用声音检测技术降低美国“赌城”枪击案伤亡(paper+github)
最近几天,大家都被美国“赌城”拉斯维加斯的2000人的音乐会的枪击案刷屏,59死,500+伤,是美国自911事件后,最大的伤亡事件。默哀!祈祷和平,没有暴力!

图为:美国华盛顿纪念碑降半旗 哀悼拉斯维加斯枪案遇难者
除了默哀之外,如何用我们已有的技术,来改变这个世界,即用我们在DCASE2017 challenge中取得第一名的系统来进行声音(“枪击,gunshot”)事件检测,以便在第一时间通知就近的警察局,并且用DOA,声音能量差和相位差来辅助声音定位。
要知道现场,刚开始有人竟然误以为是“放烟花,fireworks”,而且警察花了大量时间来寻找枪击者的位置。这个枪手竟然在酒店的32层上,从高处往低处射击,扫射有2000+人的音乐现场,简直了。
我们用我们最新的声音检测技术,可以很快检测并且确定,“枪击,gunshot”:
由于现场视频太过于血腥以及版权的问题,本次就不播放视频,但贴出了“枪击”事件检测的结果图:“事件名:出现的概率”

枪手换子弹,停止射击,现场大量尖叫和语音

枪手再次射击,现场一片混乱。

枪手可能在射击n分钟后:只剩下现场一片尖叫

从现场的视频可以看出,由于昏暗的夜晚,密集的人群,光靠摄像头是无法检测枪击异常,但声音检测却能很好地预警。
论文
——
使用门控卷积神经网络的大规模弱监督音频分类

概述
——
在本文中,我们提出了一种门控卷积神经网络和音频分类的attention-based定位方法,在(DCASE )2017中声场和事件检测分类的大规模弱监控声音事件检测任务中排名第一。
从YouTube视频中提取的,此任务中的手动标记音频剪辑,有一个或几个音频标签,但没有音频事件的时间戳,这被称为弱标签数据。
在这个挑战中定义了两个子任务,包括使用弱标签数据的音频标记和声音事件检测。提出了具有可学习的门控线性单位(GLU)的非线性卷积循环神经网络(CRNN)应用于the log Mel spectrogram。
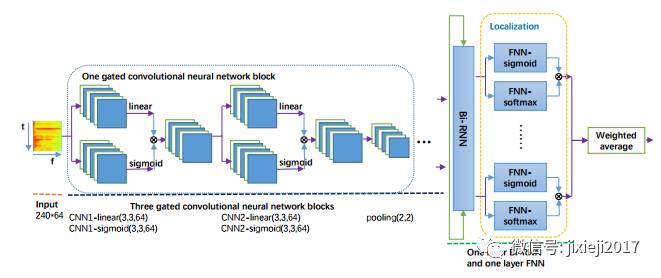
提出了音频标签和弱监听声音事件检测(SED)统一模型的图表。 从中间定位模块中提取SED预测,最终的输出是音频标签预测。

使用所提出的定位方法
预测“10i60V1RZkQ 210.000 220.000.wav”的240 frames位置的示例
结论
——
在本文中,我们提出了音频标签和弱监听声音事件检测的统一方法。 提出了门控CRNN方法,其中可学习的门控线性单元,可以帮助选择与最终标签相对应的最相关功能。
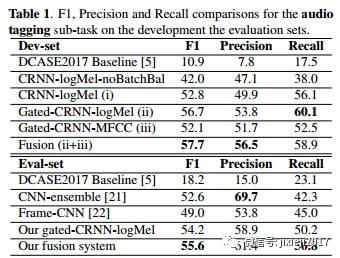
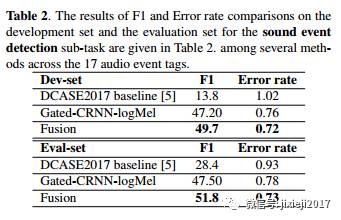
还提出了基于attention-based的定位方法,以弱监督模式定位发生的事件。 最终系统使我们在DCASE2017挑战的音频标签子任务中排名第一,获得了57.7%的F1得分。我们也是SED子任务中的第二名。 将来我们将评估我们提出的Audioset方法[20].
相关资源:
[1] 最新技术论文: https://arxiv.org/abs/1710.00343
[2] 源代码:https://github.com/yongxuUSTC/dcase2017_task4_cvssp
[3] DCASE2017 our rank 1st results:http://www.cs.tut.fi/sgn/arg/dcase2017/challenge/task-large-scale-sound-event-detection-results
来源:人工智能徐博士
获授权转载
★推荐阅读★
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang




