深度强化学习的18个关键问题
https://zhuanlan.zhihu.com/p/32153603

智能单元
写文章
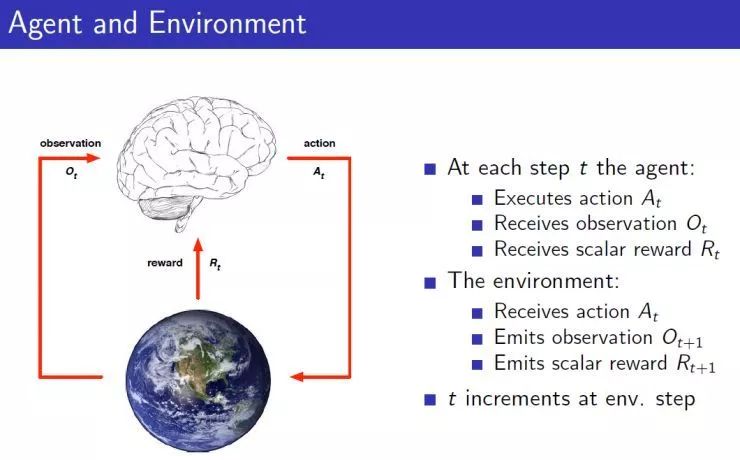
深度强化学习的18个关键问题
王留行
深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破?
这两天我阅读了一篇猛文Deep Reinforcement Learning: An Overview ,作者排山倒海的引用了200多篇文献,阐述强化学习未来的方向。原文归纳出深度强化学习中的常见科学问题,并列出了目前解法与相关综述,我在这里做出整理,抽取了相关的论文。
这里精选18个关键问题,涵盖空间搜索、探索利用、策略评估、内存使用、网络设计、反馈激励等等话题。本文精选了73篇论文(其中2017年论文有27篇,2016年论文有21篇)为了方便阅读,原标题放在文章最后,可以根据索引找到。
TODO list:文章内容还不够充实,但是论文是全的。未来一段时间会把论文的链接找齐,下载好然后打个包传到百度云上,预计一两天完成。(2017/12/19)
问题一:预测与策略评估
prediction, policy evaluation
万变不离其宗,Temporal Difference方法仍然是策略评估的核心哲学【Sutton 1988】。TD的拓展版本和她本身一样鼎鼎大名——1992年的Q-learning与2015年的DQN。
美中不足,TD Learning中很容易出现Over-Estimate(高估)问题,具体原因如下:
The max operator in standard Q-learning and DQN use the same values both to select and to evaluate an action. —— van Hasselt
旷世猛将van Hasselt先生很喜欢处理Over-Estimate问题,他先搞出一个Double Q-learning【van Hasselt 2010】大闹NIPS,六年后搞出深度学习版本的Double DQN【van Hasselt 2016a】。
问题二:控制与最佳策略选择
control, finding optimal policy
目前解法有三个流派,一图胜千言:
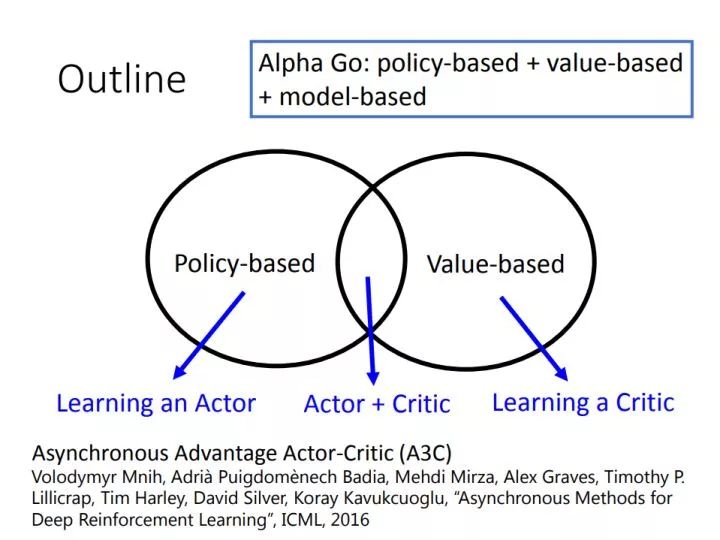
最传统的方法是Value-Based,就是选择有最优Value的Action。最经典方法有:Q-learning 【Watkins and Dayan 1992】、SARSA 【Sutton and Barto 2017】
后来Policy-Based方法引起注意,最开始是REINFORCE算法【Williams 1992】,后来策略梯度Policy Gradient【Sutton 2000】出现。
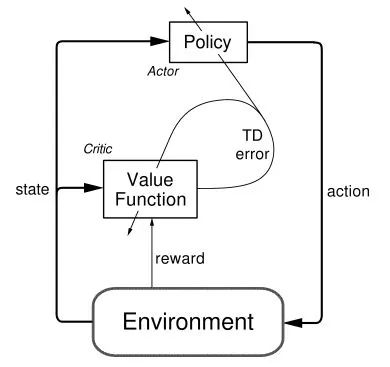
最时行的Actor-Critic 【Barto 1983】把两者做了结合。楼上Sutton老爷子的好学生、AlphaGo的总设计师David Silver同志提出了Deterministic Policy Gradient,表面上是PG,实际讲了一堆AC,这个改进史称DPG【Silver 2014】
问题三:不稳定与不收敛问题
Instability and Divergence when combining off-policy,function approximation,bootstrapping
早在1997年Tsitsiklis就证明了如果Function Approximator采用了神经网络这种非线性的黑箱,那么其收敛性和稳定性是无法保证的。
分水岭论文Deep Q-learning Network【Mnih 2013】中提到:虽然我们的结果看上去很好,但是没有任何理论依据(原文很狡猾的反过来说一遍)。
This suggests that, despite lacking any theoretical convergence guarantees, our method is able to train large neural networks using a reinforcement learning signal and stochastic gradient descent in stable manner

DQN的改良主要依靠两个Trick:
经验回放【Lin 1993】(虽然做不到完美的独立同分布,但还是要尽力减少数据之间的关联性)
Target Network【Mnih 2015】(Estimated Network和Target Network不能同时更新参数,应该另设Target Network以保证稳定性)
Since the network Q being updated is also used in calculating the target value, the Q update is prone to divergence.(为什么我们要用Target Network)
