知识图谱嵌入的Translate模型汇总(TransE,TransH,TransR,TransD)
作者:Xu LIANG
编译:ronghuaiyang
来自:AI公园
一文打尽图嵌入Translate模型,各种模型的动机,优缺点分析。
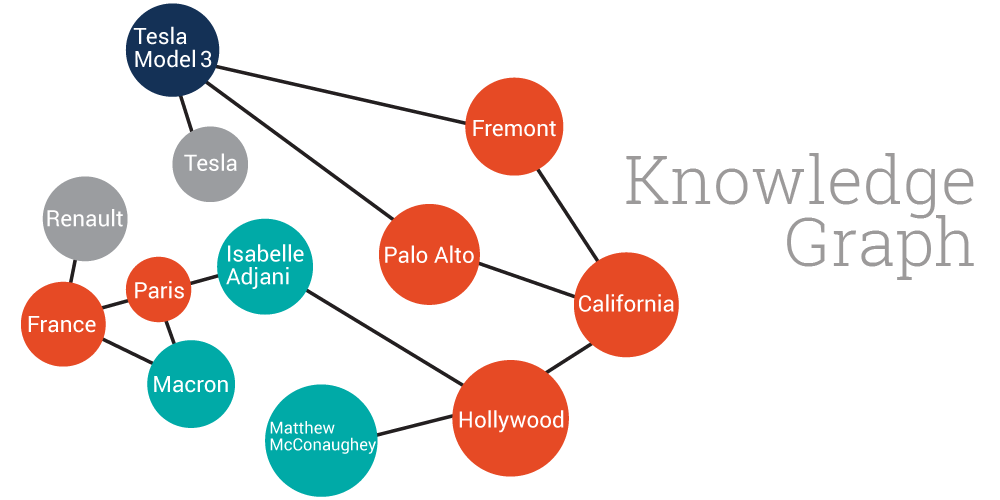
本文对知识图谱嵌入/知识表示的转换模型进行了简要的总结。你可以从TensorFlow-TransX中找到开源的TensorFlow代码。
知识表示的一些背景知识
通常,我们使用三元组(head, relation, tail)来表示知识。在这里,头和尾是实体。例如,(sky tree, location, Tokyo)。我们可以用独热向量来表示这个知识。但实体和关系太多,维度太大。当两个实体或关系很近时,独热向量无法捕捉相似度。受Wrod2Vec模型的启发,我们想用分布表示来表示实体和关系。
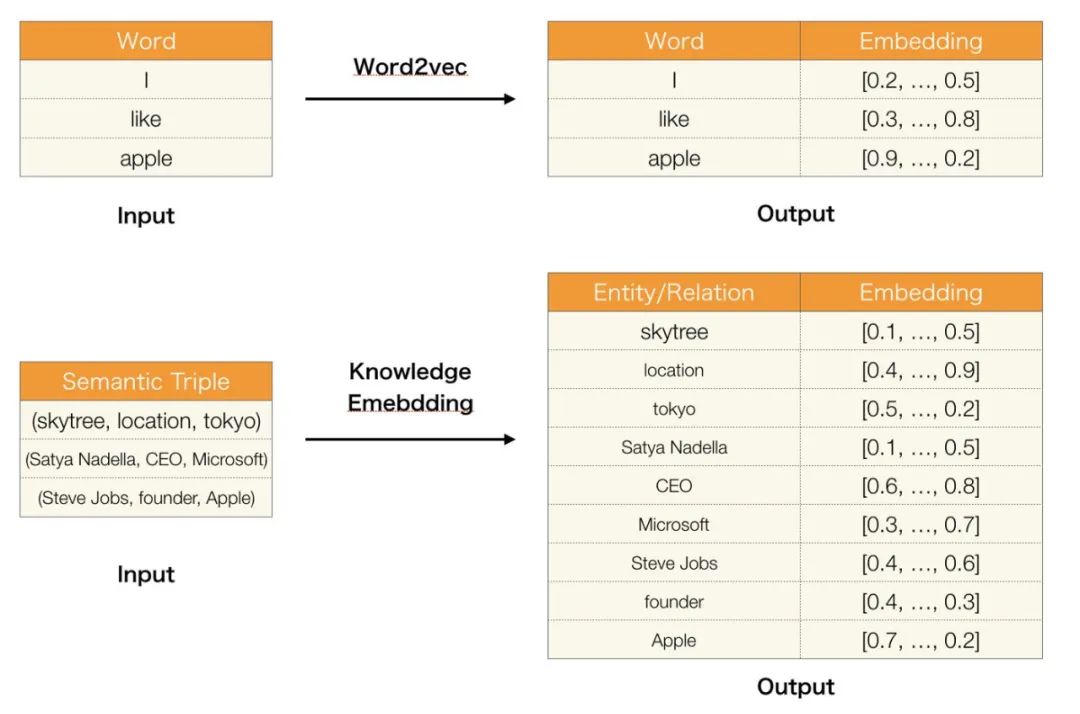
下游任务的应用
以防万一,如果你不熟悉知识图谱,我将介绍一些知识图谱可以使用的应用。
连接预测
连接预测通常被称为预测某个实体与另一个给定实体是否具有特定关系的任务。比如,给定h预测 (r,t)或者给定t预测(h, r),前者表示为(?,r,t),后者表示为(h,r,?)。例如,(?, 导演,惊魂),是预测电影的导演,(毒液,导演,?),就是预测某个电影被某个人导演。这本质上是一个知识图谱的完善的任务。
