如何创建用于离线估算业务指标的测试集?(附代码&链接)

作者:AARSHAY JAIN
翻译:张若楠
校对:张玲
本文约6500字,建议阅读10+分钟
如果离线模型的离线机器学习指标(如AUC)比在线模型更好,那么是否意味着离线模型对业务更有帮助?
较高的离线机器学习指标是否意味着业务指标的提升?
离线模型的指标需要有多大提升,才值得我们将其部署成新模型或进行A / B测试?
机器学习应用尝试驱动以业务指标(例如点击率,收入,用户参与度等)进行考量的产品,依赖用户在线的反馈/互动,而这些反馈和互动难以离线评估;
机器学习模型通常与一些业务策略一起部署,这些策略会影响到模型的输出结果如何去转换为产品动作,例如在进行内容推荐时,同时考虑内容的多样性与用户具体偏好;
许多应用程序会接收来自多个模型的预测后进行判断。例如,选择展示哪个广告,可能取决于机器学习模型的点击率和需求预测,同时还要考虑一些业务限制条件,例如广告位的库存和用户匹配性。
用户方:用户访问网站并收到广告;如果用户喜欢该广告,则进行点击,反之不会点击;
业务方:机器学习系统接收挑选广告的请求,这个请求包含当前用户的上下文信息,而后选择匹配的广告进行展示。
用户意图(u):用户出于某种意图访问网站(例如,用户访问amazon.com购买鞋子);
用户上下文(x):用户开始在网站上浏览,其浏览行为被打包为上下文内容向量;
广告库存(v):可用于展示的广告位库存量;
出价(b):一种针对广告位每次点击出价的系统;
被选广告(a):根据出价和点击估算值选择的最终广告;
用户操作(y):二进制。如果用户点击了显示的广告则为1,否则为0;
收入(r):用户进行互动后产生的一定形式的收入($$)。
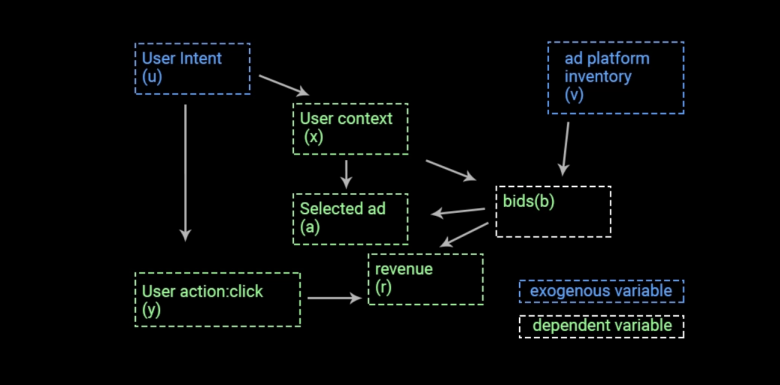
u, v 是自变量,也叫作“外生变量”
x = f(u)
b = f(x, v)
a = f(x, b)
y = f(a, u)
r = f(y, b)
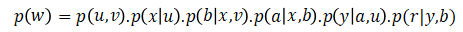
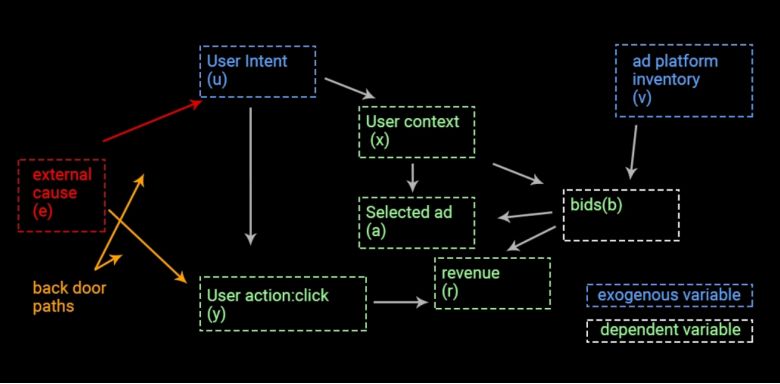
什么是反事实分析?