下面几篇论文都是DQN相关话题的:
经验回放升级版:Prioritized Experience Replay 【Schaul 2016】
更好探索策略 【Osband 2016】
DQN加速 【He 2017a】
通过平均减少方差与不稳定性Averaged-DQN 【Anschel 2017】
下面跳出DQN的范畴——
Duel DQN【Wang 2016c】(ICML2016最佳论文)
Tips:阅读此文请掌握DQN、Double DQN、Prioritized Experience Replay这三个背景。
异步算法A3C 【Mnih 2016】
TRPO(Trust Region Policy Optimization)【Schulman 2015】
Distributed Proximal Policy Optimization 【Heess 2017】
Policy gradient与Q-learning 的结合【O'Donoghue 2017】【Nachum 2017】【Gu 2017】【Schulman 2017】
GTD 【Sutton 2009a】【Sutton 2009b】【Mahmood 2014】
Emphatic-TD 【Sutton 2016】
问题四:End-to-End下的训练感知与控制
train perception and control jointly end-to-end
现有解法是Guided Policy Search 【Levine 2016a】
问题五:数据利用效率
data/sample efficiency
现有解法有:
经验回放下的actor-critic 【Wang 2017b】
PGQ,policy gradient and Q-learning 【O'Donoghue 2017】
Q-Prop, policy gradient with off-policy critic 【Gu 2017】
return-based off-policy control的工作有:Retrace【Munos 2016】, Reactor【Gruslyset 2017】
learning to learn【Duan 2017】【Wang 2016a】【Lake 2015】
问题六:无法取得激励
reward function not available
现有解法基本上围绕模仿学习
吴恩达的逆强化学习【Ng and Russell 2000)】
learn from demonstration 【Hester 2017】
imitation learning with GANs 【Ho and Ermon 2016】【Stadie 2017】 (其TensorFlow实现在imitation)
train dialogue policy jointly with reward model 【Su 2016b】
问题七:探索-利用问题(最经典的问题)
exploration-exploitation tradeoff
现有解法有:
unify count-based exploration and intrinsic motivation 【Bellemare 2017】
under-appreciated reward exploration 【Nachum 2017)】
deep exploration via bootstrapped DQN 【Osband 2016)】
variational information maximizing exploration 【Houthooft 2016】
问题八:基于模型的学习
model-based learning
现有解法:
Sutton老爷子教科书里的经典案例:Dyna-Q【Sutton 1990】
model-free与model-based的结合使用【Chebotar 2017】
问题九:无模型规划
model-free planning
比较新的解法有两个:
Value Iteration Networks【Tamar 2016】是勇夺NIPS2016最佳论文头衔的猛文,知乎上已经有专门的文章解说了:Value iteration Network,还有作者的采访NIPS 2016最佳论文作者:如何打造新型强化学习观?VIN的TensorFlow实现在tensorflow-value-iteration-networks。
DeepMind的Silver大神发表的Predictron方法 【Silver 2016b】,其TensorFlow实现是predictron。
问题十:它山之石可以攻玉
focus on salient parts
@贾扬清 大神曾经说过:
伯克利人工智能方向的博士生,入学一年以后资格考试要考这几个内容:
强化学习和Robotics、 统计和概率图模型、 计算机视觉和图像处理、 语音和自然语言处理、 核方法及其理论、 搜索,CSP,逻辑,Planning等