推荐系统
推荐系统为用户提供他们可能想要购买或查看的物品的一些建议。在不同的推荐策略中,协同过滤技术取得了显著的成功。但是,并不总是有效,因为用户-物品的交互可能非常稀少。在这种情况下,混合推荐系统通常可以取得更好的性能,混合推荐系统将用户-物品的交互作用与用户或物品的辅助信息相结合。
利用知识图提高协同过滤的质量。具体来说,他们使用存储在KG中的三种类型的信息,包括结构化知识(三元组)、文本知识(例如,一本书或一部电影的文本摘要)和视觉知识(例如,一本书的封面或电影的海报图像),来推导物品的语义表征。为了对结构化知识进行建模,提出了一种典型的知识图谱的嵌入技术。TransR为每个物品学习了一个结构化的表示。对于另外两种类型的信息,可以使用堆叠去噪自动编码器和堆叠的卷积自动编码器分别提取物品的文本表示和视觉表示。
也有一些应用利用到了知识图谱的嵌入,如实体解析,关系提取,问题回答等。你可以从这篇文章中找到更多的信息:Knowledge Graph Embedding: A Survey of methods and Applications(2017)。
TransE
标题:Translating Embeddings for Modeling Multi-relational Data(2013)
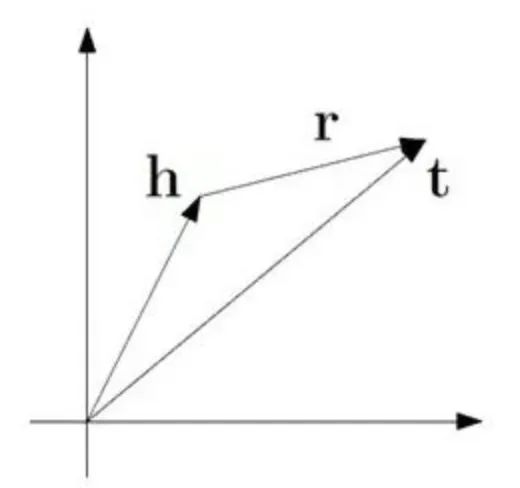
这是转换模型系列的第一部作品。该模型的基本思想是使head向量和relation向量的和尽可能靠近tail向量。这里我们用L1或L2范数来衡量它们的靠近程度。