类比传统机器学习
马尔可夫因子置换作用于反事实分析
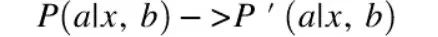
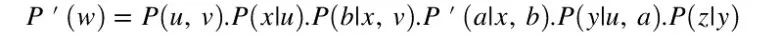

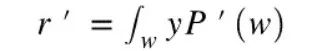
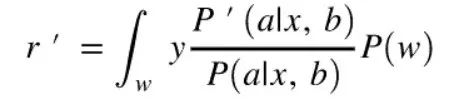
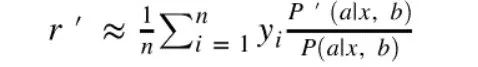
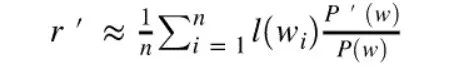
Marko因子替换的启发
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
每行数据表示一个显示广告的浏览内容上下文;
P(M)是采用线上模型M的日志中展示广告的概率;
P(M’)是采用离线模型M’展示了相同广告的概率;
y是用户操作,如果点击则为1,否则为0。
约束条件以及可实践性的考量
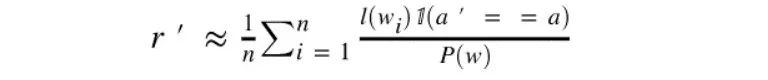
我们的清单中有3个广告,对所有用户均有效;
我们模拟了N个用户浏览上下文,即N个不同的用户场景。每个用户场景对每个广告有相互独立的点击概率;
我们通过在不同情况下向用户随机投放广告并观察点击行为来收集一些在线数据。随机投放是收集公正的在线数据以评估在线模型的好方法,应尽可能采用这一方法。
import numpy as npimport pandas as pdimport matplotlib.pylab as pltfrom uuid import uuid4%matplotlib inline
用户阅览内容
# set user contextsnum_contexts = 10000user_contexts = np.asarray(["context_{}".format(i) for i in range(num_contexts)])# assign selection prior to these contextsdef random_normal_sample_sum_to_1(size):sample = np.random.normal(0, 1, size)sample_adjusted = sample - sample.min()return sample_adjusted / sample_adjusted.sum()user_context_selection_prior = random_normal_sample_sum_to_1(num_contexts)plt.hist(user_context_selection_prior, bins=100)assert user_context_selection_prior.sum().round(2) == 1.0
不同内容下点击概率
低:10%
中:40%
高:60%
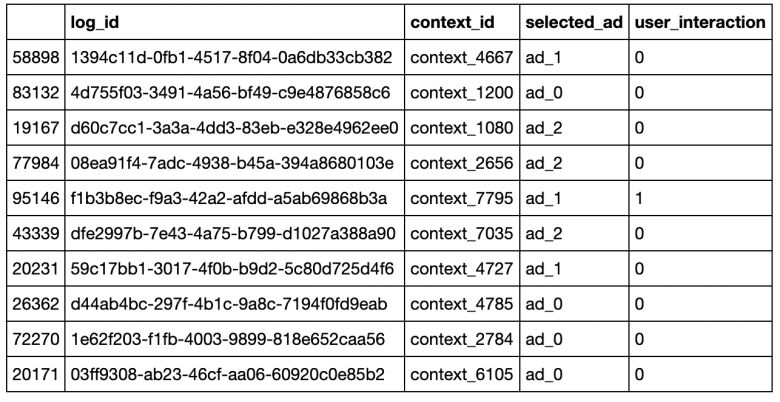
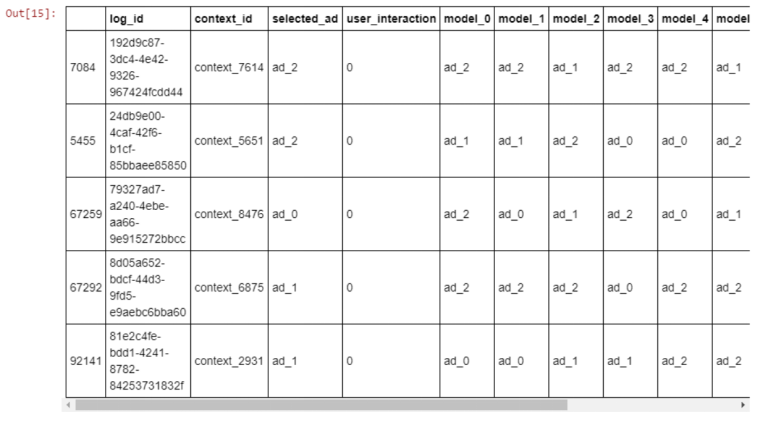
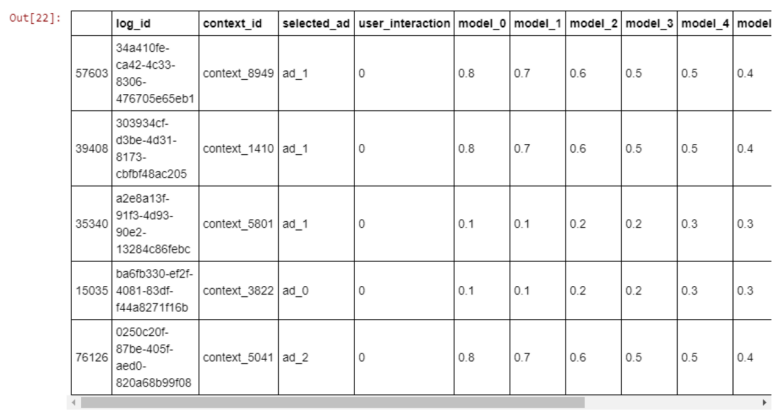
log_id:代表记录的每一行;
context_id:代表我们从10,000个内容列表中抽取的1个内容id;
selected_ad:线上模型显示的广告;
user_interaction:二进制,如果用户进行了交互,则为1;否则为0。
num_iterations = 100000# create empty df for storing logsdf_random_serving = pd.DataFrame(columns = ["log_id", "context_id", "selected_ad", "user_interaction"])# create unique ID for each log entrydf_random_serving["log_id"] = [uuid4() for _ in range(num_iterations)]# assign a context id to each log entrydf_random_serving["context_id"] = np.random.choice(user_contexts, size=num_iterations, replace=True, p=user_context_selection_prior)# randomly sample an ad to show in that contextdf_random_serving["selected_ad"] = np.random.choice(ads, size=num_iterations, replace=True)# for each log entry, sample an action or click or not using the click probability assigned to the context-ad pair in step 1def sample_action_for_ad(context_id, ad_id):prior = user_context_priors.get(context_id)[np.where(ads == ad_id)[0][0]]return np.random.binomial(1, prior)df_random_serving["user_interaction"] = df_random_serving.apply(lambda x: sample_action_for_ad(x["context_id"], x["selected_ad"]), axis=1)# a snapshot of the datadf_random_serving.sample(10)