如果真的想做人工智能,建议都了解一下,不是说都要搞懂搞透,但是至少要达到开会的时候和人在poster前面谈笑风生不出错的程度吧。
因此,一个很好的思路是从计算机视觉与自然语言处理领域汲取灵感,例如下文中将会提到的unsupervised auxiliary learning方法借鉴了RNN+LSTM中的大量操作。
下面是CV和NLP方面的几个简介:物体检测 【Mnih 2014】、机器翻译 【Bahdanau 2015】、图像标注【Xu 2015】、用Attention代替CNN和RNN【Vaswani 2017】等等。
问题十一:长时间数据储存
data storage over long time, separating from computation
最出名的解法是在Nature上大秀一把的Differentiable Neural Computer【Graves et al 2016】
问题十二:无回报训练
benefit from non-reward training signals in environments
现有解法围绕着无监督学习开展
Horde 【Sutton 2011】
没有回报就用辅助函数,一篇极其优秀的工作:unsupervised reinforcement and auxiliary learning 【Jaderberg 2017】
learn to navigate with unsupervised auxiliary learning 【Mirowski 2017】
下面是大名鼎鼎的GANs 【Goodfellow et al 2014】
问题十三:跨领域学习
learn knowledge from different domains
现有解法全部围绕迁移学习走 【Taylor and Stone, 2009】【Pan and Yang 2010】【Weiss 2016】,learn invariant features to transfer skills 【Gupta 2017】
问题十四:有标签数据与无标签数据混合学习
benefit from both labelled and unlabelled data
现有解法全部围绕半监督学习 【Zhu and Goldberg 2009】
learn with MDPs both with and without reward functions 【Finn 2017】
learn with expert's trajectories and those may not from experts 【Audiffren 2015】
问题十五:多层抽象差分空间的表示与推断
learn, plan, and represent knowledge with spatio-temporal abstraction at multiple levels
现有解法:多层强化学习 【Barto and Mahadevan 2003】
strategic attentive writer to learn macro-actions 【Vezhnevets 2016】
integrate temporal abstraction with intrinsic motivation 【Kulkarni 2016】
stochastic neural networks for hierarchical RL 【Florensa 2017】
lifelong learning with hierarchical RL 【Tessler 2017】
问题十六:不同任务环境快速适应
adapt rapidly to new tasks
现有解法基本上是learn to learn
learn a flexible RNN model to handle a family of RL tasks 【Duan 2017】【Wang 2016a】
one/few/zero-shot learning 【Duan 2017】【Johnson 2016】【Kaiser 2017b】【Koch 2015】【Lake 2015】【Li and Malik 2017】【Ravi and Larochelle 2017】【Vinyals 2016】
问题十七:巨型搜索空间
gigantic search space
现有解法依然是蒙特卡洛搜索,详情可以参考初代AlphaGo的实现【Silver 2016a】
问题十八:神经网络架构设计
neural networks architecture design
现有的网络架构搜索方法【Baker 2017】【Zoph and Le 2017】,其中Zoph的工作分量非常重。
新的架构有【Kaiser 2017a】【Silver 2016b】【Tamar 2016】【Vaswani 2017】【Wang 2016c】
参考文献
Anschel, O., Baram, N., and Shimkin, N. (2017). Averaged-DQN: Variance reduction and stabilization for deep reinforcement learning. In the International Conference on Machine Learning (ICML).