损失函数是使用了负抽样的max-margin函数。
L(y, y’) = max(0, margin - y + y’)
y是正样本的得分,y'是负样本的得分。然后使损失函数值最小化,当这两个分数之间的差距大于margin的时候就可以了(我们会设置这个值,通常是1)。
由于我们使用距离来表示得分,所以我们在公式中加上一个减号,知识表示的损失函数为:
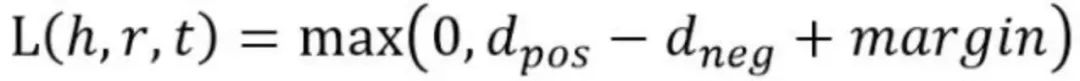
其中,d是:
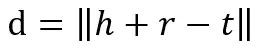
这是L1或L2范数。至于如何得到负样本,则是将head实体或tail实体替换为三元组中的随机实体。
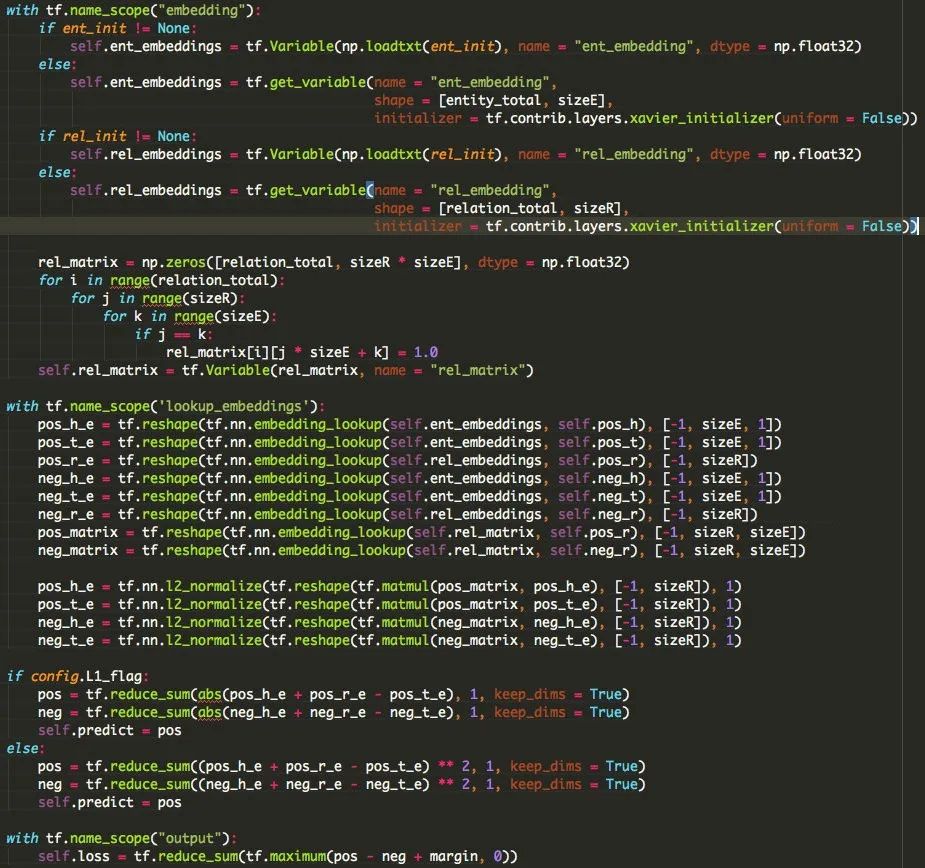
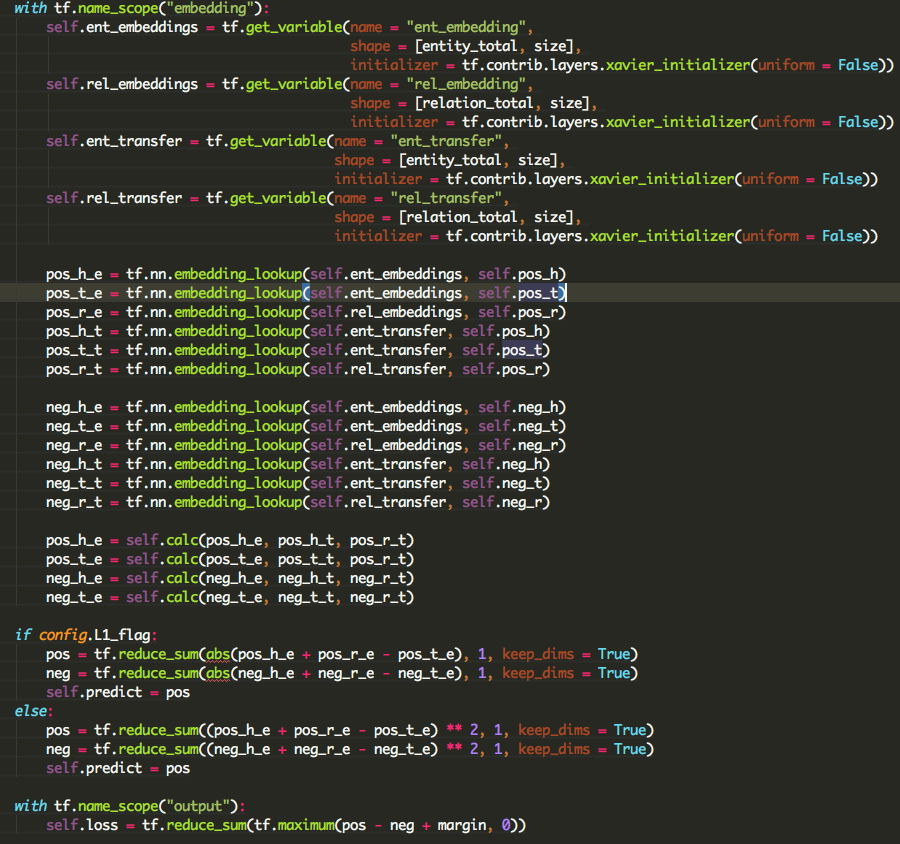
看代码:
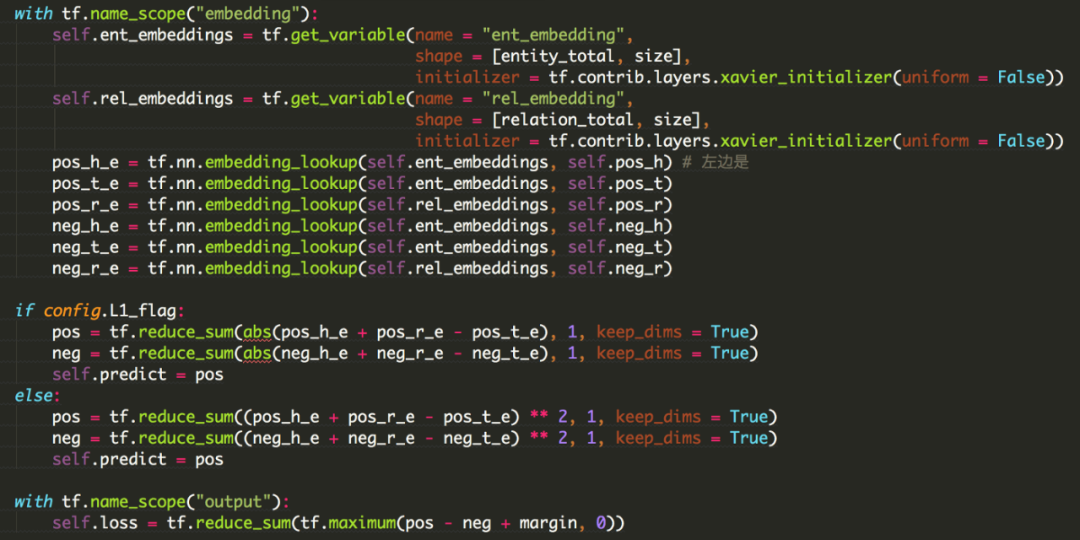
使用embedding_lookup获得head、relation、tail的向量,并计算(head、relation)和tail之间的距离。
但是这个模型只能处理一对一的关系,不适合一对多/多对一关系,例如,有两个知识,(skytree, location, tokyo)和(gundam, location, tokyo)。经过训练,“sky tree”实体向量将非常接近“gundam”实体向量。但实际上它们没有这样的相似性。
