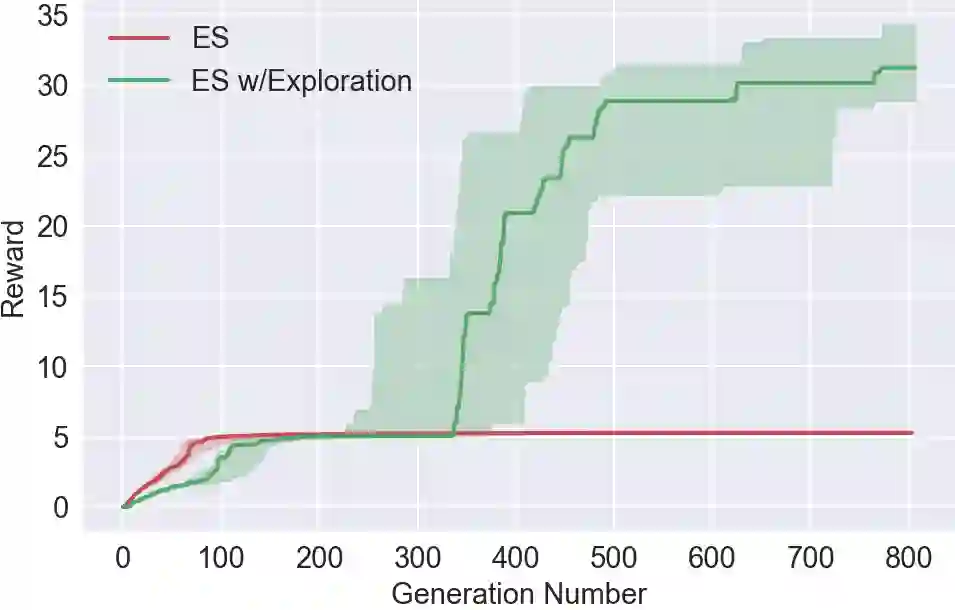
训练期间奖励收集情况
上图中,agent的任务是尽可能地朝前走,进行700轮迭代后,添加了神经进化工具的进化策略能绕过障碍物并持续前进,但一般进化策略还卡在局部最优的陷阱内。线图显示,其实前者也曾面临探索压力,但迭代至350轮时,一个agent“意识”到了走出陷阱。
结论
对于那些也对神经进化产生兴趣的研究人员,我们建议你要注意以下几点:
首先,这些实验都基于空前的大量计算,我们在实验时经常需要同时运行几百个甚至上千个CPU。但是,这种对于算力的压榨不应被视为一种负担,因为从长远来看,如果神经进化只对大规模并行计算有要求,那鉴于它的优化效果拔群,它在未来的应用上将是一片坦途。
其次,我们发现的新结果和以往在低维神经进化中观察到的结果很不一样,它们推翻了过去的一些推断,尤其是在高维搜索方面。基于某种复杂门槛,参数空间搜索似乎在高维空间中更简单易行,因为它不受局部最优影响。虽然这种思维方式更像是深度学习领域的,但神经进化可以对此给出一些解释。
最后,神经进化的出现是否昭示着机器学习领域即将掀起“文艺复兴”?正如我们在文中提到的,神经进化和现行的SGD在优化方式上是很不一样,它为我们提供了一种有趣的替代方法,而这或多或少为学者们带来了一些启发。
最后,让我们再梳理一下文章中介绍的5篇论文:
1.Deep Neuroevolution: Genetic Algorithms are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
用最传统、最简单的遗传算法训练DNN,获得的网络在RL问题上表现良好。在雅达利游戏上和DQN、A3C等对比;
深度遗传算法训练了一个包含400万参数的深层卷积网络,其中最大的神经网络是由传统遗传算法训练得到的;
在某些情况下,梯度下降不是优化的最佳选择;
Deep GA的并行性比ES、A3C和DQN更好,所以它的速度更快,而且支持最先进的紧凑型编码技术;
在包括雅达利游戏在内的一些实验中,随机搜索优于DQN、A3C和ES,但它比不上GA。
2.Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients
用梯度安全突变(SM-G)表现网络对特定连接权重的敏感性,由此提高算法在大型、深度、复杂网络上的训练效果;
计算与输出相关的权重的梯度,而不是损失梯度;
两种类型的安全突变都不需要额外部署;
结论:深层神经网络(超过100层)和大型循环网络现在只能通过SM-G有效训练。
3.On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent
在MNIST上比较ES和SGD的梯度,由此探讨两者关系;
用不同规模的参数群体测试ES的预测效果;
介绍并演示不同的方法来加速和改进ES的性能;
有限扰动ES显著加快了并行基础架构的执行速度;
基于ES和SGD的梯度计算改进;
No-mini-batch ES在数据集上的准确率高达99%;
ES在RL上有竞争优势。
4.ES Is More Than Just a Traditional Finite Difference Approximator
强调ES和梯度下降方法的区别;
由ES发现的解决方案往往对参数扰动是鲁棒的;
ES也许可以解决局部最优解这个传统难题。
5.Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
在ES中增加激励进一步探索的工具;
指出一些已开发的进化神经探索算法可以与ES结合,提高算法在稀疏性、欺骗性情景下的表现;
将这个基于群体的搜索算法添加到RL工具中。
原文地址:eng.uber.com/deep-neuroevolution/