Audiffren, J., Valko, M., Lazaric, A., and Ghavamzadeh, M. (2015). Maximum entropy semisupervised inverse reinforcement learning. In the International Joint Conference on Artificial Intelligence (IJCAI).
Bahdanau, D., Brakel, P., Xu, K., Goyal, A., Lowe, R., Pineau, J., Courville, A., and Bengio, Y. (2017). An actor-critic algorithm for sequence prediction. In the International
Conference on Learning Representations (ICLR).
Baker, B., Gupta, O., Naik, N., and Raskar, R. (2017). Designing neural network architectures using reinforcement learning. In the International Conference on Learning Representations (ICLR).
Barto, A. G. and Mahadevan, S. (2003). Recent advances in hierarchical reinforcement learning. Discrete Event Dynamic Systems, 13(4):341–379.
Barto, A. G., Sutton, R. S., and Anderson, C. W. (1983). Neuronlike elements that can solve difficult learning control problems. IEEE Transactions on Systems, Man, and Cybernetics, 13:835–846
Bellemare, M. G., Danihelka, I., Dabney, W., Mohamed, S.,Lakshminarayanan, B., Hoyer, S., and Munos, R. (2017). The Cramer Distance as a Solution to Biased Wasserstein Gradients. ArXiv e-prints.
Chebotar, Y., Hausman, K., Zhang, M., Sukhatme, G., Schaal, S., and Levine, S. (2017). Combining model-based and model-free updates for trajectory-centric reinforcement learning. In the International Conference on Machine Learning (ICML)
Duan, Y., Andrychowicz, M., Stadie, B. C., Ho, J., Schneider, J.,Sutskever, I., Abbeel, P., and Zaremba, W. (2017). One-Shot Imitation Learning. ArXiv e-prints.
Finn, C., Christiano, P., Abbeel, P., and Levine, S. (2016a). A connection between GANs, inverse reinforcement learning, and energy-based models. In NIPS 2016 Workshop
on Adversarial Training.
Florensa, C., Duan, Y., and Abbeel, P. (2017). Stochastic neural networks for hierarchical reinforcement learning. In the International Conference on Learning Representations (ICLR)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., , and Bengio, Y. (2014). Generative adversarial nets. In the Annual
Conference on Neural Information Processing Systems (NIPS), page 2672?2680.
Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwinska, A., Col- ´ menarejo, S. G., Grefenstette, E., Ramalho, T., Agapiou, J., nech Badia, A. P., Hermann, K. M., Zwols, Y., Ostrovski, G., Cain, A., King, H., Summerfield, C., Blunsom, P., Kavukcuoglu, K., and Hassabis, D. (2016). Hybrid computing using a neural network with dynamic external memory. Nature, 538:471–476
Gruslys, A., Gheshlaghi Azar, M., Bellemare, M. G., and Munos, R. (2017). The Reactor: A Sample-Efficient Actor-Critic Architecture. ArXiv e-prints
Gu, S., Lillicrap, T., Ghahramani, Z., Turner, R. E., and Levine, S. (2017). Q-Prop: Sampleefficient policy gradient with an off-policy critic. In the International
Conference on Learning Representations (ICLR).
Gupta, A., Devin, C., Liu, Y., Abbeel, P., and Levine, S. (2017). Learning invariant feature spaces to transfer skills with reinforcement learning. In the International Conference on Learning Representations (ICLR).
He, F. S., Liu, Y., Schwing, A. G., and Peng, J. (2017a). Learning to play in a day: Faster deep reinforcement learning by optimality tightening. In the International Conference on Learning Representations (ICLR)
Heess, N., TB, D., Sriram, S., Lemmon, J., Merel, J., Wayne, G., Tassa, Y., Erez, T., Wang, Z., Eslami, A., Riedmiller, M., and Silver, D. (2017). Emergence of Locomotion Behaviours in Rich Environments. ArXiv e-prints
Hester, T. and Stone, P. (2017). Intrinsically motivated model learning for developing curious robots. Artificial Intelligence, 247:170–86.
Ho, J. and Ermon, S. (2016). Generative adversarial imitation learning. In the Annual Conference on Neural Information Processing Systems (NIPS).
Houthooft, R., Chen, X., Duan, Y., Schulman, J., Turck, F. D., and Abbeel, P. (2016). Vime: Variational information maximizing exploration. In the Annual Conference on Neural Information Processing Systems (NIPS).
Jaderberg, M., Mnih, V., Czarnecki, W., Schaul, T., Leibo, J. Z., Silver, D., and Kavukcuoglu, K. (2017). Reinforcement learning with unsupervised auxiliary tasks. In the International Conference on Learning Representations (ICLR).
Johnson, M., Schuster, M., Le, Q. V., Krikun, M., Wu, Y., Chen, Z., Thorat, N., Viegas, F., Watten- ´berg, M., Corrado, G., Hughes, M., and Dean, J. (2016). Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. ArXive-prints.
Kaiser, L., Gomez, A. N., Shazeer, N., Vaswani, A., Parmar, N., Jones, L., and Uszkoreit, J. (2017a). One Model To Learn Them All. ArXiv e-prints.
Kaiser, Ł., Nachum, O., Roy, A., and Bengio, S. (2017b). Learning to Remember Rare Events. In the International Conference on Learning Representations (ICLR).
Koch, G., Zemel, R., and Salakhutdinov, R. (2015). Siamese neural networks for one-shot image recognition. In the International Conference on Machine Learning (ICML).
Kulkarni, T. D., Narasimhan, K. R., Saeedi, A., and Tenenbaum, J. B. (2016). Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In the Annual Conference on Neural Information Processing Systems (NIPS)
Lake, B. M., Salakhutdinov, R., and Tenenbaum, J. B. (2015). Human-level concept learning through probabilistic program induction. Science, 350(6266):1332–1338.
Levine, S., Finn, C., Darrell, T., and Abbeel, P. (2016a). End-to-end training of deep visuomotor policies. The Journal of Machine Learning Research, 17:1–40.
Li, K. and Malik, J. (2017). Learning to optimize. In the International Conference on Learning Representations (ICLR).
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., & Tassa, Y., et al. (2015). Continuous control with deep reinforcement learning. Computer Science, 8(6), A187.
Lin, L. J. (1993). Reinforcement learning for robots using neural networks.
Mahmood, A. R., van Hasselt, H., and Sutton, R. S. (2014). Weighted importance sampling for off-policy learning with linear function approximation. In the Annual Conference on Neural Information Processing Systems (NIPS).