TransH
标题: Knowledge Graph Embedding by Translating on Hyperplanes(2014)
TransH的目标是处理一对多/多对一/多对多关系,并且不增加模式的复杂性和训练难度。
其基本思想是将关系解释为超平面上的转换操作。每个关系都有两个向量,超平面的范数向量Wr和超平面上的平移向量(dr)。
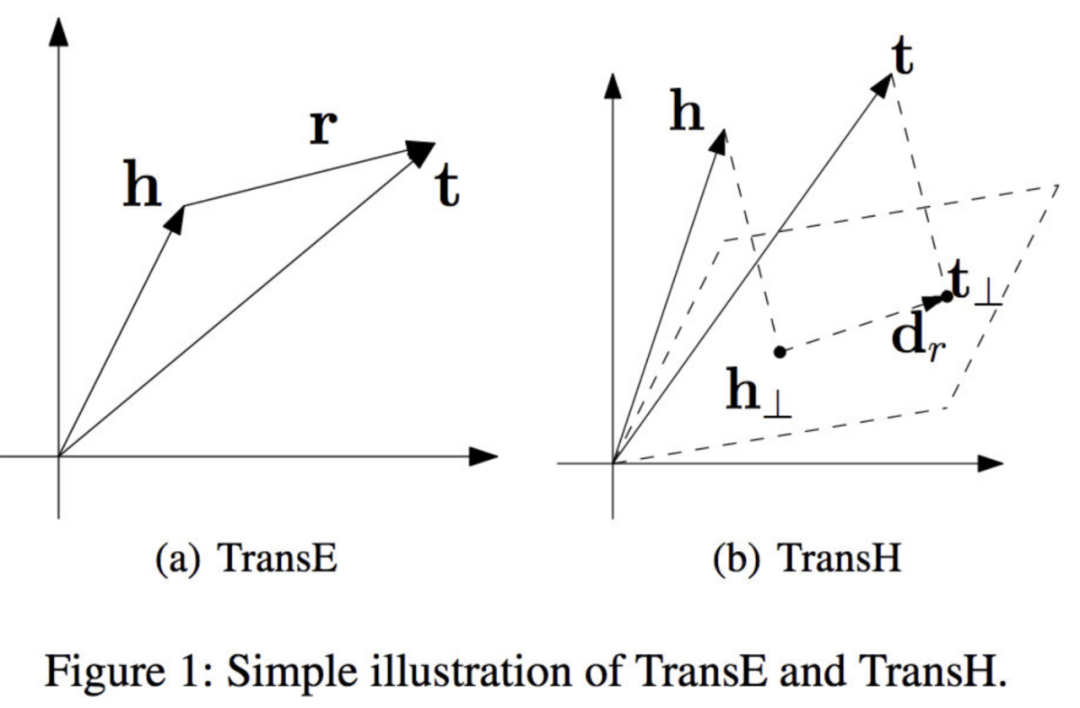
我们把每个head向量(h)和tail向量(t)投影到超平面上,得到新的向量(h⊥和t⊥)。在这个超平面中存在一个关系(d_r),我们可以像TransE模型一样训练它。
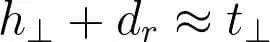
得分函数:
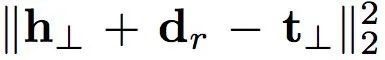
如何在超平面上计算这个投影:
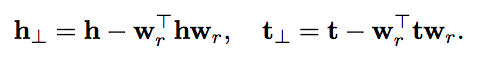
其中w_r的范数约束为1。
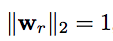
h⊥ 是h在超平面上的投影,wrT是h在wr上的投影。这意味着我们将head/tail向量分解为两部分。
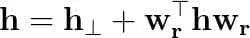
损失函数和训练方法与TransE相同。