用户出于某种意图访问了网站,并生成了由context_id表示的用户浏览内容(x);
线上模型(在这种情况下为随机选择模型)选择了要展示给用户的广告;
观察并记录了用户行为。
定义新模型
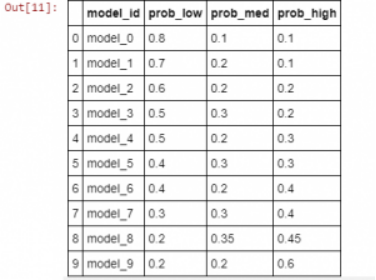
new_model_priors = np.atleast_2d([[0.8, 0.1, 0.1],[0.7, 0.2, 0.1],[0.6, 0.2, 0.2],[0.5, 0.3, 0.2],[0.5, 0.2, 0.3],[0.4, 0.3, 0.3],[0.4, 0.2, 0.4],[0.3, 0.3, 0.4],[0.2, 0.35, 0.45],[0.2, 0.2, 0.6]])
new_model_names = np.asarray(["model_{}".format(i) for i in range(new_model_priors.shape[0])])pd.DataFrame(data=np.hstack([np.atleast_2d(new_model_names).T, new_model_priors]),columns=["model_id", "prob_low", "prob_med", "prob_high"])
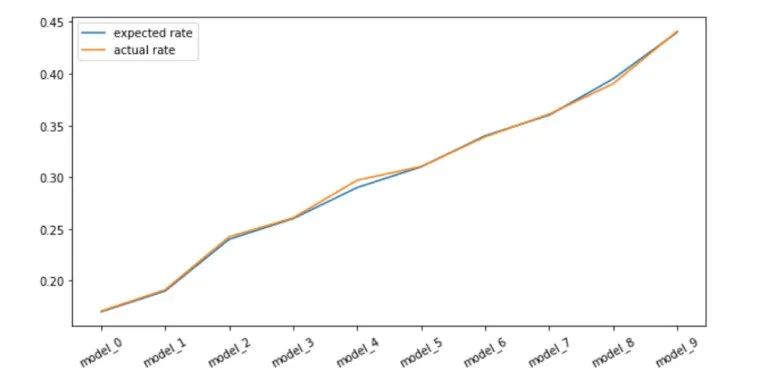
# expected interaction rate:expected_interaction_rates = np.dot(new_model_priors, np.atleast_2d(ad_interaction_priors).T)expected_interaction_rates.ravel()# Output: array([0.17 , 0.19 , 0.24 , 0.26 , 0.29 , 0.31 , 0.34 , 0.36 , 0.395, 0.44 ])
估算点击率:倾向得分匹配
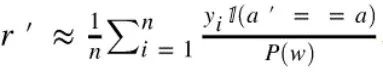
yi:用户行为;
a’:新模型产生的决策;
a:线上模型产生的决策;
P(a|x,b):线上模型在日志中的选择展示某广告的概率(注意线上模型是随机选择的)。
# use the same context ids as logged data:df_new_models_matching = df_random_serving.copy()def sample_ad_for_context_n_model(context_id, model_priors):# get ad interaction priors for the given contextinteraction_priors = user_context_priors.get(context_id)# get the selection prior for the given model based on interaction priorsselection_priors = model_priors[np.argsort(np.argsort(interaction_priors))]# select an ad using the priors and log the selection probabilityselected_ad = np.random.choice(ads, None, replace=False, p=selection_priors)# selected_ad_prior = selection_priors[ads.tolist().index(selected_ad)]return selected_adfor policy_name, model_prior in zip(new_model_names, new_model_priors):df_new_models_matching.loc[:, policy_name] = df_new_models_matching["context_id"].apply(lambda x: sample_ad_for_context_n_model(x, model_prior))df_new_models_matching.sample(5)
# match and estimate:estimates_matching = []for i in range(len(new_model_names)):model = "model_{}".format(i)matching_mask = (df_new_models_matching["selected_ad"] == df_new_models_matching[model].values).astype(int)# the logging policy was random so we know P(w) = 1/3estimate = (df_new_models_matching["user_interaction"] * matching_mask / 0.333).sum() / df_new_models_matching.shape[0]estimates_matching.append(estimate)
plt.figure(figsize=(10,5))plt.plot(expected_interaction_rates, label="expected rate")plt.xticks(range(10), labels=new_model_names, rotation=30)plt.plot(estimates_matching, label="actual rate")plt.legend()plt.show()