Mirowski, P., Pascanu, R., Viola, F., Soyer, H., Ballard, A., Banino, A., Denil, M., Goroshin, R., Sifre, L., Kavukcuoglu, K., Kumaran, D., and Hadsell, R. (2017). Learning to navigate in complex environments. In the International Conference on Learning Representations (ICLR).
Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Graves, Alex, Antonoglou, Ioannis, Wier- stra, Daan, and Riedmiller, Martin. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
Mnih, V., Heess, N., Graves, A., and Kavukcuoglu, K. (2014). Recurrent models of visual attention. In the Annual Conference on Neural Information Processing Systems
(NIPS).
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A.,
Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., and Hassabis, D. (2015).
Human-level control through deep reinforcement learning. Nature, 518(7540):529–533.
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Harley, T., Lillicrap, T. P., Silver, D., and Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In the International Conference on Machine Learning (ICML)
Munos, R., Stepleton, T., Harutyunyan, A., and Bellemare, M. G.(2016). Safe and efficient offpolicy reinforcement learning. In the Annual Conference on Neural Information Processing Systems (NIPS).
Nachum, O., Norouzi, M., and Schuurmans, D. (2017). Improving policy gradient by exploring under-appreciated rewards. In the International Conference on Learning Representations (ICLR).
Nachum, O., Norouzi, M., Xu, K., and Schuurmans, D. (2017). Bridging the Gap Between Value and Policy Based Reinforcement Learning. ArXive-prints.
Ng, A. and Russell, S. (2000).Algorithms for inverse reinforcement learning. In the International Conference on Machine Learning (ICML).
O'Donoghue, B., Munos, R., Kavukcuoglu, K., and Mnih, V. (2017). PGQ: Combining policy gradient and q-learning. In the International Conference on Learning Representations (ICLR).
Osband, I., Blundell, C., Pritzel, A., and Roy, B. V. (2016). Deep exploration via bootstrapped DQN. In the Annual Conference on Neural Information Processing Systems (NIPS).
Pan, S. J. and Yang, Q. (2010). A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 22(10):1345 – 1359.
Ravi, S. and Larochelle, H. (2017). Optimization as a model for few-shot learning. In the International Conference on Learning Representations (ICLR).
Schaul, T., Quan, J., Antonoglou, I., and Silver, D. (2016). Prioritized experience replay. In the International Conference on Learning Representations (ICLR).
Schulman, J., Levine, S., Moritz, P., Jordan, M. I., and Abbeel, P. (2015). Trust region policy optimization. In the International Conference on Machine Learning (ICML).
Schulman, J., Abbeel, P., and Chen, X. (2017). Equivalence Between Policy Gradients and Soft Q-Learning. ArXiv e-prints.
Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., & Riedmiller, M. (2014). Deterministic policy gradient algorithms. International Conference on International Conference on Machine Learning (pp.387-395). JMLR.org.
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. (2016a). Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489.
Silver, D., van Hasselt, H., Hessel, M., Schaul, T., Guez, A., Harley, T., Dulac-Arnold, G., Reichert, D., Rabinowitz, N., Barreto, A., and Degris, T. (2016b). The predictron: End-to-end learning and planning. In NIPS 2016 Deep Reinforcement Learning Workshop.
Stadie, B. C., Abbeel, P., and Sutskever, I. (2017).Third person imitation learning. In the International Conference on Learning Representations (ICLR).
Sutton, R. S. and Barto, A. G. (2017). Reinforcement Learning: An Introduction (2nd Edition, in preparation). MIT Press.
Sutton, R. S., McAllester, D., Singh, S., and Mansour, Y. (2000). Policy gradient methods for reinforcement learning with function approximation. In the Annual Conference on Neural Information Processing Systems
(NIPS).