我们把head/tail向量分解两部分,只使用一个部分(h⊥或t⊥)来训练模型。这可以避免在模型训练时两个实体(head或tail)接近,并处理一对多/多对一/多对多关系。
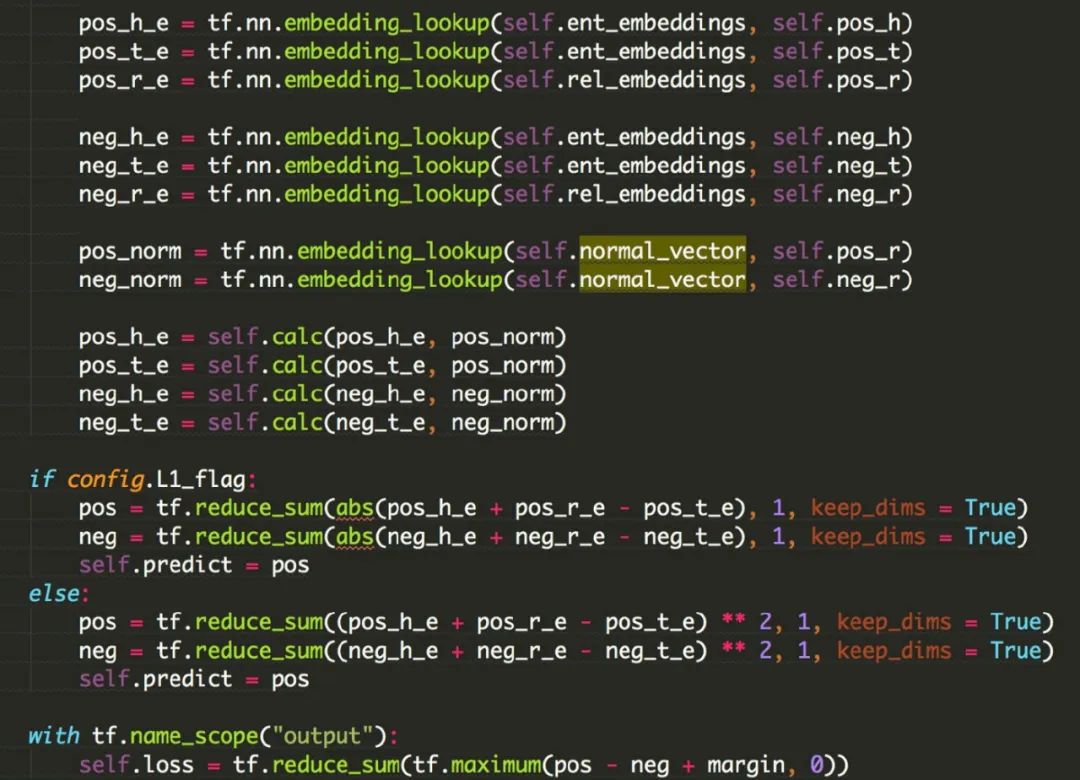

和TransE模型的代码几乎相同。唯一的区别是计算投影向量的步骤。在这一步之前,我们应该将w_r标准化为长度1。
TransR
标题: Learning Entity and Relation Embeddings for Knowledge Graph Completion(2015)
TransE和TransH模型都假设实体和关系是语义空间中的向量,因此相似的实体在同一实体空间中会非常接近。
然而,每个实体可以有许多方面,不同的关系关注实体的不同方面。例如,(location, contains, location)的关系是'contains',(person, born, date)的关系是'born'。这两种关系非常不同。
为了解决这个问题,我们让TransR在两个不同的空间,即实体空间和多个关系空间(关系特定的实体空间)中建模实体和关系,并在对应的关系空间中进行转换,因此命名为TrandR。
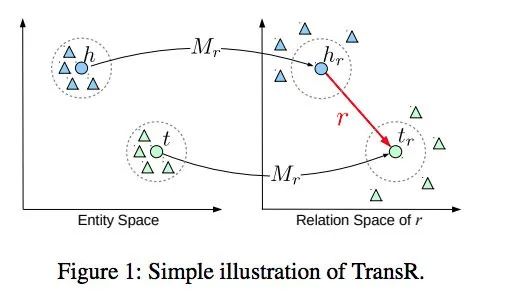
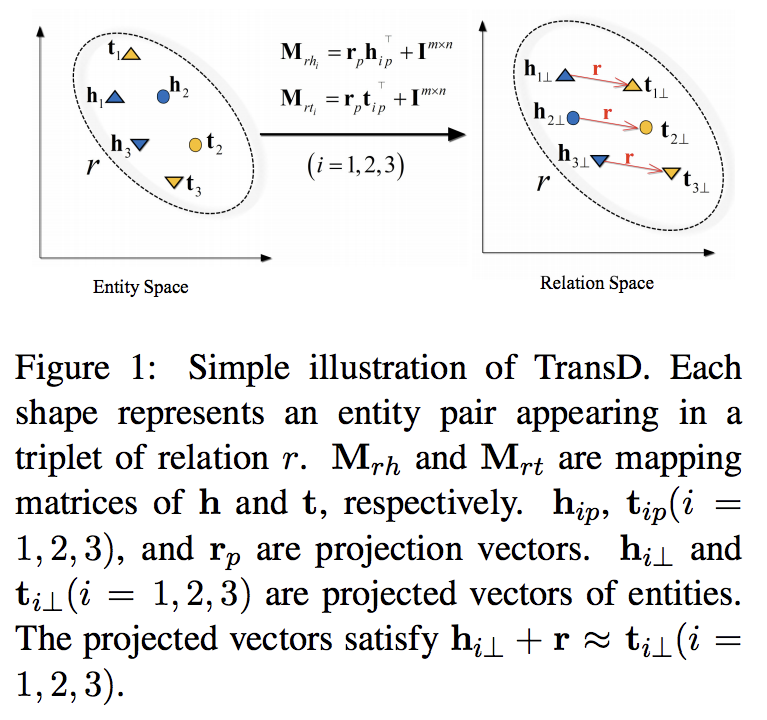