估算点击率:倾向得分加权
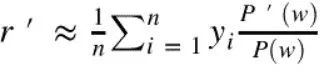
yi:用户行为;
P’(a | x, b):评估离线模型的选择概率;
P’(a | x, b):生产模型的日志概率(随机投放)。
# use the same context ids as logged data:df_new_models_weighting = df_random_serving.copy()def sample_prior_for_context_n_model(context_id, model_priors, selected_ad):# get ad interaction priors for the given contextinteraction_priors = user_context_priors.get(context_id)# get the selection prior for the given model based on interaction priorsselection_priors = model_priors[np.argsort(np.argsort(interaction_priors))]# get prior of the selected adselected_ad_prior = selection_priors[ads.tolist().index(selected_ad)]return selected_ad_priorfor model_name, model_prior in zip(new_model_names, new_model_priors):df_new_models_weighting.loc[:, model_name] = df_new_models_weighting.apply(lambda x: sample_prior_for_context_n_model(x["context_id"], model_prior, x["selected_ad"]), axis=1)df_new_models_weighting.sample(5)
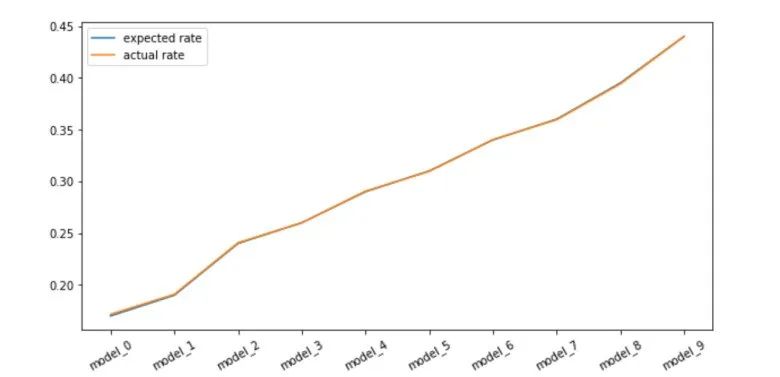
# match and estimate:estimates_weighting = []for i in range(len(new_model_names)):model = "model_{}".format(i)# the logging policy was random so we know P(w) = 1/3estimate = (df_new_models_weighting["user_interaction"] * df_new_models_weighting[model] / 0.333).sum() / df_new_models_weighting.shape[0]estimates_weighting.append(estimate)
plt.figure(figsize=(10,5))plt.plot(expected_interaction_rates, label="expected rate")plt.xticks(range(10), labels=new_model_names, rotation=30)plt.plot(estimates_weighting, label="actual rate")plt.legend()plt.show()
[1]. Counterfactual Reasoning & Learning Systems
https://arxiv.org/abs/1209.2355
[2]. Counterfactual Estimation and Optimization of Click Metrics for Search Engines
https://arxiv.org/abs/1403.1891
[3]. The Self-Normalized Estimator for Counterfactual Learning
https://papers.nips.cc/paper/5748-the-self-normalized-estimator-for-counterfactual-learning
[4]. Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms
https://arxiv.org/abs/1003.5956
[5]. Off-policy evaluation for slate recommendation
https://arxiv.org/abs/1605.04812
原文标题:
How to Create a Test Set to Approximate Business Metrics Offline
原文链接:
https://www.analyticsvidhya.com/blog/2020/02/how-to-create-test-set-approximate-business-metrics-offline/
编辑:黄继彦
校对:林亦霖
译者简介

张若楠,UIUC统计研究生毕业,南加州传媒行业data scientist。曾实习于国内外商业银行,互联网,零售行业以及食品公司,喜欢接触不同领域的数据分析与应用案例,对数据科学产品研发有很大热情。
——END——