Sutton, R. S., Maei, H. R., Precup, D., Bhatnagar, S., Silver, D., Szepesvari, C., and Wiewiora, ´E. (2009a). Fast gradient-descent methods for temporal-difference learning with linear function approximation. In the International Conference on Machine Learning (ICML).
Sutton, R. S., Szepesvari, C., and Maei, H. R. (2009b). A convergent O( ´ n) algorithm for off-policy temporal-difference learning with linear function approximation. In the Annual Conference on Neural Information Processing Systems (NIPS).
Sutton, R. S., Modayil, J., Delp, M., Degris, T., Pilarski, P. M., White, A., and Precup, D. (2011). Horde: A scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction, , proc. of 10th. In International Conference on Autonomous Agents and Multiagent Systems (AAMAS).
Sutton, R. S., Mahmood, A. R., and White, M. (2016). An emphatic approach to the problem of off-policy temporal-difference learning. The Journal of Machine Learning Research, 17:1–29
Sutton, R. S. (1988). Learning to predict by the methods of temporal differences. Machine Learning,3(1):9–44.
Sutton, R. S. (1990). Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In the International Conference on Machine Learning (ICML).
Tamar, A., Wu, Y., Thomas, G., Levine, S., and Abbeel, P. (2016). Value iteration networks. In the Annual Conference on Neural Information Processing Systems (NIPS).
Taylor, M. E. and Stone, P. (2009). Transfer learning for reinforcement learning domains: A survey. Journal of Machine Learning Research, 10:1633–1685.
Tessler, C., Givony, S., Zahavy, T., Mankowitz, D. J., and Mannor, S. (2017). A deep hierarchical approach to lifelong learning in minecraft. In the AAAI Conference on Artificial Intelligence (AAAI).
van Hasselt, H. (2010). Double Q-learning. Advances in Neural Information Processing Systems 23:, Conference on Neural Information Processing Systems 2010.
van Hasselt, H., Guez, A., , and Silver, D. (2016a). Deep reinforcement learning with double Qlearning. In the AAAI Conference on Artificial Intelligence (AAAI).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. (2017). Attention Is All You Need. ArXiv e-prints.
Vezhnevets, A. S., Mnih, V., Agapiou, J., Osindero, S., Graves, A., Vinyals, O., and Kavukcuoglu, K. (2016). Strategic attentive writer for learning macro-actions. In the Annual Conference on Neural Information Processing Systems (NIPS).
Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., and Wierstra, D. (2016). Matching networks for one shot learning. In the Annual Conference on Neural Information Processing Systems (NIPS).
Wang, J. X., Kurth-Nelson, Z., Tirumala, D., Soyer, H., Leibo, J. Z., Munos, R., Blundell, C., Kumaran, D., and Botvinick, M. (2016a). Learning to reinforcement learn. arXiv:1611.05763v1.
Wang, S. I., Liang, P., and Manning, C. D. (2016b). Learning language games through interaction. In the Association for Computational Linguistics annual meeting (ACL)
Wang, Z., Schaul, T., Hessel, M., van Hasselt, H., Lanctot, M., and de Freitas, N. (2016c). Dueling network architectures for deep reinforcement learning. In the International
Conference on Machine Learning (ICML).
Watkins, C. J. C. H. and Dayan, P. (1992). Q-learning. Machine Learning, 8:279–292
Weiss, K., Khoshgoftaar, T. M., and Wang, D. (2016). A survey of transfer learning. Journal of Big Data, 3(9)
Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3):229–256.
Xu, K., Ba, J. L., Kiros, R., Cho, K., Courville, A.,Salakhutdinov, R., Zemel, R. S., and Bengio,Y. (2015). Show, attend and tell: Neural image caption generation with visual attention. In the International Conference on Machine Learning (ICML).
Zhu, X. and Goldberg, A. B. (2009). Introduction to semi-supervised learning. Morgan & Claypool
Zoph, B. and Le, Q. V. (2017). Neural architecture search with reinforcement learning. In the International Conference on Learning Representations (ICLR)