TransR的基本思想如图1所示。对于每个三元组(h, r, t),将实体空间中的实体通过矩阵Mr投影到r关系空间中,分别为hr和tr,然后有hr + r ≈ tr,损失函数和训练方法与TransE相同。h和t为实体嵌入,r为关系嵌入。
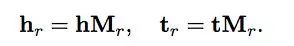
特定于关系的投影可以使实际持有这种关系的head/tail实体(表示为彩色圆圈)彼此靠近,同时那些不持有这个关系的实体相互远离(表示为彩色三角形)。
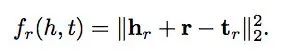
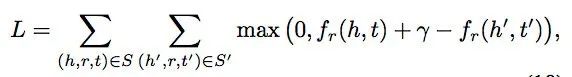
得分函数和目标函数与TransE相同。
TransR有一个变体模型,称为CTransR, C表示聚类。head和tail实体通常呈现不同的模式。仅仅构建一个关系向量来执行从head到tail实体的所有转换是不够的。例如,三元组(location, contains, location)具有许多模式,如country-city、country-university、contin- country等等。为了解决这个问题,CTransR将不同的head和tail实体对进行聚类,并对每一组学习不同的关系向量。
构造CtransR的过程是,对于一个特定的关系r,将训练数据中所有的实体对*(h, t)聚类到多个组中,期望每组中的实体对呈现相似的r关系。我们使用向量偏移量(h-t)表示实体对(h, t)*。我们从TransE得到h和t。然后,我们分别学习了每个聚类对应的关系向量r_c,每个关系对应的矩阵Mr。
当我们创建负样本时,我们只替换了head或tail,而不是relation。我们得到两个变换矩阵分别用于正样本和负样本。除了先用矩阵变换对实体向量进行转换然后计算L2范数外,其余代码基本上与TransE相同。
TransD
标题: Knowledge Graph Embedding via Dynamic Mapping Matrix(2015)
TransR也有其不足之处。
-
首先,head和tail使用相同的转换矩阵将自己投射到超平面上,但是head和tail通常是一个不同的实体,例如, (Bill Gates, founder, Microsoft)。'Bill Gate'是一个人,'Microsoft'是一个公司,这是两个不同的类别。所以他们应该以不同的方式进行转换。 -
第二,这个投影与实体和关系有关,但投影矩阵仅由关系决定。 -
最后,TransR的参数数大于TransE和TransH。由于其复杂性,TransR/CTransR难以应用于大规模知识图谱。
TransD使用两个向量来表示每个实体和关系。第一个向量表示实体或关系的意义,另一个向量(称为投影向量)将用于构造映射矩阵。
两个映射矩阵定义如下:
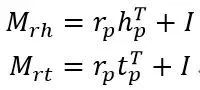
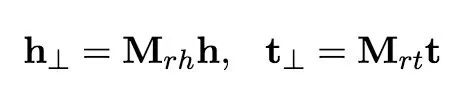
其中映射矩阵由实体和关系定义,I为单位矩阵。这个等式意味着我们使用生成的矩阵(由r和h向量)来修改单位矩阵。投射和训练与TransR相同。
TransE是向量维数满足m=n且所有投影向量都设为零时变换的一种特殊情况。

这个代码结构可能适用于其他模型。我们可以看到,每个实体和关系都由两个向量表示。但该代码没有实现实体空间维数与关系空间维数不同的情况。
模型总结


margin loss适用于所有模型。这些模型都是基于分段的,利用head向量和relation向量的和来预测tail向量。这些模型的不同之处在于它们使用不同的方法来表示实体/关系向量。
评估结果
这是数据集FB15k和WN18中各种方法的结果。
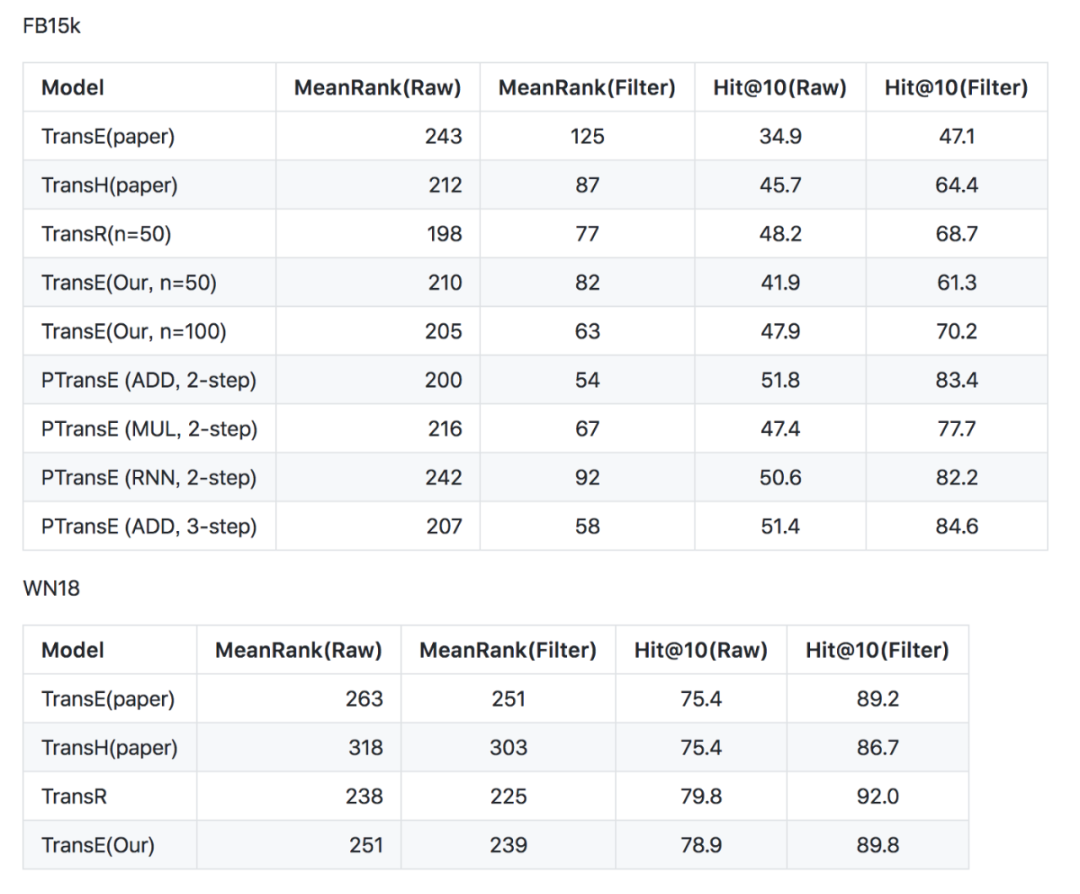
你可以找到更多关于数据集和代码的细节,使用C++实现的thunlp/KB2E,TensorFlow的版本,TensorFlow-TransX。
最后
每个模型都有自己的trick,我们不在这里讨论。
正如我在模型总结部分所说的那样。这些模型的基本思想是相同的,即利用head向量和relation向量的和来预测tail向量。向量的和就是信息的积累。但实体和关系可能比这更复杂。寻找一种更有效的方法来表达知识可能是一个具有挑战性的研究课题。

英文原文:https://towardsdatascience.com/summary-of-translate-model-for-knowledge-graph-embedding-29042be64273



